数据库基本概念
数据库三大部分
- 数据库
- 数据库管理系统
- 描述数据库
- 管理数据库
- 维护数据库
- 数据通信
- 数据库应用程序
数据库系统的三级结构、两级独立性
- 三级结构
- 用户级-对应外模式
- 最接近于用户的一级数据库,是用户看到和使用的数据库,又称用户视图
- 不同用户视图可以互相重叠,用户的所有操作都是针对用户视图进行
- 概念级-对应概念模式
- 介于用户级和物理级之间,是所有用户视图的最小并集
- 是数据库管理员看到和使用的数据库,又称DBA视图
- 物理级-对应内模式
- 数据库的低层表示,它描述数据的实际存贮组织
- 是最接近于物理存贮的级,又称内部视图。
- 构成:内部记录组成,物理级数据库并不是真正的物理存贮,而是是最接近于物理存贮的级
- 用户级-对应外模式
- 外模式-概念模式映射、概念模式-内模式映射
- 三个抽象级间通过两级映射(根据一定的对应规则)进行相互转换,使得数据库的三级形成一个统一整体
- 映射隔离了各层之间的相互影响,实现数据独立性
- 各层间的映射能力决定数据独立性程度
- 两级独立性
- 物理独立性
- 存在于概念模式和内模式之间的映射转换实现物理独立性
- 逻辑独立性
- 存在于外模式和概念模式之间的映射转换实现逻辑独立性
- 物理独立性
数据库应用程序的体系结构类型
- 单层
- 早期DBMS和数据库应用程序结合在同一个程序中.应用程序直接操作数据库文件
- 两层
- 将DBMS和数据库应用程序分开,在客户端上运行服务,如访问规则、业务规则、合法性校验等。每个客户端与数据库服务器建立独立连接
- 三层(多层)
- 把客户机和数据库服务分开,利用中间层的应用服务器来处理服务
关系理论1
数据三种描述形式
- 现实世界
- 信息世界-ER表示
- 机器世界-DBMS支持的数据模型
数据描述术语
- 信息世界
- 实体
- 实体集
- 属性
- 实体键
- 机器世界
- 记录
- 文件
- 字段
- 记录键
上下相应位置一一对应
实体-联系模型
E-R模型表示信息世界
E-R图中带下划线的属性为实体键或实体键的一部分。 组合属性用一个树型表示。多值属性用虚线椭圆表示或标出
数据模型
数据模型=数据组织方法+数据操作集合+数据完整性集合
数据组织方法


层次模型
层次型数据库模型采用树状结构,依据数据的不同类型,将数据分门别类,存储在不同的层次之下
网状模型
网状数据库模型将每个记录当成一个节点,节点和节点之间可以建立关联,形成一个复杂的网状结构
关系模型
二维矩阵来存储数据,行和列形成一个关联的数据表
记录和记录之间通过属性之间的关系来进行连接并形成数据集之间的关系
DBMS:
层次数据库系统
网状数据库系统
关系数据库系统
- 关系数据库的原理:关系模型和关系代数
关系数据模型
理论基础及数据结构
- 理论基础:关系理论(关系代数)
- 数据结构:二维表
定义
实体和联系均用二维表来表示的数据模型称之为关系数据模型。
概念术语
关系模式
二维表的表头那一行称为关系模式,又称表的框架或记录类型
关系数据模型是若干关系模式的集合
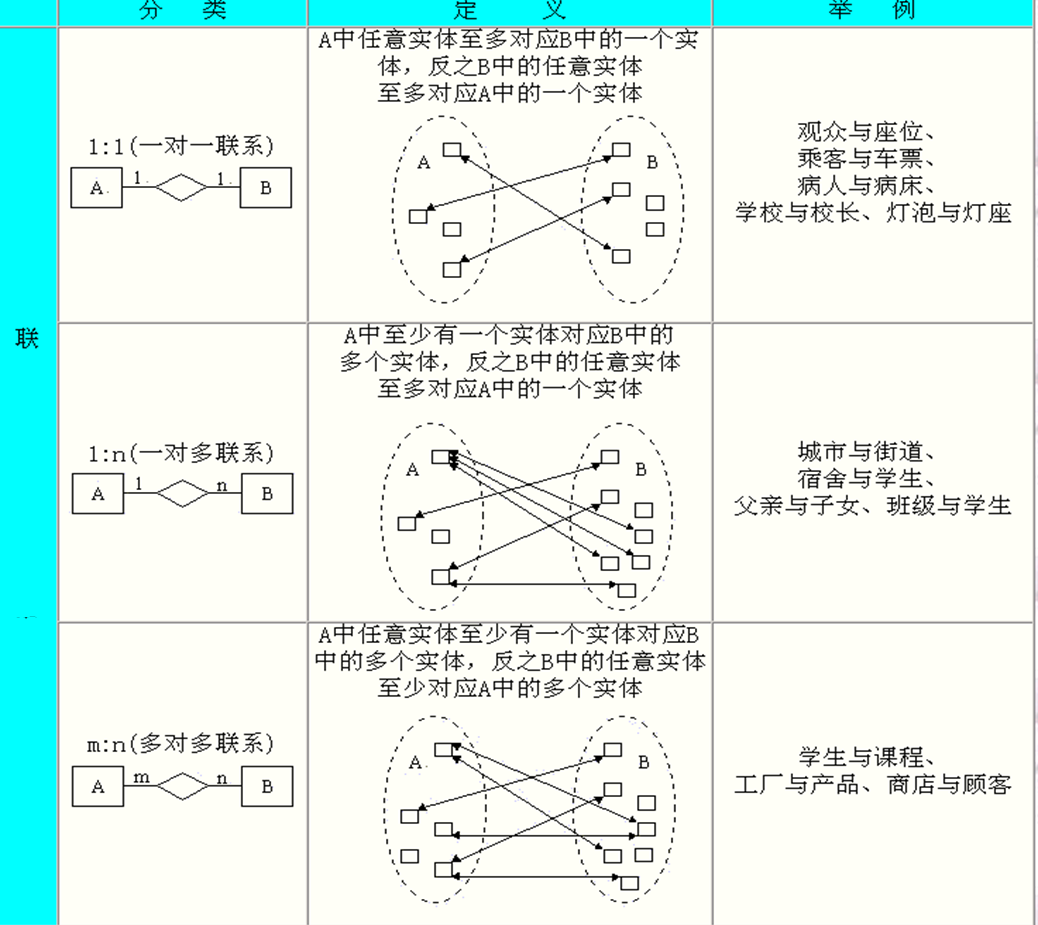
关系
对应于关系模式的一个具体的表称为关系,又称表(Table)
元组
关系中的每一行称为关系的一个元组,又称行(Row)或记录
属性
关系中的每一列称为关系的一个属性,又称列(Column)
变域
关系中的每一属性所对应的取值范围叫属性的变域,简称域
域是值的集合,关系中所有属性的实际值均来自它所对应的域
关键字
如果关系模式中的某个或某几个属性组成的属性{Ai1,Ai2,…Ain}(n>=1)能唯一地标识对应于该关系模式的关系中的任何一个元组,我们就称这样的属性组为该关系模式及其对应关系的关键字(Key)
候选关键字
如果在一个关系中,存在多个属性或属性组合都能用来唯一表示该关系的元组,这些属性或属性 组合都称为该关系的候选关键字或候选码
主关键字
若干个侯选关键字中指定作为关键字的属性或属性组合
外部关键字
当关系中的某个属性或属性组合随不是该关系的关键字或只是关键字的一部分,但却是另一个关系的关键字时,称该属性或属性组合为这个关系的外部关键字或外键
主表与从表:主表和从表是指以外键相关连的两个表,以外键作为主键的表称为主表;外键所在的表称为从表
关系数据模型完整性约束
- 域完整性
- 实体完整性
- 引用/参考完整性
- 用户自定义完整性
关系数据模型的数据操作
增删查改
E-R模型转化成关系数据模型
每个实体类型转化为一个关系模式实体类型中实体的属性转化为该关系模式的属性;实体标识符(实体键)转化为该关系模式的关键字;每一个实体转化为该关系模式对应关系的一个元组
实体类型间的每一个自身有属性的联系转化为一个关系模式。该联系的属性直接转化为该关系模式的属性,与该联系所关联的所有实体类型的实体键都转化为该关系模式的属性,共同组成该关系模式的主关键字
若联系自身无属性
对1:N型联系,则1侧实体类型的实体键转化为属性加入到N侧实体类型
对M:N型联系,则两侧实体类型的实体键都转化为属性,互相加入到对侧实体类型所转化后的关系模式中,和该关系模式的原主关键字一起,共同构成该关系模式新的主关键字;或者建立一个新关系模式,关键字是关系的双方的主键共同组成
对1:1型联系,则按1:N型联系或M:N型联系处理
关系理论2
规范化、函数依赖与范式
好的关系模式:
- 尽可能少的数据冗余
- 没有插入异常
- 没有删除异常
- 没有更新异常
函数依赖
设R(U)是属性集U上的关系模式,X与Y是U的子集,若对于R(U)的任意一个当前值r,如果对r中的任意两个元组t和s,都有t[X]≡s[X],就必须有t[Y] ≡s[Y](即若它们在X上的属性值相等,则在Y上的属性值也一定相等),则称“X”函数决定Y或“Y”函数依赖于X,记作X→Y,并称X为决定因素
- 若$X \to Y$则称X为决定因素
- 若$X \to Y,Y \to X$,则记作$X<->Y$
- 若Y不函数依赖于X
分类和键
平凡函数依赖、非平凡函数依赖
设X,Y均为某关系上的属性集,且X→Y,则Y函数依赖于X,X函数决定Y
若Y包含于X,则称X→Y为:平凡函数依赖
若Y不包含于X,则称X→Y为:非平凡函数依赖
完全函数依赖
在R(U)中,如果X→Y,并且对于X的任何一个真子集X’,其X’→ Y都不成立,则称Y对X完全函数依赖
部分函数依赖
在R(U)中,如果X→Y,X’→Y,则称Y对X部分函数依赖
传递函数依赖
设有关系模式R(U),X,Y,Z∈U,如果X→Y,Y→Z,且Y不∈X,Y不函数决定X,则有X→Z,称Z传递函数依赖于X
键
设K为R(U)中的属性或属性组合,若U函数依赖于K,则K为R的候选键(Candidate Key)。若候选键多于一个,则选定其中的一个为主键(Primary Key),也称为键(Key);当只有一个候选键时这个候选键即是主键
包含在任何一个候选键中的属性,叫主属性(Prime Attribute)。
不包含在任何主键中的属性称为非主属性(Nonprime Attribute),或非键属性(Non-key Attribute)。
范式
第一范式
关系模式R的每一个属性都是不可分解的,则称R为第一范式的模式,记为R∈1FN模式
第二范式
如果R∈1NF,且每一个非主属性完全函数依赖于主键则R∈2NF
- 从1NF关系中消除非主属性对关系键的部分函数依赖,则可得到2NF关系
- 如果R的关系键为单属性,或R的全体属性均为主属性,则R∈2NF
第三范式
如果R∈2NF,且每一个非主属性不传递函数依赖于主键,则R∈3NF
BC范式
R是一个关系模式,F是其函数依赖集合,当且仅当F中每个函数依赖的决定因素必定包含R的某个候选关键字,则R∈BCNF
范式转化
1NF(存在非主属性对主键的部分函数依赖)
I
I 消除非主属性对主键的部分函数依赖
I
v
2NF(存在非主属性对主键的传递函数依赖)
I
I 消除非主属性对主键的传递函数依赖
I
v
3NF
I
I 消除主属性对主键的部分函数依赖和传递函数依赖
I
v
BCNF
判断范式类型
第一范式:存在部分函数依赖
第二范式:
- 主键是单属性
- 不存在部分函数依赖
- 存在传递依赖
第三范式:
不是第一范式、第二范式
判断候选码
- 如果有属性不在函数依赖集中出现,那么它必须包含在候选码中
- 如果有属性只在函数依赖集的右边出现,那么它必须不在候选码中
- 如果有属性只在函数依赖集的左边出现,则该属性一定包含在候选码中
- 如果有属性或属性组能唯一标识元组,则它就是候选码;(也就是说,通过函数依赖推导出,某属性或属性组,能决定所有属性)(也就是说,通过函数依赖推导出,某属性或属性组的闭包中有所有属性)
2NF分解

3NF分解

(2)中改成3NF
求最小函数依赖集合



使用SQL server管理数据库
数据库存储结构
数据库文件
一个数据库创建在物理介质(如硬盘)的一个或多个文件上,这些文件包括数据库中的对象和数据,或者事务日志的信息
- 存储数据的文件叫数据文件
- 存储日志的文件叫日志文件
数据和日志信息不存储在同一个文件中;不同数据库的数据也不存储在同一个文件中
数据库文件满时,它们可以自动增长
SQL server中三种类型数据库文件
- 主数据库文件(.mdf)不仅包含数据库用户收集的信息,还包含了数据库中所有其他文件的有关信息
- 辅数据库文件(.ndf)
- 日志文件(.ldf)
数据库文件组
文件组就是文件的集合,把一些分别放在多个磁盘中的文件组合在一起,方便管理和数据分配,可以提高数据库性能
三种类型的文件组
- 主文件组
- 用户定义型文件组
- 缺省的文件组
建立文件组的规则
- 数据库文件不能与一个以上的文件组关联
- 文件和文件组也不能由多个数据库使用
- 日志文件不能加到文件组里。日志数据与数据库数据的管理方式不同
- 只有文件组中任何一个文件都没有空间了,文件组的文件才会自动增长
页面
SQL Server中的所有信息都存储在页面(page)上,页面是数据库中使用的最小数据单元
每一个页面存储8KB(8192字节)的信息,所有的页面都包括一个132字节的页面头,这样就留下了8060 字节存储数据
页面类型:
- 分配页面
- 数据和日志页面
- 索引页面
- 分发页面
- 文本/图像页面
盘区
盘区是表和索引等数据库对象分配空间的单位
一个盘区(extent)是由8个连续的页面(8×8KB = 64KB)组成的数据结构
当创建一个数据库对象(如一个表)时, SQL Server会自动地以盘区为单位给它分配空间
事务日志
当一个事务开始后,在任何实际数据修改前,都会在事务日志中写入一行,表明事务开始。任何改动都会被记入事务日志
系统数据库
SQL Server安装4个系统数据库。它们分别是master数据库、model数据库、tempdb数据库和msdb数据库
master数据库
控制SQL Server的所有方面。这个数据库中包括所有的配置信息、用户登录信息、当前正在服务器中运行的过程的信息
SQL Server运行时所做的第一件事就是寻找master数据库并打开它
model数据库
model数据库是建立所有用户数据库时的模板。当你建立一个新数据库时, SQL Server会把model数据库中的所有对象建立一份拷贝并移到新数据库中
对model所作的每一个动作都在新数据库中产生影响
tempdb数据库
tempdb数据库是一个非常特殊的数据库,供所有来访问你的SQL Server的用户使用。这个库用来保存所有的临时表、存储过程和其他SQL Server建立的临时用的东西
每次SQL Server重新启动,它都会清空tempdb数据库并重建。永远不要在tempdb数据库建立需要永久保存的表
msdb数据库
msdb数据库是SQL Server中的一个特例。如果你查看这个数据库的实际定义,会发现它其实是一个用户数据库。不同之处是SQL Server拿这个数据库来做什么。
所有的任务调度、报警、操作员都存储在msdb数据库中。
该库的另一个功能是用来存储所有备份历史。
SQL Server Agent将会使用这个库
用户数据库
自己建立的新数据库都是用户数据库
创建数据库
修改数据库
删除数据库
数据库的空间需求
压缩数据库
使用SQL server管理表
表的定义
表是一种二维数据对象,是列的相似数据的集合。表由行和列组成,用于存储关系数据库中的数据,是数据库中的主要对象
表中的行又叫记录,代表单个实体的有关数据的集合
表中的每行可以分成许多列。列代表记录中的一个信息片段
标识符
标识符的命名规则:
标识符的长度必须少于等于128字符。
标识符的第一个字符必须是字母(AZ、az)、_ (下划线)、@或#
当一个对象以@符号开头,意味着它是一个局部变量。
以#符号开头的对象表示它是一个局部临时表或是存储过程。
以# #开头的对象是全局临时对象
SQL Server有许多以@@开头的函数。不要用@@作为任何对象名的开头
虽然中文或其他国家语言的字符也可以作为标示符,但是不推荐这么用
跟在首字符后面的字符可以是字母(AZ、az以及其他语言的任何字母符号)、_ (下划线)、@或#,数字( 0~9以及其他语言的任何其他数字符号)、$ (美元符)、# 。
SQL Server保留字(诸如命令字)不允许用。
空格或其他特殊字符不能在标识符中使用。
数据类型
空值
默认值
主键和UNIQUE约束
强制唯一性时应用UNIQUE约束而不是主键
递增值
标识列,可以通过向列定义添加Identity属性来将某一列指定为递增值的列
一个表中只能有一个标识列,标识列可以作主键,标识列不能自己修改,标识列是非空的。可以看做一个特殊的递增的每行都不同的默认值
创建表、修改表、删除表
CHECK约束、规则
语法:名字+逻辑表达式+列名
一个列只能应用一个规则,但是却可以应用多个 CHECK 约束
外键
外键 (FK) 是用于建立和加强两个表数据之间的链接的一列或多列。通过将表中主键值和Unique约束的一列或多列添加到另一个表中,可创建两个表之间的链接。这个列就成为第二个表的外键
数据完整性
域完整性
默认值、空值、CHECK约束、规则
实体完整性
主键,UNIQUE键
参考完整性
外键
用户定义完整性
触发器、存储过程
SQL
SQL的组成
DDL
Create(Alter、Drop)数据库、表、视图、规则、存储过程、触发器等
DML
Insert,Delete,Update,Select 数据库中的信息
DCL
对各种数据库对象设置权限
ALE
SQL-SELECT
SELECT and FROM and INTO
=========================SELECT=========================
注意要用哪个数据库,要在界面上选中,这样才方便查询库中表
----------------1.SELECT and FROM 子句------------------
SELECT 子句,用来控制列,说明那些列在查询结果里面
FROM 子句,用来控制表,说明在哪个/哪些表里面查询
--*代表所有列
SELECT *
FROM titles
SELECT *
FROM publishers
SELECT *
FROM authors
SELECT *
FROM titleauthor
--控制显示的列
SELECT title, price
FROM titles
SELECT au_lname, au_fname
FROM authors
SELECT title, price, title, price, title, price
FROM titles
--列的别名
SELECT title as 'title-1', title as 'title-2', price
FROM titles
SELECT title as '书名1', title as '书名2', price as '单价'
FROM titles
--常数列
SELECT '我' as '常数列'
SELECT '我' as '常数列'
FROM titles
SELECT title, '单价是:', price
FROM titles
--运算列
SELECT title, price * 0.9 as '单价九折'
FROM titles
SELECT title, price as '原价', price * 0.9 as '九折价'
FROM titles
SELECT title, price as '原价', '九折' as '折扣力度', price * 0.9 as '折后价'
FROM titles
SELECT title, price * ytd_sales as '总销售额'
FROM titles
--列的拼接
SELECT au_lname, au_fname
FROM authors
SELECT au_lname + ' ' + au_fname as '作者姓名'
FROM authors
SELECT au_lname + ' ' + au_fname + ' 住在: ' + city as '一句话'
FROM authors
--重要语法:DISTINCT
SELECT type
FROM titles
SELECT DISTINCT type
FROM titles
SELECT DISTINCT pub_id
FROM titles
SELECT DISTINCT pub_id, type
FROM titles
--重要语法:TOP n
SELECT TOP 3 title, price
FROM titles
-------------------------2. INTO 子句---------------
INTO 子句,把一个查询结果,直接创建一个新表,存起来
SELECT TOP 3 title, price
INTO titles3rows
FROM titles
SELECT *
FROM titles3rows
WHERE
=========================SELECT=========================
----------------3.WHERE 子句------------------
WHERE 子句用来控制行,做条件判断,符合条件的就显示出来
1. =
SELECT *
FROM titles
WHERE type = 'business'
SELECT *
FROM titles
WHERE pub_id = 1389
SELECT *
FROM titles
WHERE pub_id = 1111
SELECT *
FROM titles
WHERE price = 19.99
2.<>
SELECT *
FROM titles
WHERE price <> 19.99
SELECT *
FROM titles
WHERE type <> 'business'
3. > < >= <=
SELECT *
FROM titles
WHERE price > 19
SELECT *
FROM titles
WHERE type > 'zusiness'
4. and or not 与或非
SELECT *
FROM titles
WHERE not type = 'business'
SELECT *
FROM titles
WHERE type = 'business' and price > 9
SELECT *
FROM titles
WHERE type = 'business' or type = 'mod_cook'
SELECT *
FROM titles
WHERE type = 'business' or type = 'mod_cook' and price > 19
SELECT *
FROM titles
WHERE type = 'business' or (type = 'mod_cook' and price > 19)
SELECT *
FROM titles
WHERE (type = 'business' or type = 'mod_cook') and price > 19
5. between and
SELECT *
FROM titles
WHERE price between 10 and 19
SELECT *
FROM titles
WHERE price >= 9 and price <= 19
6. is null is not null
SELECT *
FROM titles
WHERE price is null
SELECT *
FROM titles
WHERE price is not null
7.多值条件 in not in
SELECT *
FROM titles
WHERE type in ('business', 'mod_cook', 'popular_comp')
SELECT *
FROM titles
WHERE type = 'business' or type = 'mod_cook' or type = 'popular_comp'
SELECT *
FROM titles
WHERE type not in ('business', 'mod_cook', 'popular_comp')
SELECT *
FROM titles
WHERE price in (9.9, 19.99, 29.99, 10, 2.99)
8.模糊查询
8.1 like '%xxxxxxx%' 其中%叫做通配符,而且是无关长度的通配
SELECT *
FROM titles
WHERE title like '%computer%'
SELECT *
FROM titles
WHERE title like '%comp%'
SELECT *
FROM titles
WHERE title like 'comp%'
SELECT *
FROM titles
WHERE title like '%Y'
SELECT *
FROM titles
WHERE title not like '%computer%'
8.2 _ 单字符统配
SELECT au_lname, phone
FROM authors
WHERE phone like '_15%2'
SELECT au_fname, phone
FROM authors
WHERE au_fname like '_her__'
8.3 [] 区间单字符统配
SELECT au_fname, phone
FROM authors
WHERE au_fname like '[a-c]heryl'
SELECT au_fname, phone
FROM authors
WHERE au_fname like '[a-s]heryl'
SELECT au_fname, phone
FROM authors
WHERE au_fname like '[^a-c]heryl'
------------------练习--------------
查询产品类别CategoryID是2,3,4的所有产品
用多种方法来实现:OR,BETWEEN,IN,<>
USE Northwind
SELECT * FROM products
WHERE CategoryID between 2 and 4
SELECT * FROM products
WHERE CategoryID in (2,3,4)
查询产品类别是2,3,4,并且供应商SupplierID不是11的所有产品
SELECT * FROM products
WHERE CategoryID in (2,3,4) and SupplierID <> 11
查产品名ProduceName中以“C”或“D”或“E”开头的所有产品
也可以用多种方法实现,练习使用LIKE的模糊匹配
SELECT * FROM products
WHERE ProductName like '[c-e]%'
查询库存UnitsInStock<订货量UnitsOnOrder的产品,
并且在第一列添加常数“需要进货”
SELECT '需要进货' as '提醒', productname, unitsinstock, unitsonorder
FROM products
WHERE unitsinstock < unitsonorder
在上面的基础上,计算出每个产品进货的预算总额
利用表达式,计算出订货和库存的差距,并利用产品单价UnitPrice得出预算。
需要添加一个新的计算结果的列,叫做“进货预算”
SELECT '需要进货' as '提醒', productname,
unitsinstock, unitsonorder, UnitPrice,
(unitsonorder - unitsinstock)*unitprice as '进货预算'
FROM products
WHERE unitsinstock < unitsonorder
练习
查找雇员表中60年代出生在UK的员工
日期列用法例子: Birthday > ‘2000-1-1’
SELECT lastname, firstname, BirthDate, Country
FROM Employees
WHERE birthdate between '1960-1-1' and '1969-12-31'
and Country = 'UK'
聚合函数
=========================SELECT=========================
----------------聚合函数------------------
MAX 最大值
MIN 最小值
AVG 平均值
SUM 求和值
COUNT 计数
SELECT *
FROM titles
SELECT count(*)
FROM titles
SELECT count(*)
FROM titles
WHERE type = 'business'
SELECT count(*)
FROM titles
WHERE price > 100
SELECT max(price) as 'max', min(price) as 'min', avg(price) as 'avg'
FROM titles
SELECT max(price) as 'max', min(price) as 'min', avg(price) as 'avg'
FROM titles
WHERE type = 'business'
SELECT max(ytd_sales), min(ytd_sales), avg(ytd_sales)
FROM titles
SELECT count(*), sum(ytd_sales)
FROM titles
----------------GROUP BY 子句------------------
GROUP BY 子句,进行分组聚合
SELECT count(*), sum(ytd_sales), avg(price)
FROM titles
WHERE type = 'business'
SELECT count(*), sum(ytd_sales), avg(price)
FROM titles
WHERE type = 'popular_comp'
SELECT count(*), sum(ytd_sales), avg(price)
FROM titles
WHERE type = 'mod_cook'
SELECT type, count(*) as 'count', sum(ytd_sales) as 'sum', avg(price) as 'avg'
FROM titles
GROUP BY type
--消息 8120,级别 16,状态 1,第 1 行
选择列表中的列 'titles.type' 无效,因为该列没有包含在聚合函数或 GROUP BY 子句中。
!!!!!group by出现的情况下,select里面的列,要不就是出现在group by中,要不就必须在聚合函数中
SELECT type, count(*) as 'count', sum(ytd_sales) as 'sum', avg(price) as 'avg'
FROM titles
GROUP BY pub_id
SELECT pub_id, count(*) as 'count', sum(ytd_sales) as 'sum', avg(price) as 'avg'
FROM titles
GROUP BY pub_id
-------Group by 的多列,嵌套使用
SELECT type, pub_id, count(*) as 'count', sum(ytd_sales) as 'sum', avg(price) as 'avg'
FROM titles
GROUP BY type, pub_id
SELECT type, pub_id, count(*) as 'count', sum(ytd_sales) as 'sum', avg(price) as 'avg'
FROM titles
WHERE price > 20
GROUP BY type, pub_id
------------------------HAVING 子句----------------
HAVING 子句,负责对聚合函数的结果进行条件判断,符合条件的显示
SELECT type, count(*) as 'count', sum(ytd_sales) as 'sum', avg(price) as 'avg'
FROM titles
WHERE sum(ytd_sales) > 10000
GROUP BY type
--消息 147,级别 15,状态 1,第 3 行
聚合不应出现在 WHERE 子句中,
除非该聚合位于 HAVING 子句或选择列表所包含的子查询中,
并且要对其进行聚合的列是外部引用。
SELECT type, count(*) as 'count', sum(ytd_sales) as 'sum', avg(price) as 'avg'
FROM titles
GROUP BY type
HAVING sum(ytd_sales) > 10000
SELECT type, count(*) as 'count', sum(ytd_sales) as 'sum', avg(price) as 'avg'
FROM titles
GROUP BY type
HAVING sum(ytd_sales) > 10000 and avg(price) < 20
SELECT type, count(*) as 'count', sum(ytd_sales) as 'sum', avg(price) as 'avg'
FROM titles
WHERE pub_id = 1389
GROUP BY type
HAVING sum(ytd_sales) > 10000
SELECT type, count(*) as 'count', sum(ytd_sales) as 'sum', avg(price) as 'avg'
FROM titles
WHERE price < 20
GROUP BY type
HAVING sum(ytd_sales) > 10000
-----------------------------------ORDER BY-------------------------------
ORDER BY 子句,根据某列的值,对查询结果进行排序
SELECT title, price, ytd_sales
FROM titles
ORDER BY price
SELECT title, price, ytd_sales
FROM titles
ORDER BY price ASC 默认升序ASC关键词可以不写
SELECT title, price, ytd_sales
FROM titles
ORDER BY price DESC
SELECT title, price, ytd_sales
FROM titles
ORDER BY pub_id
SELECT title, price, ytd_sales
FROM titles
ORDER BY price, ytd_sales DESC
SELECT title, price, ytd_sales
FROM titles
WHERE pub_id = 1389
ORDER BY price, ytd_sales DESC
SELECT type, count(*) as 'count', sum(ytd_sales) as 'sum', avg(price) as 'avg'
FROM titles
WHERE pub_id = 1389
GROUP BY type
HAVING sum(ytd_sales) > 10000
ORDER BY avg(price) DESC
---------------
显示单价最高的10个商品
需要先按降序排列,然后取TOP 10
计算所有商品的总单价
统计类型为1的商品的个数,和总库存
在作聚合函数的时候要选择2个聚合函数,而且要添加WHERE条件
SELECT TOP 10 productname, CategoryID, unitprice
FROM products
ORDER BY unitprice DESC
SELECT SUM(unitprice)
FROM products
SELECT count(*), sum(unitsinstock)
FROM products
WHERE Categoryid = 1
统计当前有多少个供应商给我们供货
要求只显示出供应商的SupplierID就可以了
2方法,GROUP BY,DISTINCT
统计每个供应商ID提供的商品个数
按供应商ID分组,并添加聚合函数
按商品个数的升序排列刚才的结果
添加对聚合函数的结果的排序
只显示提供商品个数>3的供应商
使用Having子句
SELECT DISTINCT SupplierID
FROM products
SELECT SupplierID
FROM products
GROUP BY SupplierID
SELECT SupplierID, count(*)
FROM products
GROUP BY SupplierID
HAVING count(*) > 3
ORDER BY count(*)
多表查询
---------------------------多表查询----------------------
----------方法一:用where中=来连接两个表--------------
SELECT * FROM titles
SELECT * FROM publishers
查询这个出版社 New Moon Books 出版的所有书
SELECT * FROM publishers
WHERE pub_name = 'New Moon Books'
SELECT * FROM titles
WHERE pub_id = 0736
SELECT *
FROM titles, publishers
ORDER BY title_id
返回了144行 = 18*8
titles表里面的pub_id是外键,他来自publishers表里面的主键pub_id
SELECT title_id, title, price, titles.pub_id, publishers.pub_id, pub_name
FROM titles, publishers
ORDER BY title_id
SELECT title_id, title, price, titles.pub_id, publishers.pub_id, pub_name
FROM titles, publishers
WHERE titles.pub_id = publishers.pub_id
ORDER BY title_id
SELECT title, price, pub_name
FROM titles, publishers
WHERE titles.pub_id = publishers.pub_id
ORDER BY price
SELECT title, price, pub_name
FROM titles, publishers
WHERE titles.pub_id = publishers.pub_id
and pub_name ='New Moon Books'
ORDER BY price
SELECT * FROM Employee (job——id)
SELECT * FROM jobs (job_desc)
显示每个雇员的名字和职位描述
SELECT e.lname, j.job_desc
FROM employee as e, jobs as j
WHERE e.job_id = j.job_id
SELECT * FROM titles
SELECT * FROM authors
SELECT * FROM titleauthor
SELECT title, au_fname, au_lname, au_ord
FROM titleauthor as ta, titles as t, authors as a
WHERE ta.au_id = a.au_id and ta.title_id = t.title_id
ORDER BY title, au_ord
SELECT title, au_fname, au_lname, au_ord
FROM titleauthor as ta, titles as t, authors as a
WHERE ta.au_id = a.au_id and ta.title_id = t.title_id and a.state = 'CA'
ORDER BY title, au_ord
思考:再加一列,出版社的名字,咋办?
SELECT title, au_fname, au_lname, au_ord, pub_name
FROM titleauthor as ta, titles as t, authors as a, publishers as p
WHERE ta.au_id = a.au_id and ta.title_id = t.title_id and p.pub_id = t.pub_id
ORDER BY title, au_ord
思考: 查询,作者,和,出版社,都在同一个省的,书
SELECT title, au_fname, au_lname, au_ord, pub_name
FROM titleauthor as ta, titles as t, authors as a, publishers as p
WHERE ta.au_id = a.au_id and ta.title_id = t.title_id and p.pub_id = t.pub_id
and p.state = a.state
ORDER BY title, au_ord
----------方法二:用where中的子查询--------------
我们要查找出版过商业书籍的,出版社编号和名字
SELECT DISTINCT publishers.pub_id, publishers.pub_name
FROM titles, publishers
WHERE titles.pub_id = publishers.pub_id
and titles.type = 'business'
SELECT publishers.pub_id, publishers.pub_name
FROM titles, publishers
WHERE titles.pub_id = publishers.pub_id
and titles.type = 'business'
SELECT publishers.pub_id, publishers.pub_name
FROM publishers
WHERE publishers.pub_id in
(
SELECT pub_id FROM titles
WHERE type = 'business'
)
SELECT publishers.pub_id, publishers.pub_name
FROM publishers
WHERE publishers.pub_id in (1389,0736)
地点是加州CA的出版社,出版的书,的名字和价格
SELECT title, price
FROM titles
WHERE pub_id in (
SELECT pub_id FROM publishers
WHERE state = 'CA'
)
有两个及以上作者的,书的,名字,单价,出版社名字
SELECT t.title, t.price, p.pub_name
FROM titles as t, publishers as p
WHERE t.pub_id = p.pub_id
and title_id in
(
SELECT title_id
FROM titleauthor
GROUP BY title_id
HAVING count(*) >= 2
)
SELECT DISTINCT title_id FROM titleauthor
WHERE au_ord >= 2
SELECT title_id
FROM titleauthor
GROUP BY title_id
HAVING count(*) >= 2
找出在1996-7-1到1996-7-10期间有过销售记录的美国员工的名字
SELECT lastname, firstname FROM Employees
WHERE country = 'USA'
and EmployeeID in (
SELECT employeeID FROM orders
WHERE orderdate between '1996-7-1' and '1996-7-10')
SELECT DISTINCT lastname, firstname
FROM Employees as e, orders as o
WHERE e.EmployeeID = o.employeeID and e.country = 'USA' and
o.orderdate between '1996-7-1' and '1996-7-10'
----------方法三:联接查询--------------
SELECT * FROM titles -18行
SELECT * FROM publishers -8行
SELECT * FROM titles, publishers
order by title_id -144=18*8
交叉联接
SELECT * FROM titles, publishers
SELECT * FROM titles cross join publishers
内联接
SELECT * FROM titles as t, publishers as p
WHERE t.pub_id = p.pub_id
SELECT * FROM titles as t inner join publishers as p
on (t.pub_id = p.pub_id)
SELECT t.title, a.au_fname, a.au_fname
FROM titleauthor as ta, titles as t, authors as a
WHERE ta.au_id = a.au_id and ta.title_id = t.title_id
SELECT t.title, a.au_fname, a.au_fname
FROM titleauthor as ta inner join titles as t
on (ta.title_id = t.title_id)
inner join authors as a on (ta.au_id = a.au_id)
外联接
SELECT * FROM stores -6个书店
SELECT * FROM discounts -3种折扣,其中1种有1个商店在执行
显示打折的书店和折扣信息
SELECT * FROM stores inner join discounts
on (stores.stor_id = discounts.stor_id)
左向外联接
显示所有书店的编号和名字,如果商店有折扣在执行,则显示折扣类型
SELECT stores.stor_id, stores.stor_name, discounts.discounttype
FROM stores left outer join discounts
on (stores.stor_id = discounts.stor_id)
右向外联接
显示所有折扣类型,如果有书店在执行某个折扣类型,则显示书店名字
SELECT stores.stor_id, stores.stor_name, discounts.discounttype
FROM stores right outer join discounts
on (stores.stor_id = discounts.stor_id)
全向外联接
折扣类型和书店信息都要出来,如果某个书店正在执行某个折扣类型,则融合显示
SELECT stores.stor_id, stores.stor_name, discounts.discounttype
FROM stores full outer join discounts
on (stores.stor_id = discounts.stor_id)
内联接检索与某个出版商居住在相同州和城市的作者:
SELECT * FROM publishers
SELECT * FROM authors
SELECT a.au_fname, a.au_lname, p.pub_name
FROM authors as a inner join publishers as p
on (a.city = p.city and a.state = p.state)
与某个出版商居住在相同州和城市的作者,
若要在结果中包括所有的作者,
而不管出版商是否住在同一个城市,左向外联接
SELECT a.au_fname, a.au_lname, p.pub_name
FROM authors as a left outer join publishers as p
on (a.city = p.city and a.state = p.state)
若要在结果中包括所有作者和出版商,
而不管城市中是否有出版商或者出版商是否住在同一个城市,
请使用完整外部联接
SELECT a.au_fname, a.au_lname, p.pub_name
FROM authors as a full outer join publishers as p
on (a.city = p.city and a.state = p.state)SQL-DML
- 增:INSERT
- 删:DELETE
- 改:UPDATE
上述都是选择了某个表进行操作,实质上是对表中数据进行操作,如:
delete [表名]
where ...
insert into [表名] value(...,...,...,)
update [表名]
set ...
where ...-------------------------删除数据 DELETE--------------------
SELECT *
INTO mytitle
FROM titles
SELECT * FROM mytitle5
SELECT *
INTO mytitle5
FROM titles
DELETE mytitle
DELETE mytitle3
WHERE type = 'business'
DELETE mytitle3
WHERE price > 10
DELETE mytitle3
WHERE price is null
SELECT *
FROM mytitle4
WHERE price = (SELECT max(price) FROM mytitle4)
DELETE mytitle4
WHERE price = (SELECT max(price) FROM mytitle4)
SELECT * FROM publishers
New Moon Books
SELECT * FROM mytitle4 as t inner join publishers as p
on (t.pub_id = p.pub_id)
WHERE pub_name = 'New Moon Books'
SELECT * FROM mytitle4
WHERE pub_id in
(SELECT pub_id FROM publishers
WHERE pub_name = 'New Moon Books')
DELETE mytitle4
FROM mytitle4 as t inner join publishers as p
on (t.pub_id = p.pub_id)
WHERE pub_name = 'New Moon Books'
DELETE mytitle4
WHERE pub_id in
(SELECT pub_id FROM publishers
WHERE pub_name = 'New Moon Books')
DELETE titles
消息 547,级别 16,状态 0,第 1 行
DELETE 语句与 REFERENCE 约束
"FK__titleauth__title__1ED998B2"冲突。
该冲突发生于数据库"pubs",
表"dbo.titleauthor", column 'title_id'。
语句已终止。
DELETE titleauthor
DELETE titles
消息 547,级别 16,状态 0,第 1 行
DELETE 语句与 REFERENCE 约束
"FK__sales__title_id__24927208"冲突。
该冲突发生于数据库"pubs",表"dbo.sales", column 'title_id'。
语句已终止。
DELETE sales
DELETE titles
消息 547,级别 16,状态 0,第 1 行
DELETE 语句与 REFERENCE 约束"
FK__roysched__title___267ABA7A"冲突。
该冲突发生于数据库"pubs",表"dbo.roysched", column 'title_id'。
语句已终止。
SELECT * FROM titles
WHERE title_id not in (
SELECT DISTINCT title_id FROM roysched)
DELETE titles
WHERE title_id = 'PC9999'
--------------------------------INSERT 新增数据------------
INSERT INTO student (sid, sname, gender, old, phone)
VALUES ('10000','张三', '男', 20, '13810008888')
INSERT INTO student (sid, sname, gender, old, phone)
VALUES ('10001','李四', '女', 22, '13770008888')
INSERT INTO student (sid, sname, gender, old, phone)
VALUES ('10002','王五', '男', 21, '13313003338')
SELECT * FROM student
INSERT INTO student
VALUES ('10003','赵六', '男', 21, '13111003331')
-----
SELECT * FROM student
INSERT INTO student
VALUES ('10003','赵六', '男', 21, '13111003331')
INSERT INTO student
VALUES ('10004','赵六', '男', 21, '13111003331')
INSERT INTO student
VALUES ('10005', '钱七', '男', 21)
INSERT INTO student (sid, sname, gender, old)
VALUES ('10005', '钱七', '男', 21)
INSERT INTO student (sid, sname, gender)
VALUES ('10006', '八', '男')
INSERT INTO student (sid, sname, old)
VALUES ('10006', '八', 21)
INSERT INTO student (sid, sname, old)
VALUES ('10007', '九', '20')
------
INSERT INTO student (sid, sname, old, gender, phone)
SELECT LEFT(au_id, 5),
au_lname + ' ' + au_fname,
20,
'男',
phone
FROM authors
SELECT * FROM student
--------------------------UPDATE 更新数据-----------------
UPDATE student
SET gender = '女'
SELECT * FROM student
UPDATE student
SET gender = '男', old = old + 10
UPDATE student
SET old = 33
WHERE sname = '李四'
销量排名前十的书,全部涨价50%
UPDATE titles
SET price = price * 1.5
WHERE title_id in
(
SELECT TOP 10 title_id FROM titles
ORDER BY ytd_sales DESC
)
SELECT *
FROM publishers as p inner join titles as t
on (p.pub_id = t.pub_id)
WHERE pub_name = 'New Moon Books'
SELECT * FROM titles
WHERE pub_id in (
SELECT pub_id FROM publishers
WHERE pub_name = 'New Moon Books'
)
UPDATE titles
SET price = price * 0.8
FROM publishers as p inner join titles as t
on (p.pub_id = t.pub_id)
WHERE pub_name = 'New Moon Books'
UPDATE titles
SET price = price + 10
WHERE pub_id in (
SELECT pub_id FROM publishers
WHERE pub_name = 'New Moon Books'
)
UPDATE titles
SET title_id = 'BU2080'
WHERE title_id = 'BU2075'
UPDATE publishers
SET pub_id = '9998'
WHERE pub_id = '9999'SQL-DDL
DDL负责各类数据库对象的创建、修改、删除
如数据库、表、视图、索引、存储过程、规则等
- 创建:CREATE
- 修改:ALTER
- 删除:DROP
VIEW
一个VIEW相当于一张虚拟表
场景:
SELECT title, price, ytd_sales FROM titles
SELECT * FROM publishers
SELECT title, price, ytd_sales, pub_name
FROM titles as t inner join publishers as p on (t.pub_id = p.pub_id)
SELECT title, price, ytd_sales, pub_name
FROM titles as t inner join publishers as p on (t.pub_id = p.pub_id)
WHERE price < 10 and ytd_sales > 1000
SELECT title, price, ytd_sales, pub_name
FROM titles as t inner join publishers as p on (t.pub_id = p.pub_id)
WHERE title like '%computer%'
SELECT title, price, ytd_sales, pub_name
FROM titles as t inner join publishers as p on (t.pub_id = p.pub_id)
WHERE title like '%computer%' and price < 20
--------------------------视图------------------------
1. 用户眼中的数据(数据库、数据表),是用户视角下的数据组织形式
它和实际SQL SERVER里面的表的组织方式(ER图)不一样
这是数据库的三级结构(用户级、外模式、逻辑独立性)决定的
2. 程序员会把用户常用的一些视角,事先把select sql语句写好,存起来。
注意,存的不是数据,存的是视角(sql语句),这样方便程序员以后在这个视角下继续加条件。
综合1+2---》新概念,视图,VIEW
CREATE VIEW v_buybook
AS
SELECT title, price, ytd_sales, pub_name
FROM titles as t inner join publishers as p on (t.pub_id = p.pub_id)
SELECT * FROM v_buybook
SELECT * FROM v_buybook
WHERE title like '%computer%'
SELECT * FROM View_1
SELECT dbo.titles.title, dbo.titles.price, dbo.titles.ytd_sales, dbo.publishers.pub_name
FROM dbo.publishers INNER JOIN
dbo.titles ON dbo.publishers.pub_id = dbo.titles.pub_id
WHERE (dbo.titles.title LIKE '%computer%')
ORDER BY dbo.titles.title
SELECT TOP (100) PERCENT dbo.titles.title, dbo.titles.price, dbo.titles.ytd_sales, dbo.publishers.pub_name, dbo.authors.au_lname,
dbo.authors.au_fname
FROM dbo.publishers INNER JOIN
dbo.titles ON dbo.publishers.pub_id = dbo.titles.pub_id INNER JOIN
dbo.titleauthor ON dbo.titles.title_id = dbo.titleauthor.title_id INNER JOIN
dbo.authors ON dbo.titleauthor.au_id = dbo.authors.au_id
WHERE (dbo.titles.title LIKE '%computer%')
ORDER BY dbo.titles.title索引
采用B树结构
簇索引和非簇索引
簇索引
在叶节点中存储了表的实际行数据,所以一旦到达叶节点,数据就立刻可以使用
主键是聚簇索引的良好候选者
缺省设置创建的索引是非聚簇索引
非簇索引
非簇索引的结构类似于簇索引,但是表的数据不存储在索引的叶节点上,表的数据也不按照索引列排序
索引的唯一性
非唯一性索引效率不如唯一性效率高
唯一索引
必须在数据库表中具有唯一值特性的列上创建
唯一索引在各索引键中仅包含一行数据表中的数据
在创建主键约束和唯一约束时自动创建
非唯一索引
在叶节点中可以包含重复值,如果它们符合SELECT语句中指定的标准,那么所有重复值都可以被检索
有效使用索引
在对索引列进行查询时,不在查询where子句中显式地加入NOT词,否则无法使用索引
维护索引
查看索引状态
DBCC SHOWCONTIG重建索引
create index ... drop existing DBCC DBREINDEX整理索引碎片
DBCC INDEXDEFRAG索引统计信息
查看
DBCC SHOW_STATISTICS
索引优缺点
索引优点
- 加速数据检索
- 加速连接、order by和Group by
- 查询优化器
- 强制实施行的唯一性
索引缺点
- 基于代价
- 索引创建花费时间、空间
- 减慢了数据修改速度
适合使用索引的情况
- 主键适合簇索引
- 连接中频繁使用的列
- 列常需要排序、分组
- 查询访问较少的数据
不适合使用
- 不常在查询中引用的列
- 值少的列
- 小表
- 经常增删查改的表
- null
SQL-syntax
SELECT CEILING(3.1415926)
SELECT FLOOR(3.1415926)
SELECT SIN(3.14)
SELECT LEFT(UPPER(au_lname),1), LEFT(UPPER(au_fname),1)
FROM authors
SELECT YEAR(GETDATE())
SELECT DATEADD(dd,100, getdate())
SELECT DATEDIFF(dd, '2023-5-11', getdate())
SELECT *
FROM titles
WHERE cast(ytd_sales as varchar(10)) like '15%'
SELECT *
FROM titles
WHERE ytd_sales like '15%'
SELECT title + ' 这本书的销量是: ' + ytd_sales
FROM titles
SELECT title + ' 这本书的销量是: ' + cast(ytd_sales as varchar(10))
FROM titles
DECLARE
@myfirstvar int
SET
@myfirstvar = 10
SELECT * FROM titles
WHERE price > @myfirstvar
DECLARE
@mysecondvar varchar(100),
@mythird int
SET @mysecondvar = 'computer'
SET @mythird = 30
SELECT * FROM titles
WHERE title like '%' + @mysecondvar + '%'
and price < @mythird
DECLARE
@mycontrol int,
@myinputprice int
SET @myinputprice = -20
SET @mycontrol = (SELECT count(*) FROM titles WHERE price < @myinputprice)
IF @mycontrol > 0
BEGIN
SELECT title, price FROM titles
WHERE price < @myinputprice
END
ELSE
BEGIN
SELECT TOP 3 title, price FROM titles
ORDER BY ytd_sales DESC
ENDSQL-cursor
/*--------------------------------------------------
---游标---
关系数据库中的操作会对整个行集产生影响。
由 SELECT 语句返回的行集包括所有满足该语句 WHERE 子句中条件的行。
由语句所返回的这一完整的行集被称为结果集。
应用程序,特别是交互式联机应用程序,并不总能将整个结果集作为一个单元来有效地处理。
这些应用程序需要一种机制以便每次处理一行或一部分行。游标就是提供这种机制的结果集扩展。
-------------------------------------------------------*/
---------------------------------------------------------------------------------
--游标基本语法
---------------------------------------------------------------------------------
DECLARE Employee_Cursor CURSOR FOR
SELECT LastName, FirstName FROM Northwind.dbo.Employees
OPEN Employee_Cursor
FETCH NEXT FROM Employee_Cursor
WHILE @@FETCH_STATUS = 0
BEGIN
FETCH NEXT FROM Employee_Cursor
END
CLOSE Employee_Cursor
DEALLOCATE Employee_Cursor
---------------------------------------------------------------------------------
--游标读取行的值
---------------------------------------------------------------------------------
-- Declare the variables to store the values returned by FETCH.
DECLARE @au_lname varchar(40), @au_fname varchar(20)
DECLARE authors_cursor CURSOR FOR
SELECT au_lname, au_fname FROM authors
WHERE au_lname LIKE 'B%'
ORDER BY au_lname, au_fname
OPEN authors_cursor
-- Perform the first fetch and store the values in variables.
-- Note: The variables are in the same order as the columns
-- in the SELECT statement.
FETCH NEXT FROM authors_cursor
INTO @au_lname, @au_fname
-- Check @@FETCH_STATUS to see if there are any more rows to fetch.
WHILE @@FETCH_STATUS = 0
BEGIN
-- Concatenate and display the current values in the variables.
PRINT 'Author: ' + @au_fname + ' ' + @au_lname
-- This is executed as long as the previous fetch succeeds.
FETCH NEXT FROM authors_cursor
INTO @au_lname, @au_fname
END
CLOSE authors_cursor
DEALLOCATE authors_cursor
GO
/*---------------------------------------------------------------------------------
--查询所有商业书籍在1993年的销售量 输出2列 书名和1993年销售量
商业书 1993年销售量
------------------------------------------------------------------ -----------
Cooking with Computers: Surreptitious Balance Sheets 25
Straight Talk About Computers 15
The Busy Executive's Database Guide 15
You Can Combat Computer Stress! 35
---------------------------------------------------------------------------------*/
DECLARE
authorcursor CURSOR FOR --在所有商业书的查询结果上建立游标
SELECT title_id,title
FROM titles
WHERE type = 'business' ORDER BY title
OPEN authorcursor --打开游标
DECLARE
@Mytitle_id varchar(100), --声明一些变量存储临时结果
@Mytitle varchar(100),@SumQty int
CREATE TABLE #Tempcursor ( --创建临时表存储临时结果
[title] [varchar] (80) COLLATE Chinese_PRC_CI_AS NOT NULL ,
[sumqty] [int]) ON [PRIMARY]
FETCH NEXT FROM authorcursor --启动游标读第一条纪录,把纪录的值放入变量
INTO @Mytitle_id,@mytitle
WHILE @@FETCH_STATUS = 0 --循环读取纪录
BEGIN --对每次读取的书的编号,到另外的表中求汇总值
SET @SumQty = (SELECT Sum(qty) FROM sales WHERE title_id = @MyTitle_id AND ord_date between '1991-1-1' AND '1999-12-31')
--把每次算出的一个书的结果插入临时表
INSERT INTO #tempcursor VAlues(@Mytitle,@SumQty) --再向下读取另外一本书
FETCH NEXT FROM authorcursor INTO @Mytitle_id,@mytitle
END
CLOSE authorcursor --关闭游标
DEALLOCATE authorcursor --释放游标
--把最后所有中间算出的每本书的结果从临时表中读取出来,返回结果
Select title as '商业书', sumqty as '1993年销售量' from #tempCursor
drop table #tempcursor --删除临时表
GO
/*---------------------------------------------------------------------------------
--查询所有在美国的客户的最近一次销售纪录的总额和日期 northwind数据库
美国顾客编号 最近一次购物时间 总金额
------ ------------------------------------------------------ ---------------------
GREAL 1998-04-30 00:00:00.000 510.0000
HUNGC 1997-09-08 00:00:00.000 1701.0000
LAZYK 1997-05-22 00:00:00.000 210.0000
LETSS 1998-02-12 00:00:00.000 1450.6000
LONEP 1998-04-13 00:00:00.000 1575.0000
OLDWO 1998-04-20 00:00:00.000 554.4000
RATTC 1998-05-06 00:00:00.000 1374.6000
SAVEA 1998-05-01 00:00:00.000 4722.3000
SPLIR 1998-03-25 00:00:00.000 439.0000
THEBI 1998-04-01 00:00:00.000 69.6000
THECR 1998-04-06 00:00:00.000 326.0000
TRAIH 1998-01-08 00:00:00.000 237.9000
WHITC 1998-05-01 00:00:00.000 928.7500
----------------------------------------------------------------------------- */
Declare
@LastOrderDate datetime,
@LastOrderID int,
@LastOrderMoney money,
@TempCustomerID nchar(5)
CREATE TABLE #Tempcursor ( --创建临时表存储临时结果
[CustomerID] [nchar] (5) COLLATE Chinese_PRC_CI_AS NOT NULL ,
[OrderDate] [datetime],
[SumMoney] [money]
) ON [PRIMARY]
DECLARE Employee_Cursor CURSOR FOR
SELECT CustomerID FROM Customers WHERE Country = 'USA'
OPEN Employee_Cursor
FETCH NEXT FROM Employee_Cursor
INTO @TempCustomerID
WHILE @@FETCH_STATUS = 0
BEGIN
SET @LastOrderdate = (SELECT MAX(OrderDate) FROM Orders WHERE CustomerID = @TempCustomerID)
SET @LastOrderID = (SELECT OrderID FROM Orders WHERE OrderDate = @LastOrderDate AND CustomerID = @TempCustomerID)
SET @LastOrderMoney = (SELECT Sum(UnitPrice*Quantity) FROM [Order Details] WHERE OrderID = @LastOrderID)
Insert INTO #TempCursor
Values(@TempCustomerID,@LastOrderDate,@LastOrderMoney)
FETCH NEXT FROM Employee_Cursor INTO @TempCustomerID
END
CLOSE Employee_Cursor
DEALLOCATE Employee_Cursor
SELECT CustomerID as '美国顾客编号', OrderDate as '最近一次购物时间',SumMoney as '总金额'
FROM #TempCursor
Drop table #Tempcursor
/*-----------思考题-northwind数据库---------------------------------
国家名称 该国最受欢迎产品奖
-------------------- --------------------------------------------------------------------------------
Argentina Queso Cabrales
Austria Guaraná Fantástica
Belgium Raclette Courdavault
Brazil Camembert Pierrot
Canada Camembert Pierrot
Denmark Original Frankfurter grüne So?e
Finland Flotemysost
France Tarte au sucre
Germany Camembert Pierrot
Ireland Thüringer Rostbratwurst
Italy Mozzarella di Giovanni
Mexico Queso Cabrales
Norway Guaraná Fantástica
Poland Rh?nbr?u Klosterbier 并列第一
Poland Gorgonzola Telino 并列第一
Portugal Gnocchi di nonna Alice
Spain Alice Mutton
Sweden Zaanse koeken
Switzerland Gudbrandsdalsost
UK Gorgonzola Telino
USA Gnocchi di nonna Alice
Venezuela Outback Lager
在顾客表中统计每个国家的顾客最喜欢哪个产品
----------------------------------------------------------------*/
Create procedure p_LovestOfContry
as
DECLARE
mycursor CURSOR FOR --建立对顾客表上国家的分组的查询的游标
SELECT Country FROM Customers
GROUP BY Country
OPEN mycursor --打开游标
DECLARE
@CountryIN varchar(100), --声明一些变量存储临时结果
@ProductIDIN int,
@ProductNameIN varchar(100),
@MaxNumIN int
CREATE TABLE #Tempcursor ( --创建临时表存储临时结果
[CountryName] [varchar] (20) COLLATE Chinese_PRC_CI_AS NOT NULL ,
[ProductName] [varchar] (80)) ON [PRIMARY]
FETCH NEXT FROM mycursor INTO @CountryIN --启动游标读第一条纪录,把纪录的值放入变量
WHILE @@FETCH_STATUS = 0 --循环读取纪录
BEGIN
SELECT ProductID,sum(Quantity) as SumQuantity --统计某个国家的客户的所有定单中按产品编号分组统计总销售量
INTO #mytemp --把统计结果送入另一个临时表#mytemp,便以后继续操作
FROM [Order Details]
WHERE OrderID IN
(
SELECT OrderID --统计出某个国家的客户的所有定单编号
FROM Orders Join Customers ON Orders.CustomerID = Customers.CustomerID
WHERE Country = @CountryIN
)
Group by ProductID
ORDER by Sum(Quantity)
SET @MaxNumIn = (SELECT MAX(SumQuantity) FROM #mytemp) --从临时表#mytemp中获得某个国家客户中最大销量的产品的销量数目
--下面需要分情况讨论
--如果对应于这个最大值的@MaxNumIn只有一个产品编号,那么就找出这个产品id的名称,并且插入临时表#tempcursor一行统计结果
IF (SELECT Count(*) ProductID FROM #mytemp WHERE SumQuantity = @MaxNumIn) = 1
BEGIN
SET @ProductIDIN = (SELECT Top 1 ProductID FROM #mytemp WHERE SumQuantity = @MaxNumIn)
SET @ProductNameIN = (SELECT ProductName FROM Products WHERE ProductID = @ProductIDIN)
INSERT INTO #tempcursor VAlues(@CountryIN,@ProductNameIN)
END
--如果对应于这个最大值的@MaxNumIn有多个产品编号,那么就是销量最大的产品出现了并列第一
--那么在这多个并列第一的产品集合中,再建立另外游标,来逐个读取并列第一的产品名称,并且插入临时表#tempcursor
IF (SELECT Count(*) ProductID FROM #mytemp WHERE SumQuantity = @MaxNumIn) > 1
BEGIN
DECLARE innercursor CURSOR FOR SELECT ProductID FROM #mytemp WHERE SumQuantity = @MaxNumIn
OPEN innercursor
FETCH NEXT FROM innercursor INTO @ProductIDIN
WHILE @@FETCH_STATUS = 0
BEGIN
SET @ProductNameIN = (SELECT ProductName FROM Products WHERE ProductID = @ProductIDIN)
INSERT INTO #tempcursor VAlues(@CountryIN,@ProductNameIN + ' 并列第一')
FETCH NEXT FROM innercursor INTO @ProductIDIN
END
CLOSE innercursor
DEALLOCATE innercursor
END
DROP TABLE #mytemp --删除这个mytemp临时表
FETCH NEXT FROM mycursor INTO @CountryIN --进入下一个循环
END
CLOSE mycursor --关闭游标
DEALLOCATE mycursor --释放游标
SELECT CountryName as '国家名称', ProductName as '该国最受欢迎产品奖' from #tempCursor
DROP TABLE #tempcursor --删除结果集合的临时表
--运行实例
EXEC p_LovestOfContry
Stored Procedures
---------------------------存储过程------------------------
SELECT t.title, t.price, p.pub_name
FROM titles as t inner join publishers as p on (t.pub_id = p.pub_id)
CREATE VIEW vtttt
AS
SELECT t.title, t.price, p.pub_name
FROM titles as t inner join publishers as p on (t.pub_id = p.pub_id)
SELECT * FROM vtttt
WHERE title like '%computer%'
DECLARE
@myinputtitlename varchar(100)
SET @myinputtitlename = 'computer'
SELECT * FROM vtttt
WHERE title like '%' + @myinputtitlename + '%'
CREATE PROCEDURE p_first
@myinputtitlename varchar(100)
AS
BEGIN
SELECT t.title, t.price, p.pub_name
FROM titles as t inner join publishers as p on (t.pub_id = p.pub_id)
WHERE title like '%' + @myinputtitlename + '%'
END
EXEC p_first 't'
--输入一个作者名字,得到这个作者的写的书,单价,出版社
ALTER PROCEDURE p_second
@myinputauthorname varchar(100)
AS
BEGIN
SELECT dbo.titles.title, dbo.titles.price, dbo.publishers.pub_name
FROM dbo.titleauthor INNER JOIN
dbo.titles ON dbo.titleauthor.title_id = dbo.titles.title_id INNER JOIN
dbo.publishers ON dbo.titles.pub_id = dbo.publishers.pub_id INNER JOIN
dbo.authors ON dbo.titleauthor.au_id = dbo.authors.au_id
WHERE authors.au_fname like '%' + @myinputauthorname + '%'
or authors.au_fname like '%' + @myinputauthorname + '%'
END
EXEC p_second 'Sher'
多个参数
输出参数(返回值)
流程控制
变量定义
输入一个开始时间,一个结束时间
返回这个阶段的书的销售记录,包括;书名字,日期,卖出去数量
SELECT title,ord_date,qty FROM Sales inner join titles on (sales.title_id = titles.title_id)
WHERE ord_date between '1994-9-1' and '1994-10-1'
-2个变量
CREATE PROCEDURE p_third
@inputbegin datetime,
@inputend datetime
AS
BEGIN
SELECT title,ord_date,qty FROM Sales inner join titles
on (sales.title_id = titles.title_id)
WHERE ord_date between @inputbegin and @inputend
END
EXEC p_third '1994-9-1', '1994-10-1'
-默认值
Alter PROCEDURE p_third
@inputbegin datetime = '1994-9-1',
@inputend datetime = '1994-10-1'
AS
BEGIN
SELECT title,ord_date,qty FROM Sales inner join titles
on (sales.title_id = titles.title_id)
WHERE ord_date between @inputbegin and @inputend
END
EXEC p_third '1994-9-14', '1994-11-1'
-流程控制,变量控制 如果没有,就返回最近3条
Alter PROCEDURE p_third
@inputbegin datetime = '1994-9-1',
@inputend datetime = '1994-10-1'
AS
BEGIN
DECLARE @mycontrol int
SET @mycontrol = (SELECT count(*) FROM sales WHERE ord_date between @inputbegin and @inputend)
IF @mycontrol > 0
BEGIN
SELECT title,ord_date,qty FROM Sales inner join titles
on (sales.title_id = titles.title_id)
WHERE ord_date between @inputbegin and @inputend
END
ELSE
BEGIN
SELECT TOP 3 title,ord_date,qty FROM Sales inner join titles
on (sales.title_id = titles.title_id)
ORDER BY ord_date DESC
END
END
EXEC p_third '1994-10-14', '1994-11-1'
--上面查询继续,增加内容:请同时返回本次查询的结果的记录条数+总销售本书
Alter PROCEDURE p_third
@inputbegin datetime = '1994-9-1',
@inputend datetime = '1994-10-1',
@outputcount int OUTPUT,
@outputsum int OUTPUT
AS
BEGIN
DECLARE @mycontrol int
SET @mycontrol = (SELECT count(*) FROM sales WHERE ord_date between @inputbegin and @inputend)
SET @outputcount = (SELECT count(*) FROM sales WHERE ord_date between @inputbegin and @inputend)
SET @outputsum = (SELECT sum(qty) FROM sales WHERE ord_date between @inputbegin and @inputend)
IF @mycontrol > 0
BEGIN
SELECT title,ord_date,qty FROM Sales inner join titles
on (sales.title_id = titles.title_id)
WHERE ord_date between @inputbegin and @inputend
END
ELSE
BEGIN
SELECT TOP 3 title,ord_date,qty FROM Sales inner join titles
on (sales.title_id = titles.title_id)
ORDER BY ord_date DESC
SET @outputcount = 3
SET @outputsum = -1
END
END
---
DECLARE
@getoutputcount int,
@getoutputsum int
EXEC p_third '1994-9-20', '1994-10-1', @getoutputcount OUTPUT, @getoutputsum OUTPUT
SELECT @getoutputcount, @getoutputsum
-输入作者姓名,返回这个作者写的书的书名字,出版社,单价,销量
同时要能知道,这个作者写了几本书,总销量是多少
如果没有找到作者,返回销量最高的3本书Triggers
---------------------------------------------------------------------------
--触发器的基本语法
---------------------------------------------------------------------------
CREATE TRIGGER <trigger_name, sysname, trig_test>
ON <table_name, sysname, pubs.dbo.sales>
FOR DELETE, INSERT, UPDATE
AS
BEGIN
RAISERROR (50009, 16, 10)
END
--------------------------------------------------------------------------
--简单的删除触发器
--------------------------------------------------------------------------
--建立一个简单的和其他表没有任何关系的表,避免删除时和其他表的联系
SELECT *
INTO AAA
FROM Title
create trigger t_DelAAADoSomething
ON AAA
FOR Delete
AS
print('Just Now You Del a Recorder of AAA table')
--运行删除语句就会激发上面这个触发器(输出一次print,影响1行)
delete aaa
where title_id = 'bu1032'
--运行删除语句就会激发上面这个触发器(输出一次print,影响17行)
delete aaa
--还原aaa表数据
insert into aaa
select * from titles
create trigger t_DelAAADoSomethingAndDoAgain
ON aaa
FOR Delete
AS
print('Just now you run del and run t_DelaaaDoSomethingAndDoAgain')
--运行删除语句就会激发上面这二个触发器
delete aaa
where title_id = 'bu1032'
/*
Just Now You Del a Recorder of AAA table
Just now you run del and run t_DelaaaDoSomethingAndDoAgain
(所影响的行数为 1 行)
*/
delete aaa
/*
Just Now You Del a Recorder of AAA table
Just now you run del and run t_DelaaaDoSomethingAndDoAgain
(所影响的行数为 17 行)
*/
--------------------------------------------------------------------------
--简单的更新和插入触发器
--------------------------------------------------------------------------
create trigger t_UpdateAAADosomthing
ON aaa
FOR Update,Insert
AS
print('Just now you Update or insert aaa table')
--还原aaa表数据
insert into aaa
select * from titles
--执行一行更新语句
update aaa
set price = price + 0.1
/*
Just now you Update or insert aaa table
(所影响的行数为 18 行)
*/
--------------------------------------------------------------------------
--从临时删除表中读取刚才删除的纪录信息 SELECT title FROM deleted
--每当对某个表执行delete时都会生成和某个表结构一样的一个临时表deleted
--每当对某个表执行update,insert时都会生成和某个表结构一样的一个临时表inserted
--可以利用这二个临时表来活动最近一次delete,insert,update的数据
--------------------------------------------------------------------------
create trigger t_DelAAADoDetail
ON AAA
FOR Delete
AS
print('Just Now You Del a Recorder of AAA table')
Declare
@title varchar(80)
SET @title = (SELECT title FROM deleted)
PRINT '" ' + @title + ' " : is your just del book name '
--删除一行纪录
delete aaa
where title_id = 'PC1035'
/*
Just Now You Del a Recorder of AAA table
Just now you run del and run t_DelaaaDoSomethingAndDoAgain
Just Now You Del a Recorder of AAA table
(所影响的行数为 1 行)
" But Is It User Friendly? " : is your just del book name
*/
--删除多行纪录,有问题,游标
delete aaa
where type = 'business'
/*
Just Now You Del a Recorder of AAA table
Just now you run del and run t_DelaaaDoSomethingAndDoAgain
Just Now You Del a Recorder of AAA table
服务器: 消息 512,级别 16,状态 1,过程 t_DelAAADoDetail,行 10
子查询返回的值多于一个。当子查询跟随在 =、!=、<、<=、>、>= 之后,或子查询用作表达式时,这种情况是不允许的。
语句已终止。
*/
--------------------------------------------------------------------------
--每次添加一本书的销售纪录就要修改这本书的总销量
--------------------------------------------------------------------------
CREATE trigger t_AddSalesANDAddYtd_Sales
ON Sales
FOR Insert
AS
declare
@NewYtdSales int,
@NewSalesTitleID varchar(30)
SET @NewYtdSales = (SELECT qty FROM Inserted)
SET @NewSalesTitleID = (SELECT title_id From INSERTED)
UPDATE Titles
SET Ytd_Sales = Ytd_Sales + @NewYtdSales
WHERE title_id = @NewSalesTitleID
INSERT sales
Values(6380,23456,'1999-1-1',1000,'Net 60','BU1032')
/*--------------------------------------------------------------------------
--察看触发器的方法:
触发器总是和表相关联的
在企业管理器中选中一个表,从右键菜单的所有任务中选择“管理触发器”
--通过修改表的性质 允许和禁止触发器
--------------------------------------------------------------------------*/
use pubs
ALTER TABLE employee
DISABLE Trigger employee_insupd
ALTER TABLE employee
ENABLE Trigger employee_insupd
--------------------------------------------------------------------------
--练习
--每次添加一本书的销售纪录就要给写书的作者1元钱的版权费
--------------------------------------------------------------------------
CREATE trigger t_AddSalesANDAddRoyaltyper
ON Sales
FOR Insert
AS
declare
@NewYtdSales int,
@NewSalesTitleID varchar(30)
SET @NewYtdSales = (SELECT qty FROM Inserted)
SET @NewSalesTitleID = (SELECT title_id From INSERTED)
UPDATE TitleAuthor
SET royaltyper = royaltyper + @NewYtdSales
WHERE title_id = @NewSalesTitleID
INSERT sales
Values(6380,2349,'1999-1-1',1000,'Net 60','TC7777')
--------------------------------------------------------------------------
--附加练习(SQL Server的pubs数据库自带例子)(带逻辑、带错误检验、带事务控制)
--添加一个雇员的时候使用触发器控制用户录入的雇员的job_lvl必须在max_lvl与min_lvl中间
--------------------------------------------------------------------------
drop trigger employee_insupd
CREATE TRIGGER employee_insupd
ON employee
FOR insert
AS
--声明变量.
declare @min_lvl tinyint,
@max_lvl tinyint,
@emp_lvl tinyint,
@job_id smallint
--为变量赋值,就是刚才获取insert的这个雇员,用户输入的信息
select @min_lvl = min_lvl,
@max_lvl = max_lvl,
@emp_lvl = i.job_lvl,
@job_id = i.job_id
from employee e, jobs j, inserted i
where e.emp_id = i.emp_id AND i.job_id = j.job_id
--使用Raiserror,发出错误信息,放弃本次添加,就是回滚事物,本次添加无效
IF NOT (@emp_lvl BETWEEN @min_lvl AND @max_lvl)
begin
raiserror ('The level for job_id:%d should be between %d and %d.',
16, 1, @job_id, @min_lvl, @max_lvl)
ROLLBACK TRANSACTION
end
--不发出错误信息,直接把用户错误的输入纠正为最大值或最小值
CREATE trigger t_AddSalesCheckJob_lvl
ON employee
FOR Insert
AS
declare
@job_id int,
@job_lvl int,
@emp_id empid,
@min_lvl int,
@max_lvl int
SET @job_id = (SELECT job_id FROM INSERTED)
SET @job_lvl = (SELECT job_lvl FROM INSERTED)
SET @emp_id = (SELECT emp_id FROM INSERTED)
SET @Min_lvl = (SELECT min_lvl FROM jobs WHERE job_id = @job_id)
SET @Max_lvl = (SELECT max_lvl FROM jobs WHERE job_id = @job_id)
If @job_lvl <@Min_lvl
BEGIN
UPDATE employee
SET job_lvl = @Min_lvl
WHERE emp_id = @emp_id
END
If @job_lvl >@Max_lvl
BEGIN
UPDATE employee
SET job_lvl = @Man_lvl
WHERE emp_id = @emp_id
END
INSERT employee
Values('PPP42628F','aaa','M','bbb',13,1,'0877','1992-1-1')
-- =============================================
-- 使用存在检测功能
-- =============================================
IF EXISTS (SELECT name
FROM sysobjects
WHERE name = 'aaabbb'
AND type = 'P')
DROP PROCEDURE [dbo].[aaabbb]
GO
IF EXISTS (SELECT name
FROM sysobjects
WHERE name = N'<trigger_name, sysname, trig_test>'
AND type = 'TR')
DROP TRIGGER <trigger_name, sysname, trig_test>
GO
IF EXISTS (SELECT name
FROM sysobjects
WHERE name = N'<procedure_name, sysname, proc_test>'
AND type = 'P')
DROP PROCEDURE <procedure_name, sysname, proc_test>
GO
IF EXISTS(SELECT name
FROM sysobjects
WHERE name = N'<table_name, sysname, test_table>'
AND type = 'U')
DROP TABLE <table_name, sysname, test_table>
GO
USE pubs
IF EXISTS (SELECT name FROM sysobjects
WHERE name = 'au_info2' AND type = 'P')
DROP PROCEDURE au_info2
GO
USE pubs
IF EXISTS (SELECT name FROM sysobjects
WHERE name = 'reminder' AND type = 'TR')
DROP TRIGGER reminder
GO关系代数
关系代数运算符
集合运算符
并、差、交、广义笛卡尔积
专门的关系运算符
选择、投影、连接、除
算术比较符
逻辑运算符
专门的关系运算
选择
类似于SELECT*-WHERE
$\sigma_F(R),其中F是选择运算符,是一个逻辑表达式$
如:$\sigma_{Sdept=’IS’}(Student)$
投影
类似于SELECT…FROM
$\Pi_A(R),其中A是R中的属性列$
投影之后取消了原关系中的某些列,还取消某些元组(去重)
如:$\Pi_{Sname,Sdept}(Student)$
连接
$R \infty_{A \theta B} S$
其中A和B分别为R和S上度数相等且可比的属性组,θ为比较运算符 。连接运算从R和S的广义笛卡尔积R×S中选取R关系在A属性组上的值与S关系在B属性组上值满足比较关系的元组
等值连接
$R \infty_{A = B} S$
自然连接
$R \infty S$
是一种特殊的等值连接,要求两个关系中进行比较的分量必须是相同的属性组,在结果中把重复的属性列去掉
除
给定关系R(X,Y) 和S(Y,Z),其中X,Y,Z为属性组。R中的Y与S中的Y可以有不同的属性名,但必须出自相同的域集。R与S的除运算得到一个新的关系P(X),P是R中满足下列条件的元组在X属性列上的投影:元组在X上分量值x的象集Yx包含S在Y上投影的集合。
数据库可靠性
备份和恢复
完整数据库备份
差异备份
备份自上一次完整数据库备份后修改过的数据库页
事务日志备份
备份事务日志
文件或文件组备份
还原数据库的一般顺序为:
1、还原最新的数据库备份。
2、还原最后一次的差异数据库备份。
3、还原最后一次差异数据库备份后创建的所有事务日志备份。
事务控制
事务ACID特性:
- 原子性
- 一致性
- 隔离性
- 持续性
并发控制
基于锁的事务并发控制
并发操作带来的数据不一致性:
丢失修改
两事务都修改了数据
不可重复读
一事务的写撤销造成另一事务的读前后不一样
读脏数据
一事务的写撤销造成两事务的读数据不一致
锁特点:多粒度
锁定:行锁定、列锁定、表锁定、数据库锁定
- 细粒度的锁定(比如只锁定一行)可以增加系统的并发度,但对多行的锁定却增加了开销
- 粗粒度的锁定(比如锁定整个表)降低了总开销,但也大大降低了系统的并发度
数据库的安全性
数据库安全性控制的常用方法
- 用户标识和鉴定
- 存取控制、审计、视图
- 操作系统安全保护
- 密码存储
数据库的完整性
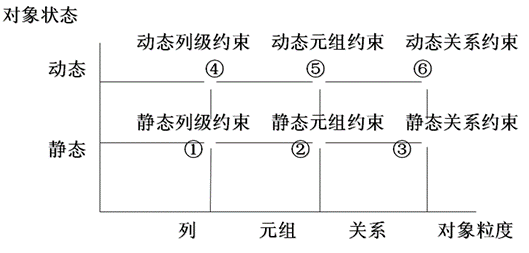
| 粒 度 状态 | 列 级 | 元 组 级 | 关 系 级 |
|---|---|---|---|
| 静 态 | 列定义 ·****类型 ·****格式 ·****值域 ·****空值 | 元组值应满足的条件 | 实体完整性约束 参照完整性约束 函数依赖约束 统计约束 |
| 动 态 | 改变列定义或列值 | 元组新旧值之间应满足的约束条件 | 关系新旧状态间应满足的约束条件 |
- 域完整性
- 实体完整性
- 参考完整性
- 用户定义完整性



