软件危机与软件工程
软件危机
问题
- 如何开发软件以满足不断增长
- 如何维护数量不断膨胀的软件产品
表现
- 成本超预算,上线拖延
- 偏离用户需求
- 质量不够
- 可维护度低
- 没有适当文档
- 成本提高
- 供不应求
原因
- 软件本身特点
- 软件开发错误认识做法
- 开发维护的不正确
软件过程
软件生存周期过程
软件过程七大元素
活动
开发、维护、管理
任务
活动细分,确定、安排任务
工件
软件过程的工作产品,分输入与输出工作
角色
定义软件过程中的个人或小组的行为与职责
资源
最佳实践、工具、技术、机器、场地等
目标
每个过程有明确目标
度量指标
目标的具体度量与分析:进度、成本、质量、返工率
软件生存周期模型
线性顺序模型
瀑布模型
特点:
- 强调阶段的划分顺序与依赖;
- 强调各阶段工作文档的完备性,即文档驱动静态描述;
- 每个阶段从技术和管理进行严格的审查,即质量保证的
观点; - 是一种线性的、顺序的、逐步细化的开发模式;
- 推迟实现的观点;
适用时机:
- 所有功能、性能等要求能一次理解和描述时
- 所有的系统功能一次交付时
- 必须同时淘汰全部老系统时
实际的瀑布模型具有反馈环
风险缺点:
- 获得完善的需求规约是非常困难的;
- 难以适应快速变化需求;
- 系统太大时,难以一次做完;
- 反馈信息慢;
- 极可能引起开发后期的大量返工,如返工到需求、设计等早
期活动;
建议不适用的情况:

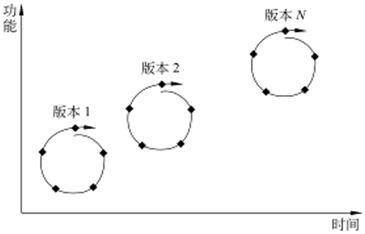
增量式模型
软件被分解成许多增量构件,逐个提交
构造中间版本
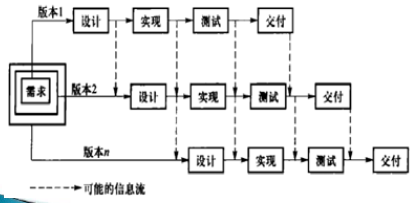
适用实际:
- 需要早期获得功能;
- 中间产品可以提供使用;
- 系统被自然地分割成增量;
- 工作人员/资金可以逐步增加。
考虑风险:
- 需求未被很好地理解
- 一次要求所有功能
- 需求迅速发生变化
- 事先打算采用的技术迅速发生变化
- 长时期内仅有有限的资源(人员/资金)
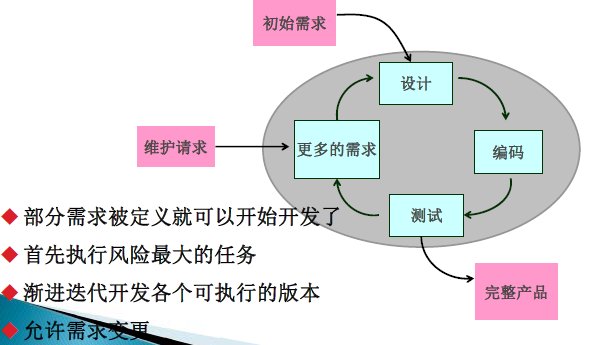
演化模型
只要核心需求能够被很好地理解,就可以进行渐进式开发,其余需求可以在后续的迭代中进一步定义和实现。这种过程模型称为演化模型,它能很好地适应随时间演化的产品的开发。
特点:
迭代的开发方法,渐进地开发各个可执行版本,逐步完善软件产品。每个版本在开发时,开发过程中的活动和任务顺序地或部分重叠平行地被采用。
与增量模型的区别是:需求在开发早期不能被完全了解和确定,在一部分被定义后开发就开始了,然后在每个相继的版本中逐步完善。
现代软件工程采用演化模型
- 统一软件过程RUP
- 敏捷过程
- 净室软件过程
演化模型的子类
- 原型
- 螺旋模型
- 并发开发模型
演化模型
迭代化开发
特点: 尽可能降低风险,适用处理不确定的复杂系统。
原则:
- 每次迭代产生一个可执行的版本;
- 要求有计划地迭代。
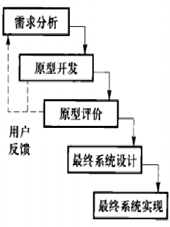
快速原型模型
特点:定义出总体目标或初步需求就开发原型,通过原型与用户交互识别进一步的需求.
- 抛弃式原型
- 演化式原型
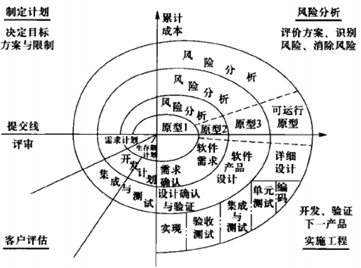
螺旋模型
RUP统一软件过程
- 迭代式开发
- 管理需求
- 使用基于构件的体系结构
- 可视化建模
- 贯穿于开发过程的软件质量验证
- 控制软件变更

Best Practices
Process Made Practical
Develop Iteratively
Manage Requirements
Use Component Architectures
Model Visually (UML)
Continuously Verify Quality
Manage Change
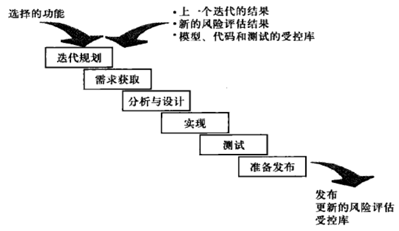
RUP软件开发生命周期
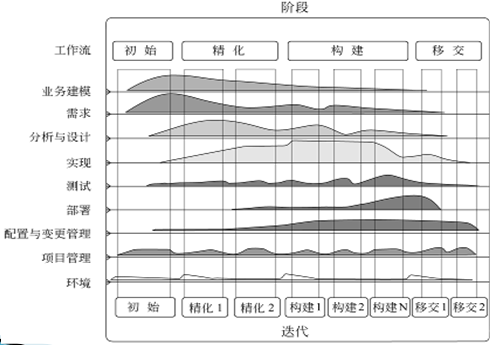
RUP是一个风险驱动的、基于UML和构件式架构的迭代、递增型开发过程
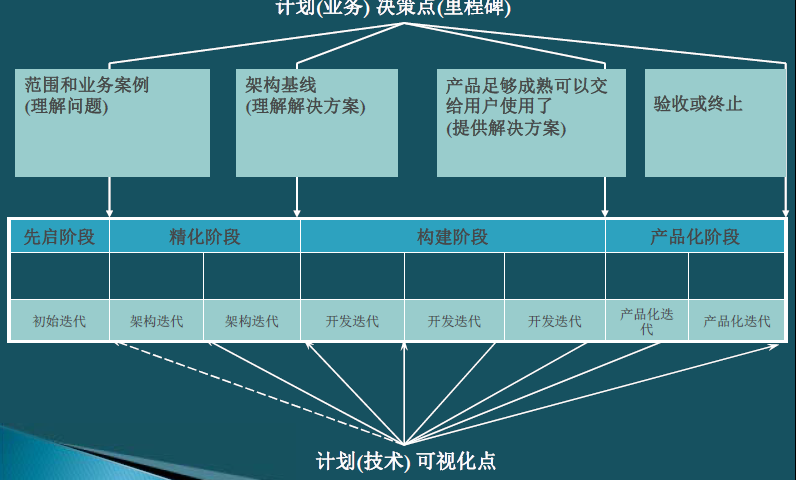
阶段和迭代
6个核心规范和3个支持规范
RUP把软件开发生命周期分成6个核心规范和3个支持规范
6个核心规范
- 业务建模(系统目标达成共识)
- 需求(系统范围达成共识)
- 设计
- 实现
- 测试
- 部署
3个支持规范
- 配置与变更管理
- 项目管理(风险,计划,进度等)
- 环境
敏捷过程与极限编程
敏捷过程
具有高效、快速响应变化的开发过程
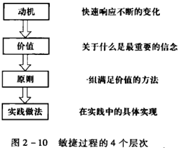
动机:快速的市场进入时间、快速变化的需求、快速发展的技术
敏捷宣言
- 个体和交互胜过过程和工具;
- 可以工作的软件胜过面面俱到的文档;
- 客户合作胜过合同谈判;
- 响应变化胜过遵循计划。
敏捷过程的原则
- 优先目标是尽早持续交付高价值的软件来满足客户需求;
- 通过驾驭变化帮助客户赢得竞争;
- 经常交付可用软件;
- 业务员和开发人员必须每天一起工作;
- 以积极主动地人为核心建立项目团队;
- 可用软件是最主要的项目进展目标;
- 团队内外最有效的交流是面对面交流;
- 提倡可持续开发,保持稳定的工作步调;
- 用精益求精和优良设计增强敏捷性;
- 简约—工作最小化;
- 最优的架构、需求和设计来自自组织的团队;
- 团队不断开展工作反思,校正自身行为。
实践做法
- 敏捷过程很容易适应变化并迅速做出自我调整,在保证质量的前提下,实现企业效益的最大化
- 敏捷过程在保证软件开发有成功产出的前提下,尽量减少开发过程中的活动和制品,Just enough
适用范围
- 需求不确定、易挥发
- 有责任感和积极向上的开发人员
- 用户容易沟通并能参与
- 小于10个人的项目团队
极限编程XP-敏捷软件工程实践
价值观
沟通、反馈、简化、勇气
特点
测试成为开发的核心;
纪律性与灵活性巧妙结合.
XP项目的整体开发过程
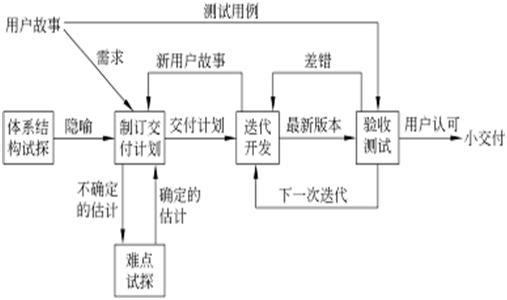

XP迭代开发过程
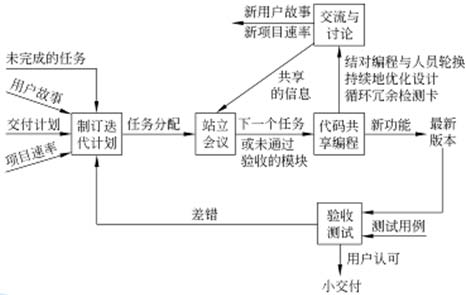
XP关键做法
- 现场客户(On-site Customer)
- 计划博弈(Planning Game)
- 系统隐喻(System Metaphor)
- 简化设计(Simple Design)
- 集体拥有代码(Collective Code Ownership)
- 结对编程(Pair Programming)
- 测试驱动(Test-driven)
- 小型发布(Small Releases)
- 重构(Refactoring)
- 持续集成(Continuousintegration)
- 每周40小时工作制(40-hour Weeks)
- 代码规范(Coding Standards)
RUP与XP共性
- 基础都是面向对象方法(取代传统的结构化方法)
- 都重视代码、文档的最小化和设计的简化
- 采用动态适应变化的演进式迭代周期(取代传统的瀑布型生命周期)
- 需求和测试驱动
- 鼓励用户积极参与
RUP与XP的区别
- XP以代码为中心,编码和设计活动融为一体,弱化了架构的概念。
- RUP过程通常以架构为中心,细化阶段的主要目的就是构造出一个可运行的架构原型,作为将来添加需求功能的稳固基础。
- XP不包含业务建模、部署、过程管理等概念。
- RUP适合各种规模的项目,XP只适用于小团队。
微软过程
微软过程准则
- 项目计划应该兼顾未来的不确定因素;
- 用有效的风险管理来减少不确定因素的影响;
- 经常生成并快速的地测试软件的过渡版本,提高稳定性和可预测性;
- 采用快速循环,递进的开发过程;
- 用创造性的工作来平衡产品特性和产品成本;
- 项目进度表应该具有较高稳定性和权威性;
- 使用小型项目组并发的完成开发工作;
- 在项目早期把软件配置项基线化,项目后期则冻结产品;
- 使用原型验证概念,对项目进行早期论证;
- 把零缺陷作为追求的目标;
- 里程碑评审会的目的是改进工作,切忌相互指责.
微软软件生命周期
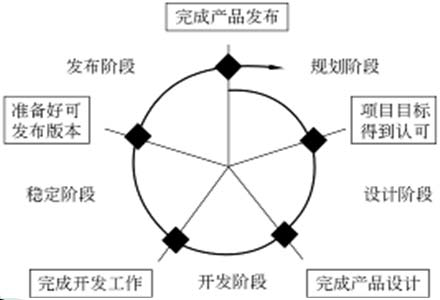
微软过程模型
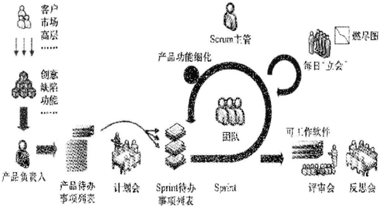
Scrum过程
- 强调经验性过程而不是确定性过程
- 演化型的迭代开发过程
软件过程的选择与裁切
软件过程的选择
- 产品/项目自身的特点
- 团队的实际情况和企业文化
- 客户的影响
软件过程进行裁剪
- 流程归并与裁剪
- 角色的筛选与定制
- 工件的裁剪和定制
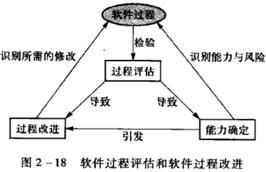
软件过程的评估与改进
参考模型
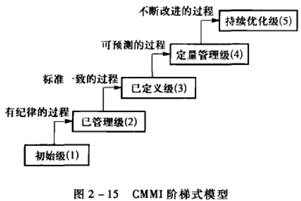
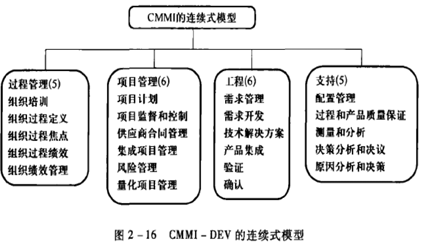
CMM/CMMI
过程能力成熟度模型
CMMI是一个标准簇
- CMMI4Development
- CMMI4Svervice
- CMMI4Acquisition
CMMI模型不同的改进方法:
- 组织成熟度方法(阶梯式模型)
- 过程能力方法(连续式模型)
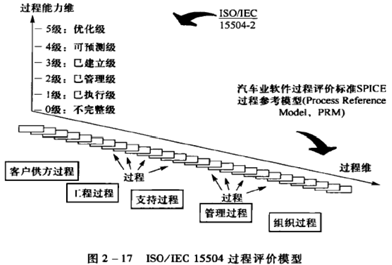
ISO/IEC 15504
信息技术-软件过程评价标准,又称为SPICE
ISO/IEC 20000
用于评估和认证IT运维服务管理过程的能力
软件过程的改进
软件建模
软件建模的三个层面
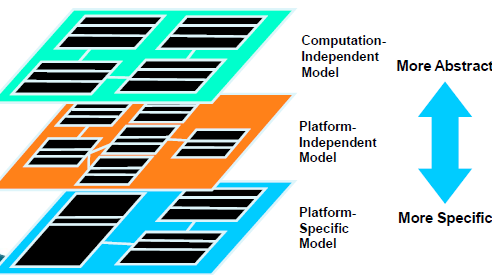
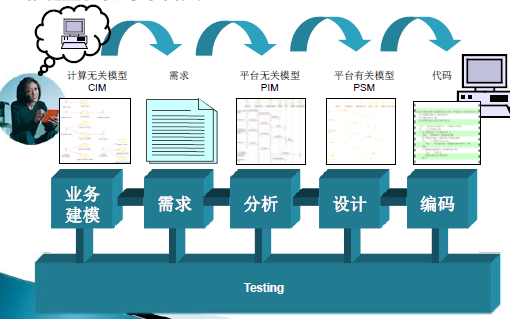
CIM、PIM和PSM
- 计算无关模型
- 平台无关模型
- 平台相关模型
软件建模方法
- 结构化方法
- 面向对象方法
- 基于构件的开发方法
- 面向服务方法
- 面向方面方法
- 模型驱动开发方法
- 形式化方法
- 产品线开发方法和领域工程
结构化方法
- 核心: 自顶向下,逐步求精
- 手段: 分解(模块化)、抽象
- 任务:结构化分析、结构化设计、结构化编程
- 常用建模工具:
- 需求建模:
- DFD(数据流图)
- DD(数据字典)、ERD(实体关系图)
- STD(状态图)
- 设计建模:
- 概要设计:结构图(SC)
- 详细设计:程序流程图、N-S图、PAD图、伪代码
- 结构化编程:三种经典程序结构
- 需求建模:
面向对象方法
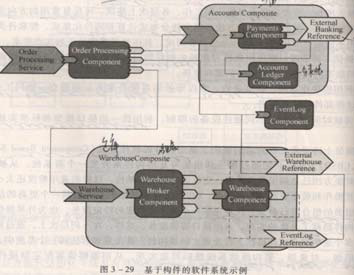
基于构件的开发方法
- 跨时间、跨空间、跨用户以及跨用户的共享
- 异构协同工作、各层次集成、反复重用
- 支持分布式计算与构件化集成、不同标准构件拼装
- CBSD具备:
- 用预先编程功能明确的部件定制而成,可用不同版本部件实现应用扩展;
- 系统分解为相互独立协同工作的部件,可反复重用;
- 利用统一的接口和标准实现跨平台的互操作。
CBSD通过构造和组装可复用构件来开发一个新系统。
抽象程度:
- 面向对象方法,以类为封装单位,为类及宠用;
- 构建话方法,
- 对一组类进行组合封装,通过接口将底层多个逻辑组合成高层次的新构件,可在代码级、对象级、架构级、系统级重用,实现定制组装软件
构建的概念
独立于特定平台和应用系统,具有标准接口,支持一定功能,可重用与自包含的软件构成部分。
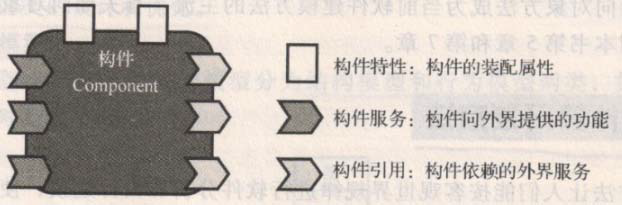
构建的类型
- 按重用的方式
白盒构件、灰盒构件、黑盒构件 - 按使用的范围
通用构件、领域共性构件、应用专用构件 - 按粒度的大小
小粒度,基本数据结构构件,如窗口、菜单等
中粒度,如文本录入、查询、删除功能构件等
大粒度,子系统构件,如文本编辑子系统、图形图像处理子系统等。 - 按用途
系统构件,整个集成与系统环境中都使用的构件;
支撑构件,在集成环境和构件管理系统中使用的构件;
领域构件,专门领域开发的构件。 - 按构件结构
原子构件,无需再分的最小基本单元;
组合构件,由多个构件聚集而成。
常用的构建标准
CORBA

COM/DCOM/COM+

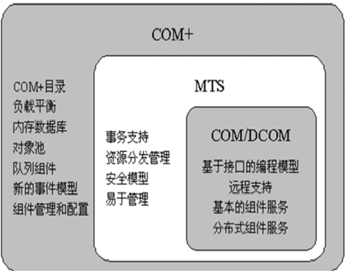
J2E和EJB

SCA

开发流程
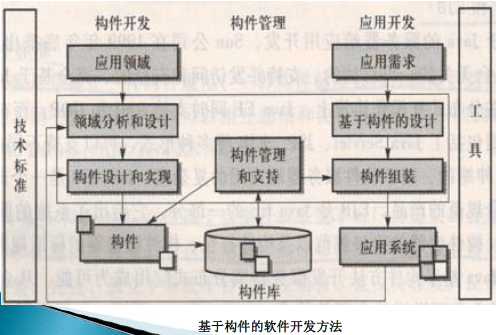
- 构件开发
- 领域分析与设计
- 构件设计与实现
- 构件入库
- 构件管理
- 组织、描述、分类、检索构件
- 管理与维护构件库
- 评估构件资产,不断改进
- 应用开发与组装
- 基于构件的设计(基于构件的应用系统体系结构)
- 构件组装
- 系统测试与发布
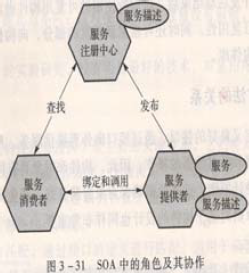
面向服务的方法
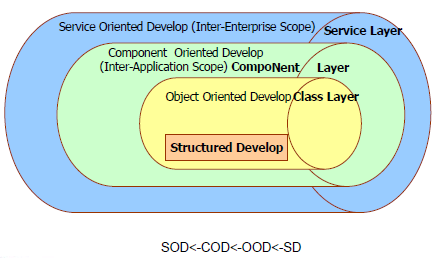
服务、构建和类之间的关系
服务的特征
服务的抽象性(基于接口的编程)
- 服务是实际程序、数据库、业务过程等软件实体的抽象了的逻
辑视图。 - 实现平台透明性
- 服务是实际程序、数据库、业务过程等软件实体的抽象了的逻
服务的自治性(实现分布式应用)
You don’t “new” a service – it’s just there.
服务间的松耦合式绑定,基于标准化消息进行通信
服务的自描述性(支持动态发现与延迟绑定)
- 服务具有可发布、可发现、机器可处理的接口契约
服务的粗粒度(支持基于业务逻辑的积木式装配)
SOA模型
- 相对较粗的粒度上对应用服务或业务模块进行封装与重用;
- 服务间保持松散耦合,基于开放的标准, 服务的接口描述与具体实现无关;
- 灵活的架构-服务的实现细节,服务的位置乃至服务请求的底层协议都应该透明;
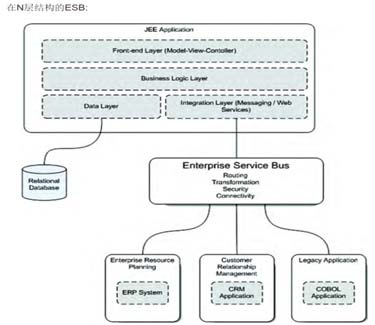
企业服务总线ESB
在SOA中还需要一个中间层,能够帮助实现在SOA架构中不同服务之间的智能化管理。这就是企业服务总线.
ESB的主要功能是:
- 对各个服务之间消息监控与路由
- 解决各个服务组件之间通信
- 控制服务版本与部署
- 满足服务像事件处理,数据转换与映射,消息与事件查询与排序,安全或异常处理,协议转换,保证服务通讯的质量.
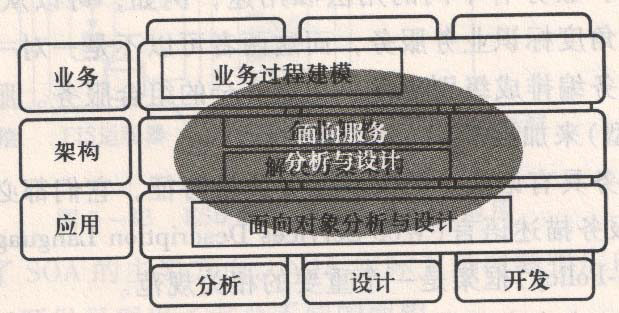
面向服务软件开发SOAD

业务建模
服务分析
- 服务识别
- 自顶向下分解,由业务需求驱动,设计服务。如果没有已有的软件服务相对应,就需要设计一个全新的服务。
- 优点:业务流程中的业务服务和软件服务之间的交互是完全匹配的;
- 缺点:可能对现有软件服务的利用率不高,因为识别出来的业务服务有可能与现有软件服务之间不能完全匹配。
- 自底向上抽象,以现有服务驱动进行匹配
- 优点:通过不断地将业务服务与已有的软件服务进行匹配,使得对已有软件服务能够进行最大限度的复用;
- 缺点:可能会发现很多业务服务无法找到合适的现有服务进行匹配,导致需要新开发的服务数量变多。中间汇合,两头并行设计
- 自顶向下分解,由业务需求驱动,设计服务。如果没有已有的软件服务相对应,就需要设计一个全新的服务。
- 服务粒度的确定
- 以对业务的精确掌握和理解为基础,在性能、可维护性和随需应变之间进行平衡,选择适合的粒度进行服务的识别和划分。
- 服务粒度太细会使得服务流程过于复杂,而且服务流程执行的效率也会降低很多;
- 服务流程太粗会使得服务流程难以改动,从而使得随需应变无法实现。
- 需要我们能够预判业务流程在将来有可能出现的变化,然后根据这种预判来设计服务的粒度。
- 以对业务的精确掌握和理解为基础,在性能、可维护性和随需应变之间进行平衡,选择适合的粒度进行服务的识别和划分。
- 服务的组织
- 编制
- 在流程中有一个作为流程中心的服务,它负责控制流程中其他参与交互的服务,协调服务间的消息传递。
- 除流程中心服务之外的其他参与交互的服务。
- 编排
- 参与业务过程的Web服务之间是协作关系,为了实现一个业务流程,每一个参与其中的服务都需要明确地知道自己应该在什么情况下与哪些其他服务进行交互。
- 编制
面向服务建模涉及的三个层面
- 业务层面
功能域:业务逻辑描述
业务流程:业务逻辑编排
业务服务:识别服务,产生业务服务集 - 服务层面
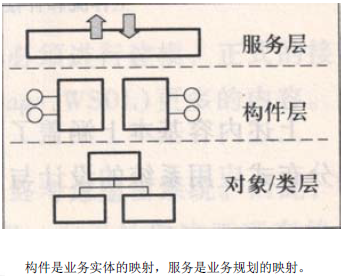
根据业务流程和业务服务集设计软件服务集。 - 构件层面
服务最终由构件实现的,在特定的开发语言与框架中进行设计,可将多个服务中的共用部分抽取出来构成通用的工具构件。
通过面向服务的架构将多个相关但独立开发的应用系统集成。从底层构件层面向上,并从顶层的业务层面向下,最终在软件服务和业务服务的中间点会合,得到完整的设计方案。
模型驱动开发
- 将软件的开发集中于模型而不是程序(代码)的一种开发方法
- 从模型自动产生程序(代码)
- 主要用来提高开发生产率和代码的可靠性
- OMG 定义模型驱动的体系结构(Model-Driven Architecture,简称MDA)的初衷
- 定义一组标准来支持模型驱动的开发
- UML 是MDA 的基础之一
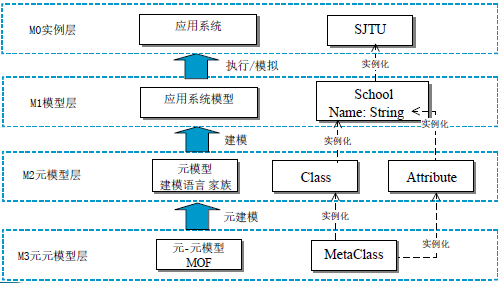
模型与元模型
计算无关模型
- Uses the vocabulary of the domain.
- No information in the model indicates that a computerbased solution will be used.
平台无关模型
- Less abstract than CIM
- Closer to implementation but not tied to a platform.
平台有关模型
- Less abstract than PIM
- Closer to implementation
- J2EE elements captured in model
模型间的转换
模型驱动的软件开发MDD
- 以模型为中心(相对于以代码为中心)的软件开发方法
- 基于以下两种久经考验的技术
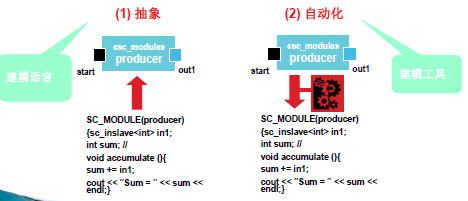
可执行的UML(xUML)
xUML =UML-语义较弱的元素+精确定义的动作语义
从PIM到PSM或代码的(半)自动生成
- 通过标记、profile、OCL或者其他途径进行平台无关模型(PIM)的刻画,然后定义相关的转换规则来完成从平台无关模型到平台相关模型或代码的转换。
基于DSL的开发方法
- 领域描述语言(Domain Specific Language,DSL)通过适当的表示方法和抽象机制来提供对特定问题领域的表述能力,DSL 常用来生成特定应用领域中的一个产品/应用家族的应用。
形式化方法
- 形式化方法是基于数学的技术开发软件,如集合论、模糊逻辑、函数、有限状态机、Petrinet等。
- 形式化方法的好处:
- 无二义性
- 一致性
- 正确性
- 完整性
有限状态机见PPT
需求工程
- 软件需求面临的挑战
- 用户说不清需求;
- 需求表达的二义性问题;
- 需求经常变化, 项目没有时限;
- 因误解或二义性的需求直到开发后期才发现;
- 测试者没有明白产品要做什么;
- 产品性能低、使用不方便等用户不满意;
- 许多增强性需求未在需求获取阶段提出。
需求工程的概念
软件需求 FURPS and FURPS+
功能性需求(F)与非功能性需求(URPS)
| 需求 | 能力 | 具体要求 |
|---|---|---|
| Functionality | Feature Set,Capabilities | Generality,Security |
| Usability | Human Factors,Aesthetics | Consistency,Documentation |
| Reliability | Frequency/Severity,of Failure,Recoverability | Predictability,Accuracy,MTBF |
| Performance | Speed,Efficiency,>Resource Usage | Throughput,Response Time |
| Supportability | Testability,Extensibility,Adaptability,Maintainability,Compatibility | Configurability,Serviceability,Installability,Localizability,Robustness |
Functionality需求
功能、特性和安全性
- 概要功能需求
- 详细功能需求
Usablity需求
可用性
The ease with which software can be learned and
operated by the intended users
Reliability需求
软件在给定时间间隔内成功运行的概率
- 可靠性需求
- 故障的频率
- 可恢复性
- 可预见性
- 准确性
- 平均失效间隔时间/平均无故障时间,MTBF
Performance需求
- 性能需求
- 速度
- 效率
- 吞吐量
- 响应时间
- 容量
- 资源利用情况
Supportability需求
支持性需求
- 可测试性
- 可扩展性
- 可适应性
- 可维护性
- 兼容性
- 可配置性
- 可服务性
- 可安装性
- 可本地化/国际化
FURPS+
- 设计约束(design constraints):规定或约束了系统的设计的需求;
- 实现需求(implementation requirements) :规定或约束了系统的编码或构建,如所需标准、编程语言、数据库完整性策略、资源限制和操作环境;
- 接口需求(interface requirements):规定了系统必须与之交互操作的外部软件或硬件,以及对这种交互操作所使用的格式、时间或其他因素的约束;
- 物理需求(physical requirements.):规定了系统必须具备的物理特征,可用来代表硬件要求,如物理网络配置需求。
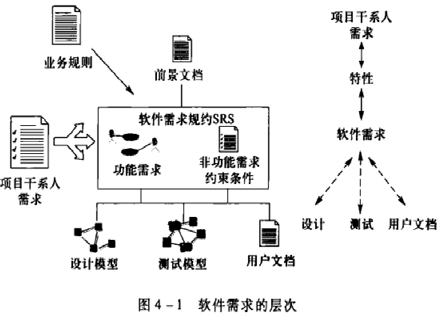
软件需求的三个层次
- 系统需求:业务/产品需求
- 项目干系人需求:原始需求
- 项目前景文档:概要需求
- 软件需求规约:详细需求
需求获取
业务分析-〉确定系统边界-〉项目干系人交流-〉竞争产品观察-〉定义系统高层输入-〉形成前景文档
前景文档–产品范围文档
- 简介
- 定位
- 商机
- 问题说明
- 产品定位
- 项目干系人和用户描述
- 产品概述
- 产品特性
- 约束
- 质量范围
- 优先级
- 其他产品需求
- 文档需求
分析问题及根源
识别项目干系人
识别项目的约束
获取常用术语
识别需求的来源
收集需求
产品定位
撰写产品特性
定义质量范围
定义文档需求
建立项目范围
划分特性优先级
需求分析建模
分析模型
需求分析的结果
与平台无关模型PIM
- 描述客户需求
- 建立软件设计基础
- 定义软件完成后可以被确认
结构化分析模型
- 数据流图(DFD)
- 控制流图(CFD)
- 数据字典(DD)
- 实体—关系图(ERD)
- 状态转换图(STD)
- 加工说明(PSPEC)
面向对象分析模型
- 用例图
- 活动图
- 类图
- 时序图、通信图
- 状态机图
分析建模准则
- 必须描述并理解问题的信息域
- 输入输出数据、永久性数据对象
- 必须确定软件所需要的功能
- 必须描述软件的行为
- 受外部事件驱动的结果
- 模型必须能提以一种能提示层次化方式的分解
- 分析任务应该从本质信息向实现细节转移
需求定义和验证
定义需求、撰写需求文档(前景文档和详细的软件需求规约)
软件前景文档
软件需求规约
作用:
作用:
- 项目管理的依据;
- 设计与实现的输入;
- 测试与质量保证的输入;
组成:
- 功能需求;
- 非功能性需求;
- 约束;
软件需求规约SRS定义了系统的外在行为和属性
统一软件过程UP提供的两个SRS需求模板



细化需求
- 细化功能需求
- 引入分析模型
- 细化非功能需求
- 细化约束条件
用户界面原型
- 也称“行为模型”,用来描述软件产品的行为,达到明确与细化需求的目的。
- 如果和用户交互,则需简要设计用户界面
- 图纸(在纸上)
- 位图(采用绘图工具),或可执行代码(交互式的电子界面原型)
需求验证
验证方面
一致性
所有需求必须是一致的,任何一条需求不能和其他需求互相矛盾
完整性
需求必须是完整的,规格说明书应该包括用户需要的每一个功能或性能
现实性
指定的需求应该是用现有的硬件技术和软件技术基本上可以实现的
有效性
必须证明需求是正确有效的,确实能解决用户面对的问题
需求验证方法
原型确认
- 抛弃型
- 演进型
需求评审
评审需求文档(Vision和SRS等),及时发现缺陷,寻找改进的契机,同时从评审反馈中获得知识,补充了正规的交流和培训机制,帮助团队建立对产品的共同理解
评审过程
准备计划-〉实施评审-〉返工-〉定稿签字
需求评审方法
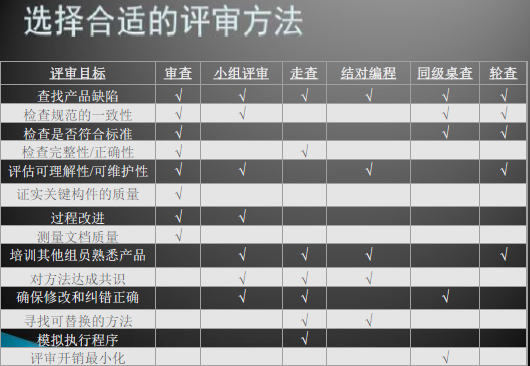
- 审查
- 小组评审
- 走查
- 结对编程
- 同级桌查
- 轮查
- 临时评审
需求评审的输入输出
- 输入
- 待评审的需求文档
- Check list
- 输出
- 评审结论
- 通过
- 有条件通过
- 不通过
- 缺陷清单
- 评审结论
需求管理
- 定义需求基线
- 需求跟踪
- 需求变更控制(建立新的需求基线)
建立需求基线
通过对软件产品的特性和需求划分优先级来定义需求基线
需求变更控制和版本控制
- 需求/范围变化的原因
- 初期的认识不足导致错误或不完整的需求/范围
- 需求/范围本身存在不一致
- 业务变化导致的刚性需求/范围变更
- 外部经济、市场环境的变化
- 客户和项目组对已确认的需求/范围理解不一致
- 技术制约或多目标权衡带来的需求/范围变更
- 需求变更策略
- 以基线为核心统一变更控制过程
- 建立项目变更管理小组
- 未获批准不得擅自实施变更
- 干系人和项目组成员应即时了解变更
- 开发计划、设计测试代码的文档应及时更新
- 采用需求变更控制工具
需求跟踪
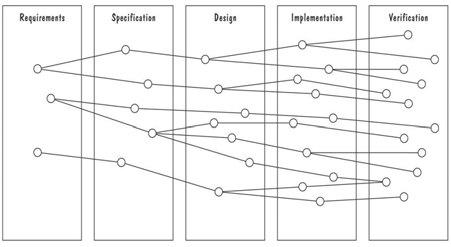
结构化分析
结构化方法概述
一种面向数据流的传统软件开发方法
以数据流为中心构建软件的分析模型、设计模型和实现模型
- 结构化分析(Structured Analysis,简称SA)
- 结构化设计(Structured Design,简称SD)
- 结构化编程(Structured Programming,简称SP)
结构化分析方法中的抽象与分解
随着分解层次的增加,抽象的级别越来越低,也越接近问题的解(算法和数据结构)
结构化分析模型
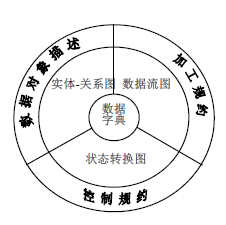
- 数据字典是模型的核心,它包含了软件使用和产生所有数据的描述
- 数据流图:用于功能建模,描述系统的输入数据流如何经过一系列的加工变换逐步变换成系统的输出数据流
- 实体—关系图:用于数据建模,描述数据字典中数据之间的关系
- 状态转换图:用于行为建模,描述系统接收哪些外部事件,以及在外部事件的作用下的状态迁移情况
面向数据流的软件建模
系统流程图
描绘物理系统的工具,其基本思想是用图形符号以黑盒子形式描绘系统里面的每个部件(程序、文件、数据库、表格、人工过程等),表达的是信息在系统各部件之间流动的情况。
常用符号
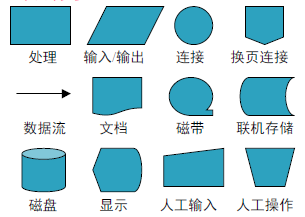
数据流图
系统逻辑模型描述分为三个方面:
- 数据流图 DFD
- 数据字典 DD
- 加工/处理说明 IPO
数据流图的定义
描述输入数据流到输出数据流的变换(即加工)过程,用于对系统的功能建模,基本元素包括:

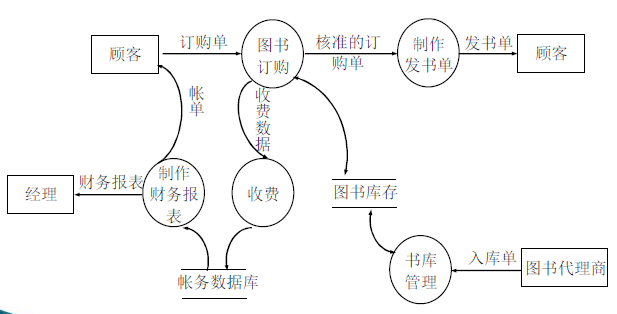
e.g. 图书订购系统DFD
数据流图的扩充符号
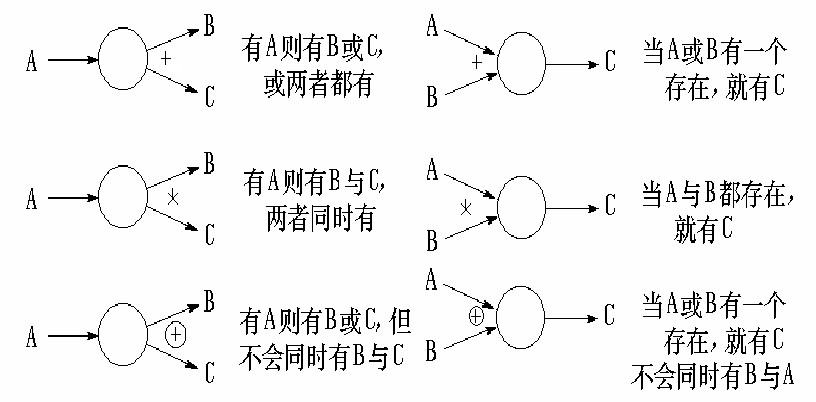
描述一个加工的多个数据流之间的关系
绘制方法
- 基本方法:自顶向下逐层分解。
- 分解原则:上层是下层的抽象,下层是上层的分解。
- 直到所有的处理都足够简单,不必再分解为止。通常把这种不能再分解的加工称为“基本处理”
分层数据流图
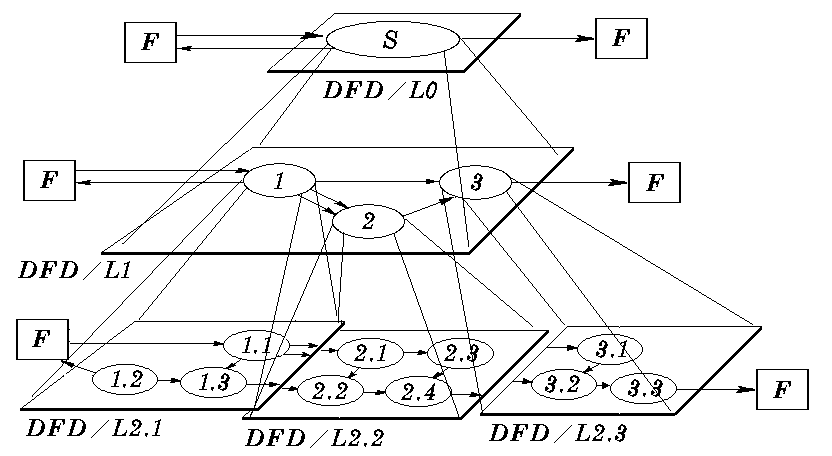
- 在多层数据流图中,顶层流图仅包含一个处理,它代表被开发系统。它的输入流是该系统的输入数据,输出流是系统所输出数据
- 底层流图是指其处理不需再做分解的数据流图,它处在最底层
- 中间层流图则表示对其上层父图的细化,它的每一处理可能继续细化,形成子
图。
DFD细化
- 确定加工
- 确定数据流
- 确定文件
画分层数据流图的步骤
- 画系统的输入和输出
- 画系统内部
- 画加工内部
- 重复第3步,直至每个尚未分解的加工都足够简单(即不必再分解)
分层数据流图的审查
- 检查图中是否存在错误或不合理(不理想)的部分
- 一致性
- 完整性
- 父图和子图平衡
- 数据守恒
数据字典
数据字典由字典条目组成,每个条目描述DFD中的一个元素
数据字典条目包括:数据流、文件、加工、源或宿
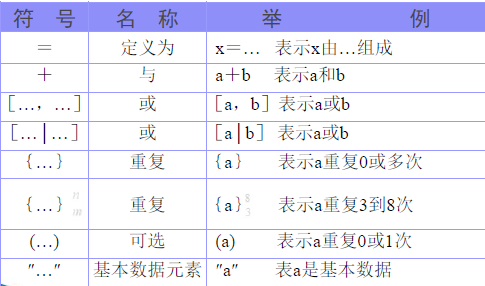
数据字典描述符号
数据流条目的描述内容
- 名称:数据流名(可以是中文名或英文名)
- 别名:名称的另一个名字
- 简述:对数据流的简单说明
- 数据流组成:描述数据流由哪些数据项组成
- 数据流来源:描述数据流从哪个加工或源流出
- 数据流去向:描述数据流流入哪个加工或宿
- 数据量:系统中该数据流的总量
- 如考务处理系统中“报名单”的总量是100000张
- 或者单位时间处理的数据流数量,如80000张/天
- 峰值:某时段处理的最大数量
- 如每天上午9:00至11:00处理60000张表单
- 注解:对该数据流的其它补充说明
数据流组成
是数据流条目的核心
文件条目的描述内容
- 名称:文件名
- 别名:同数据流条目
- 简述:对文件的简单说明
- 文件组成:描述文件的记录由哪些数据项组成(与数据流条目中的文件组成描述方法相同)
- 写文件的加工:描述哪些加工写文件
- 读文件的加工:描述哪些加工读文件
- 文件组织:描述文件的存储方式(顺序、索引),排序的关键字
- 使用权限:描述各类用户对文件读、写、修改的使用权限
- 数据量:文件的最大记录个数
- 存取频率:描述对该文件的读写频率
- 注解:对该文件的其它补充说明
加工条目的描述内容
- 名称:加工名
- 别名:同数据流条目
- 加工号: 加工在DFD中的编号
- 简述:对加工的功能的简要说明
- 输入数据流:描述加工的输入数据流,包括读哪些文件名
- 输出数据流:描述加工的输出数据流,包括写哪些文件名
- 加工逻辑:简要描述加工逻辑,或者对加工规约的索引
- 基本加工的加工逻辑用小说明描述,在加工条目中可填写对加工规约的索引
- 非基本加工分解而成的DFD子图已反映了它的加工逻辑,不必书写小说明
- 异常处理:描述加工处理过程中可能出现的异常情况,及其处理方式
- 加工激发条件:描述执行加工的条件,如“身份认证正确”,“收到报名单”
- 执行频率:描述加工的执行频率,如,每月执行一次,每天0点执行
- 注解:对加工的其它补充说明
源或宿条目的描述内容
- 名称:源或宿的名(外部实体名)
- 别名:同数据流条目
- 简要描述:对源或宿的简要描述(包括指明该外部实体在DFD中是用作“源”,还是“宿”,还是“既是源又是宿”)
- 输入数据流:描述源向系统提供哪些输入数据流
- 输出数据流:描述系统向宿提供哪些输出数据流
- 注解:对源或宿的其它补充说明
加工逻辑的描述方法
结构化语言:介于自然语言和形式语言之间的一种半形式语言
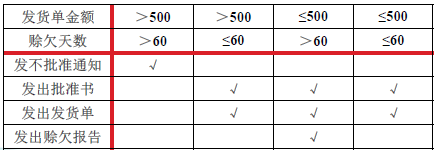
判定表:适用于加工逻辑包含多个条件,而不同的条件组合需做不同的动作
- 条件桩(Condition Stub):列出各种条件的对象,如发货单金额,赊欠天数等,每行写一个条件对象
- 条件条目(Condition entry):列出各条件对象的取值,条件条目的每一列表示了一个可能的条件组合
- 动作桩(action stub):列出所有可能采取的动作,如发出发货单等,每行写一个动作
- 动作条目(action entry):列出各种条件组合下应采取的动作
e.g.
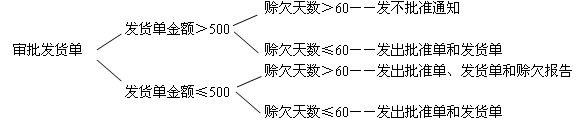
判定树:判定表的变种,它本质上与判定表是相同的,只是表示形式不同
e.g.
实体-关系图
描述数据字典中数据之间的关系
面向数据流的需求分析过程
面向数据流自顶向下逐步求精进行需求分析
确定系统的综合需求
功能需求、性能需求、可靠性和可用性需求、出错处理需求、接口需求、约束、逆向需求、将来可能的需求
分析系统的数据要求
ER模型
导出系统的逻辑模型
修正系统开发计划
开发原型系统
写需求规格说明书
面向对象分析
面向对象方法概述
抽象
最核心的抽象内容的对象
对象是一个具有明确边界和唯一标识,且封装了行为和状态的实体。
主要抽取事务的结构特征和行为特征,并组成一个有机整体
封装
将对象特征的实现方式隐藏在一个公共接口后面的黑盒子中
模块化
Breaks up something complex into manageable pieces.
层次
高度抽象
^
|
|
|
低度抽象
出发点和基本原则
尽可能模拟人类习惯的思维方式,使描述问题的问题空间(也称为问题域)与实现解法的解空间(也称为求解域)在结构上尽可能一致。
- 客观世界的问题都是由实体及关系构成的
- 把客观世界中的实体抽象为问题域中的对象(object)
面向对象方法
- 认为客观世界是由各种对象组成的
- 把所有对象都划分成各种对象类(简称为类,class),每个对象类都定义了一组数据和一组方法
- 按照子类(或称为派生类subclass)与父类(或称为基类superclass)的关系,把若干个对象类组成一个层次结构的系统(也称为类等级)
- 对象彼此之间仅能通过传递消息互相联系
$$
OO=objects+classes+inheritance+communication\ with\ messages
$$
面向对象方法的优点
- 与人类习惯的思维方法一致
- 稳定性好
- 可重用性好
- 较易开发大型软件产品
- 可维护性好
面向对象的概念
对象
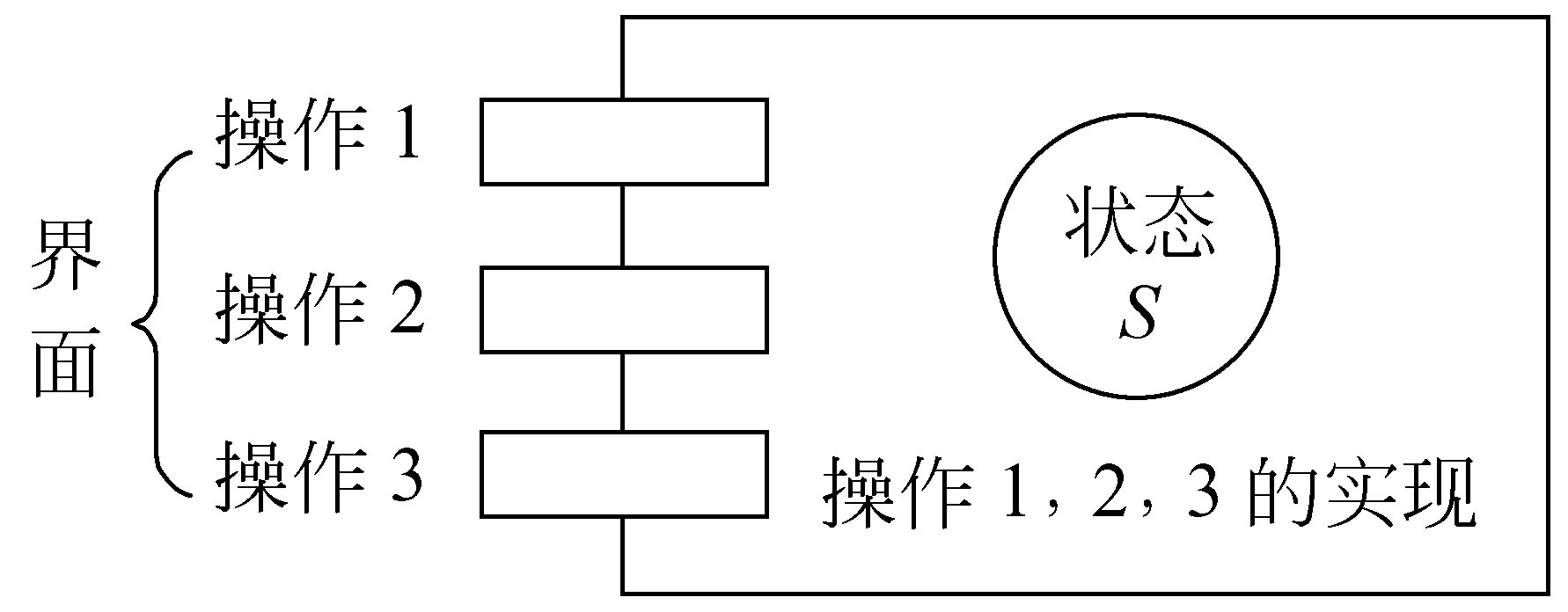
对象是具有相同状态(属性)的一组操作的集合
$$
对象=<ID,MS,DS,MI>
$$
- 以数据为中心
- 对象是主动的
- 实现了数据封装
- 本质上具有并行性
- 模块独立性好
类
类是对具有相同属性和行为的一个或多个对象的描述。类是支持继承的抽象数据类型,而对象就是类的实例
实例
实例就是由某个特定的类所描述的一个具体的对象
消息
消息就是要求某个对象执行它的某个操作的规格说明
方法
方法就是对象所能执行的操作,也就是类中所定义的服务。方法描述了对象执行操作的算法,响应消息的方法。在C++语言中把方法称为成员函数。
属性
属性就是类中所定义的数据,类的每个实例都有自己特有的属性值
封装
所谓封装就是把某个事物包起来,使外界不知道该事物的具体内容
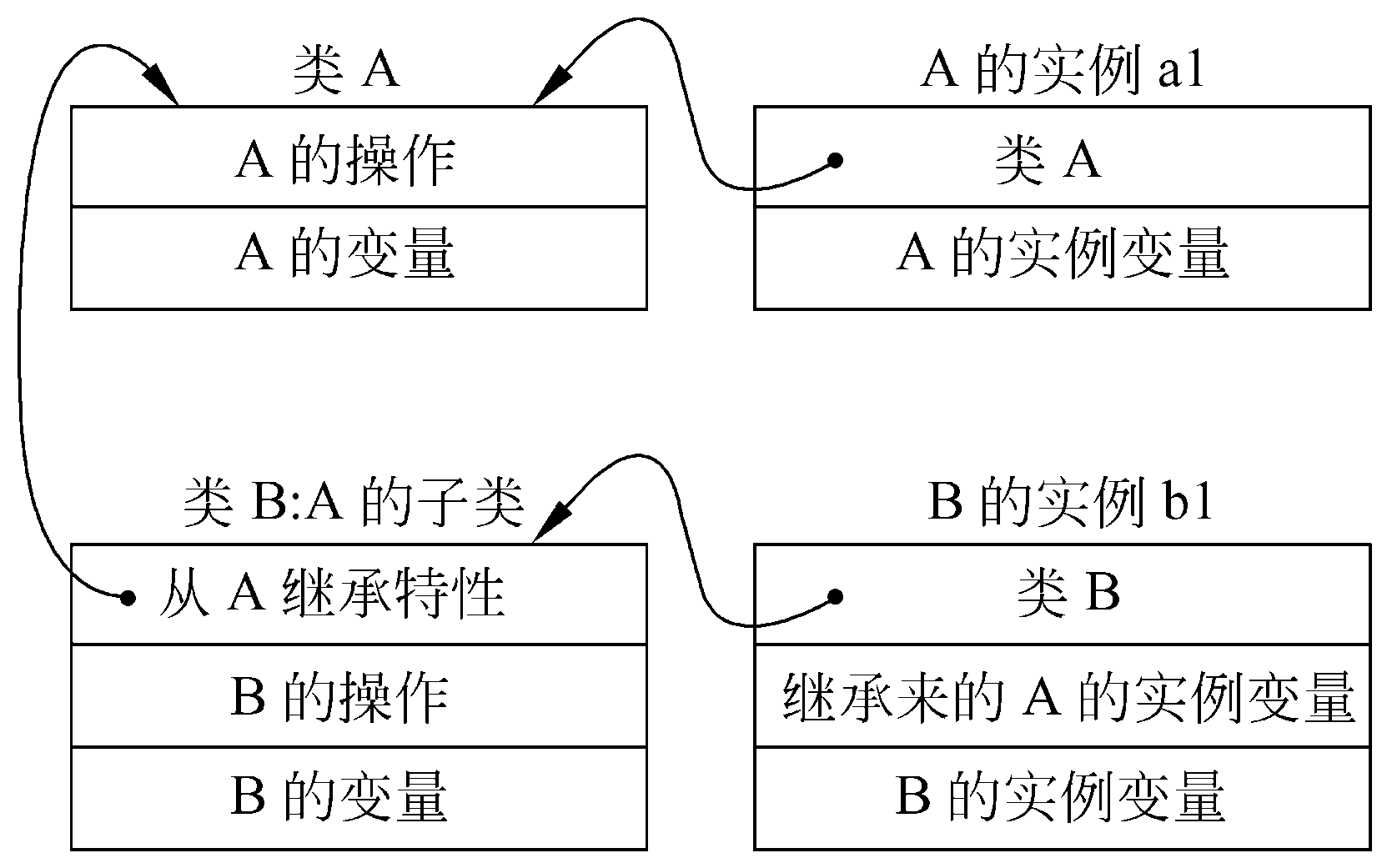
继承
继承是指能够直接获得已有的性质和特征,而不必重复定义它们。继承是子类自动地共享基类中定义的数据和方法的机制。
当类等级为树形结构时,类的继承是单继承;当允许一个类有多个父类时,类的继承是多重继承。但是,使用多重继承时要注意避免二义性
多态性
多态性是指子类对象可以像父类对象那样使用,同样的消息既可以发送给父类对象也可以发送给子类对象。根据该对象所属于的类动态选用在该类中定义的实现算法
重载
- 函数重载是指在同一作用域内的若干个参数特征不同的函数可以使用相同的函数名字
- 运算符重载是指同一个运算符可以施加于不同类型的操作数上面
各种分析图
UML建模
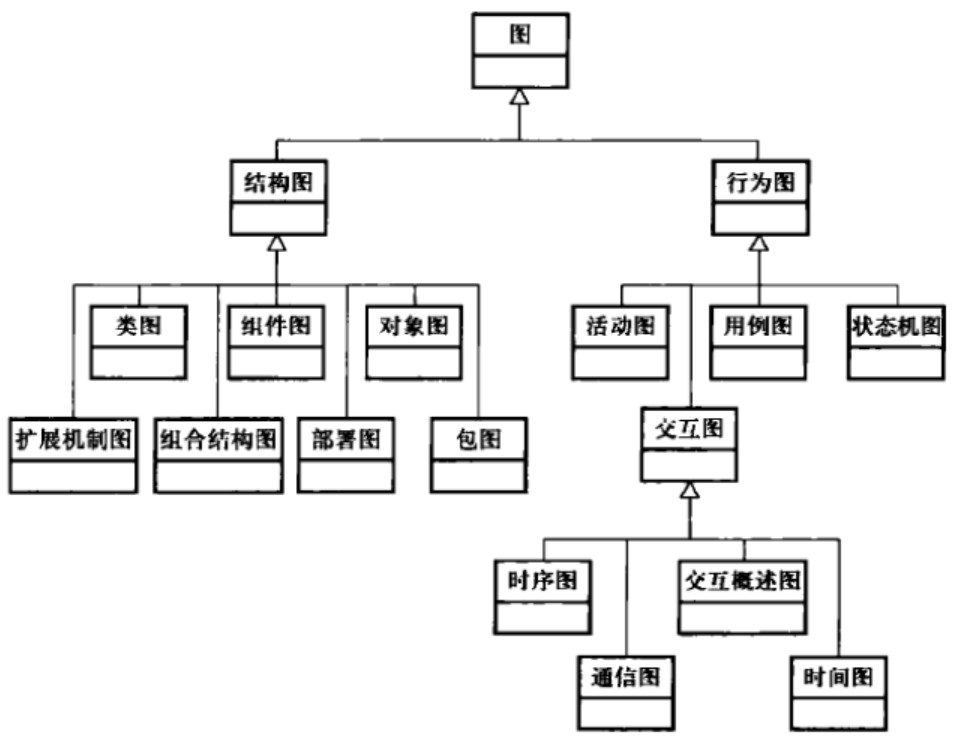
从功能和行为对问题进行抽象,主要建模包括:用例图,活动图,类图,时序图,通信图和包图
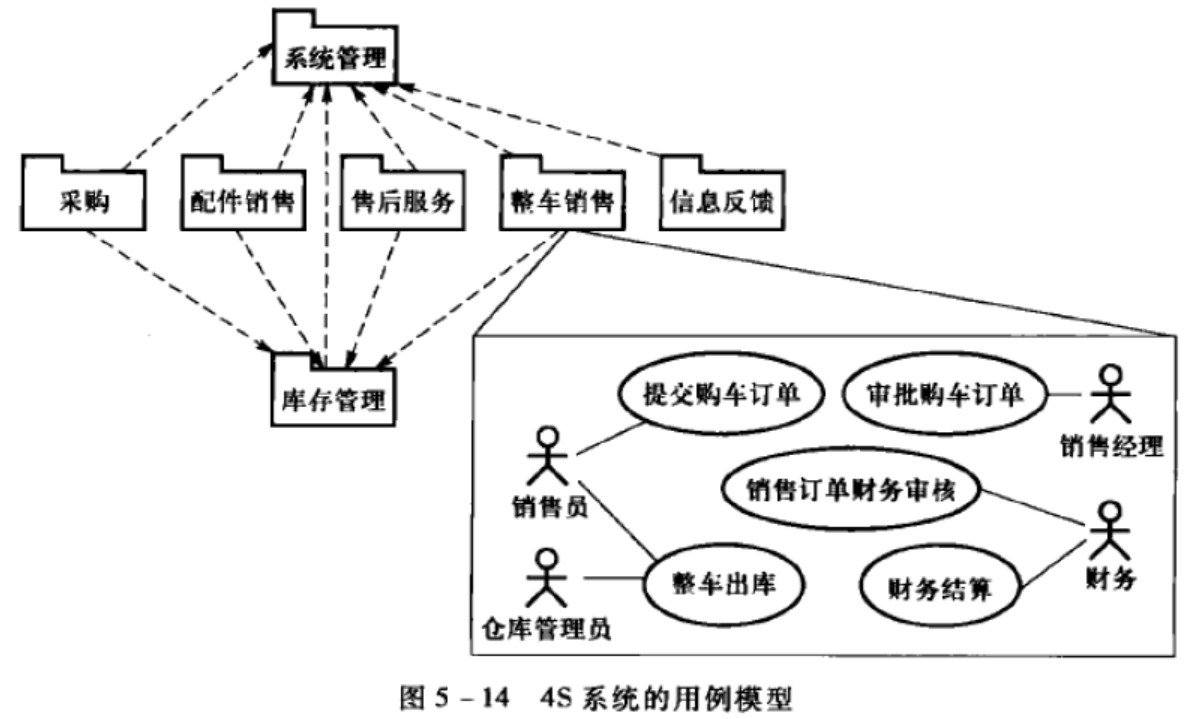
用例图
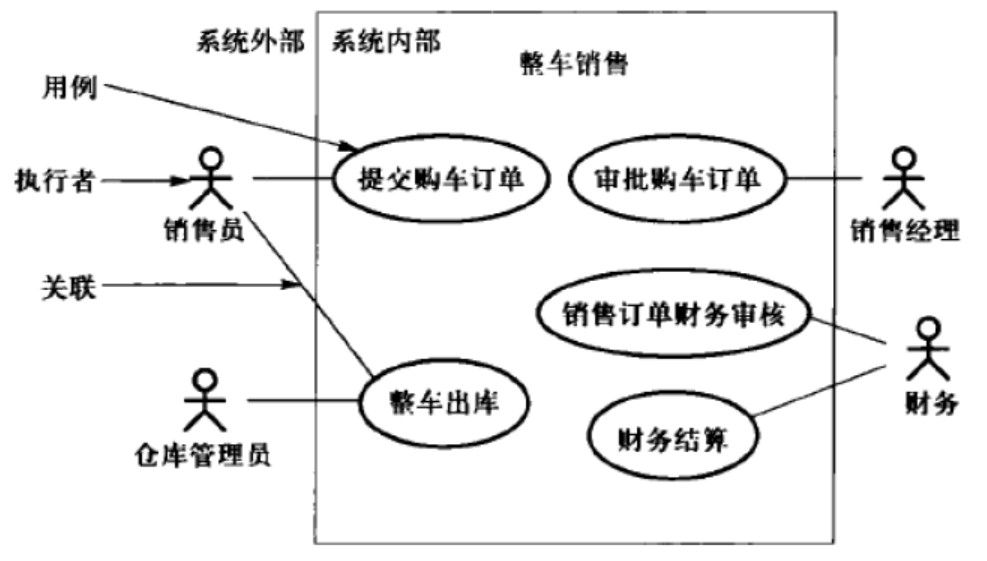
要素:执行者、用例、关系(包含、扩展、泛化)系统框常被省略
也就是说,系统外部的执行者需要系统处理什么事务,系统处理的事务就是用例,执行者与用例存在关联关系
活动图
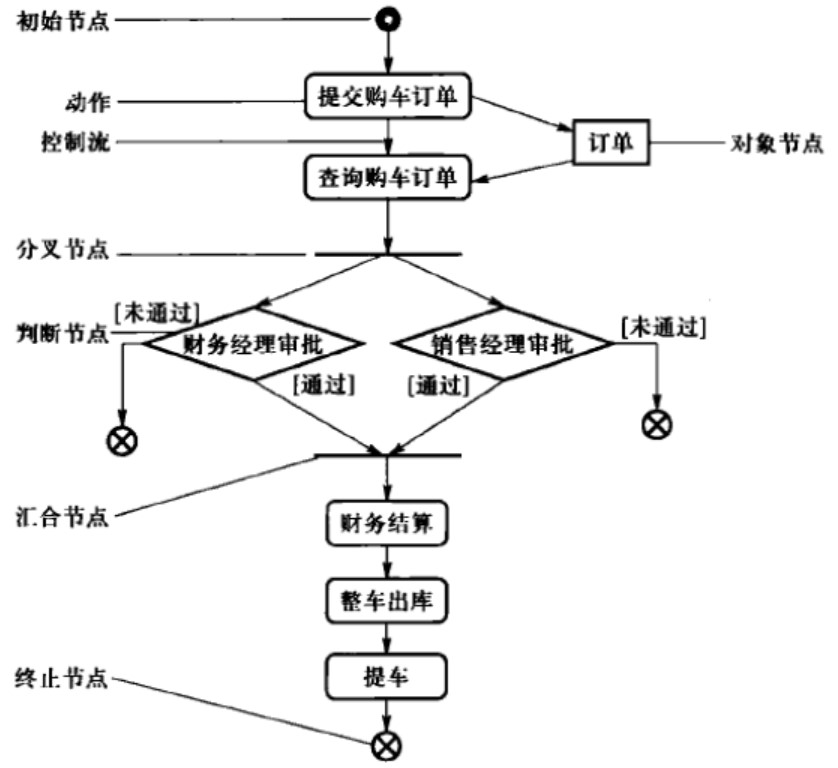
- 动作:行为的基本单元
- 控制流:动作之间的过程
- 控制节点:起协调动作的作用
初始、分叉、判断、汇合、终止 - 对象节点:是动作处理的数据
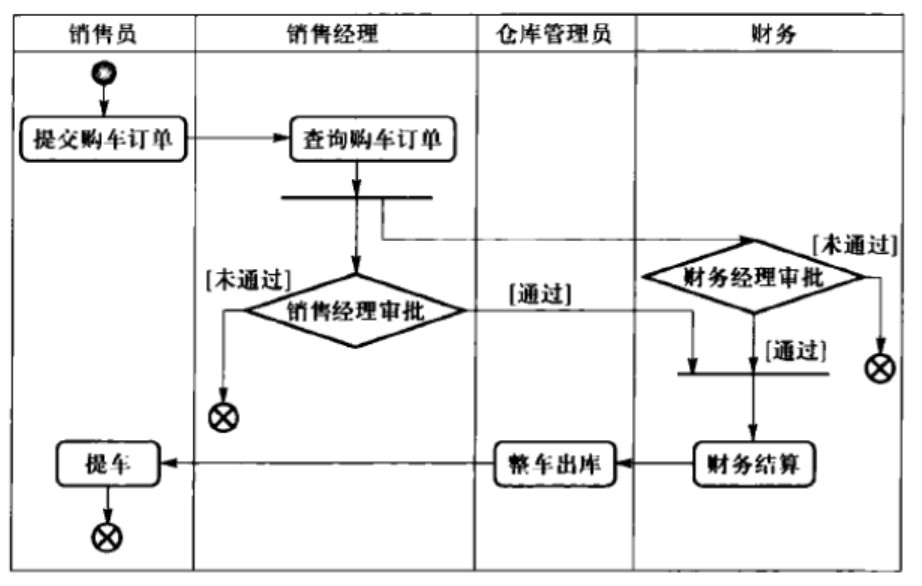
带泳道的活动图,已明确责任
类图
使用UML表示类
包括三个部分:
- 类名
- 数据结构(属性)
- 行为(操作)

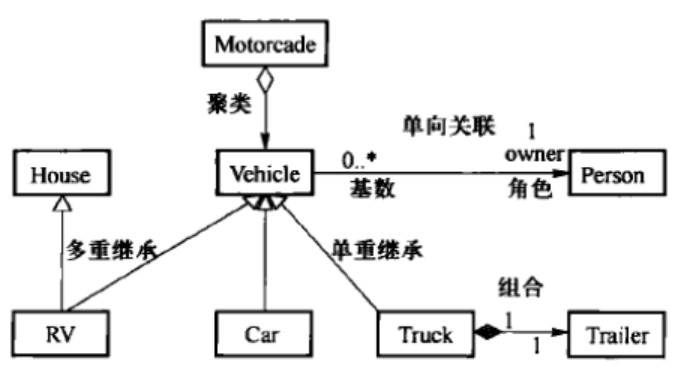
继承/泛化:is-a关系,用空心箭头实线表示
实现:类实现接口,用带空心箭头虚线表示
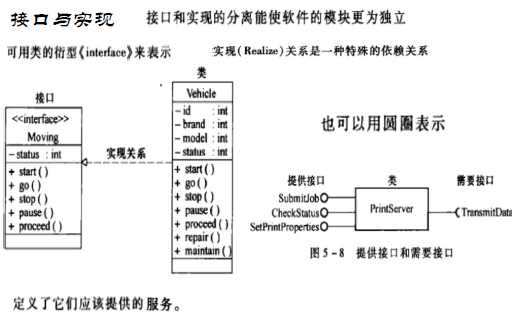
依赖:一个类对另一个类局域变量、方法的形参,或者对静态方法的调用,虚线箭头表示,临时的非结构性关系

关联:一个类的实例与另外一个类的特定实例存在固定关系,被关联类B以类属性的形式出现在关联类A中,也可能是关联类A引用了一个类型为被关联类B的全局变量,实线箭头表示
聚合:聚合是特殊的关联关系,强调整体与部分之间的关系,用带一个空心菱形(整体的一端)的实线箭头表示
组合:强调了整体与部分的生命周期是一致的,用带实心菱形(整体的一端)的实线箭头表示
基数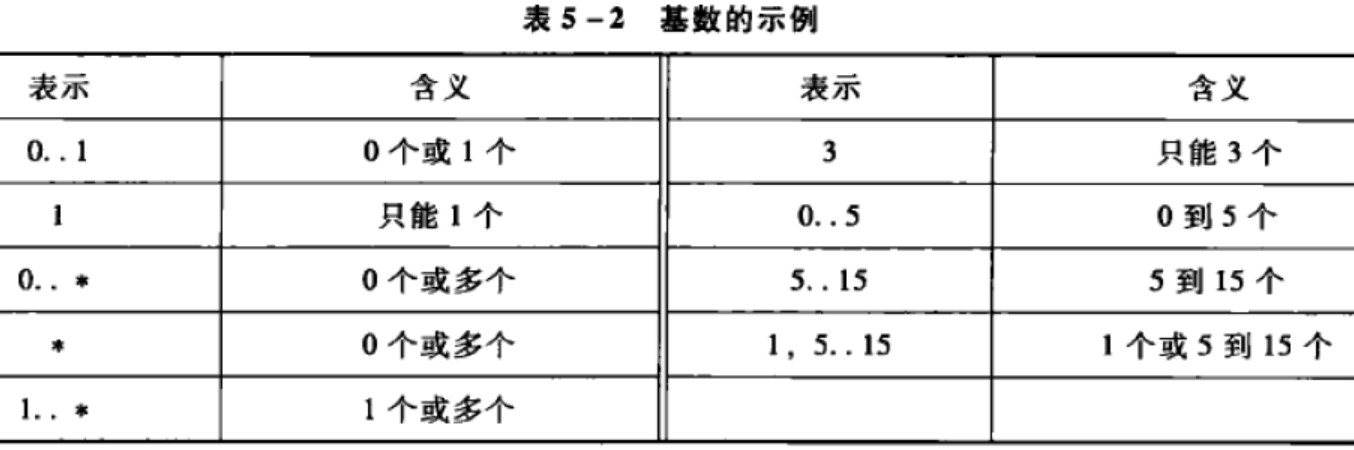
聚合和组合的区别在于整体和部分的生命周期是否独立
- 聚合的整体和部分之间在生命周期上没有什么必然的联系
- 组合关系中,整体与部分是不可分的,整体的生命周期结束也就意味着部分的生命周期结束
时序图
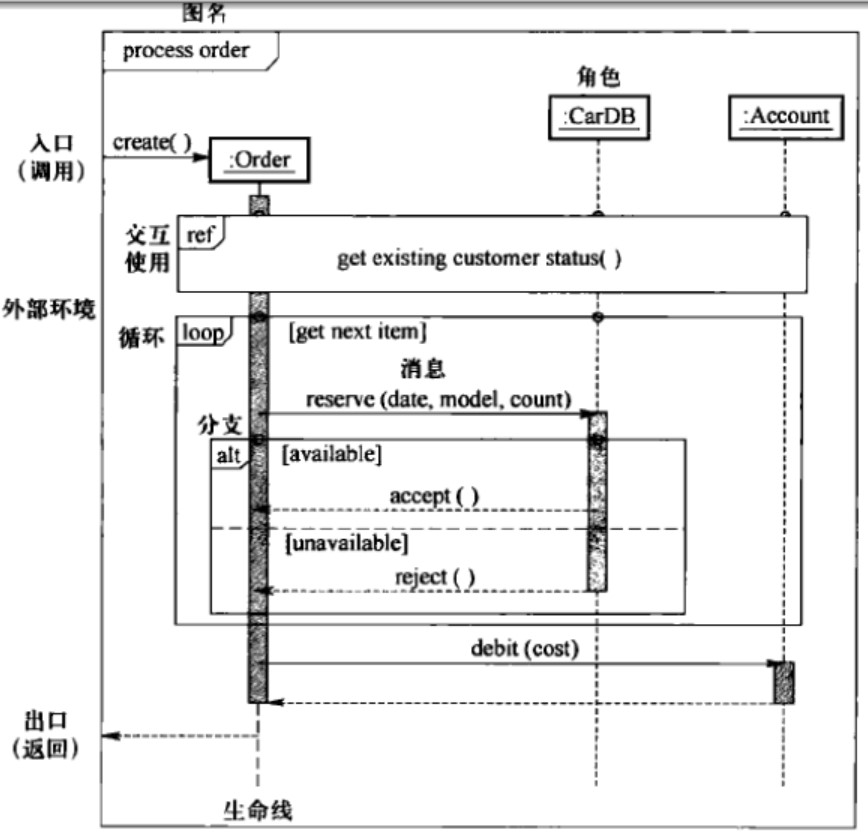
- 交互使用:ref
- 循环:loop
- 条件:alt
- 并发:par
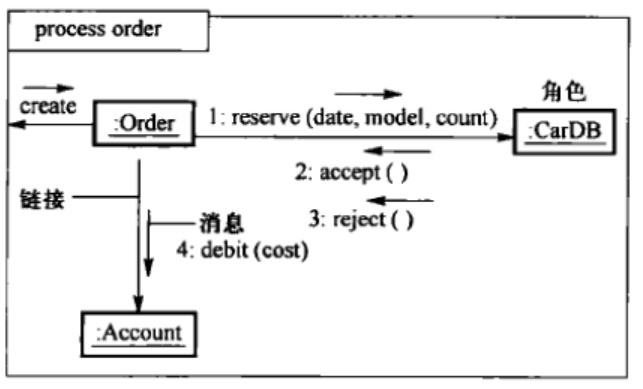
通信图
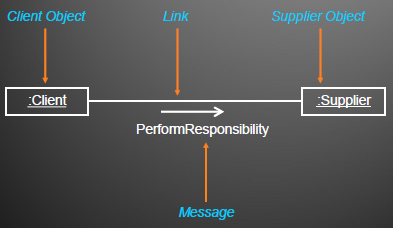
强调发送和接收消息的对象之间的组织结构
两对象对应类之间存在关联关系时,对象之间存在一条通信路径,称为link
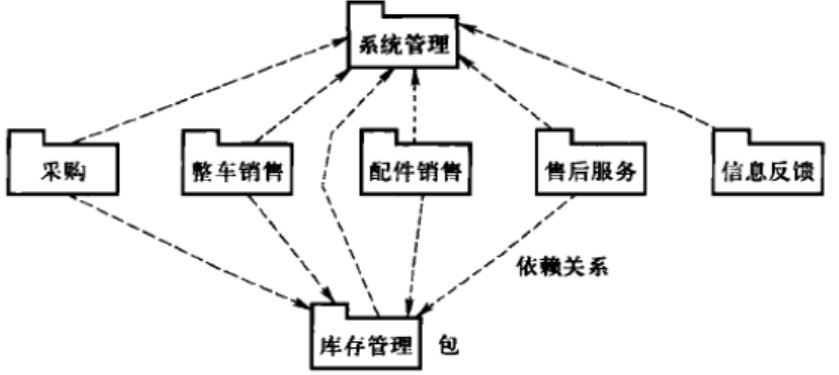
包图
UML提供一种称为包的组织元素
面向对象分析建模
概念
use case技术
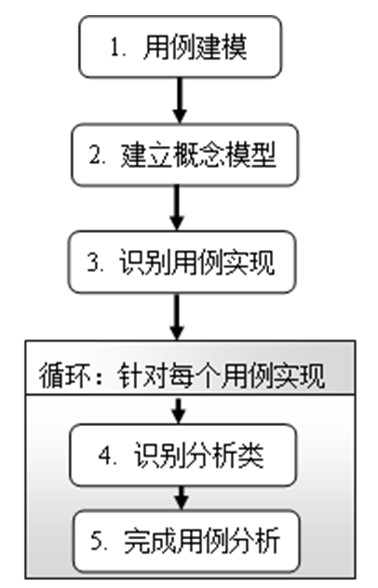
use-case模型,识别actor和use case
建模步骤
用例建模
use-case模型的组成
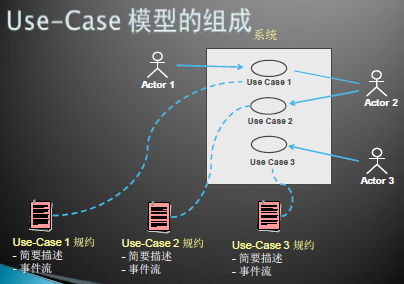
actor
与系统交互的系统外的某些人或某些东西
- 最终用户
- 外界软件系统
- 外界硬件设备
如何识别actor
- 谁需要在系统的帮助下完成自己的任务?
- 需要谁去执行系统的核心功能?
- 需要谁去完成系统的管理和维护?
- 系统是否需要和外界的硬件或软件系统进行交互?
use case
Actor想使用系统去做的事
如何识别use case
每个actor的目标和需求是什么?
- actor希望系统提供什么功能?
- actor 将创建、存取、修改和删除数据吗?
- actor是否要告诉系统外界的事件?
- actor 需要被告知系统中的发生事件吗?
一个用例定义了和actor之间的一次完整对话
用例图
通信-关联
- Actor和use case 间的通信渠道
- 用一条线表示
- 箭头表示谁启动通信
用例规约
- Name
- Brief description
- Flow of Events
- Relationships
- Activity diagrams
- Use-Case diagrams
- Special requirements
- Pre-conditions
前置条件 - Post-conditions
后置条件 - Other diagrams
事件流
执行者与用例之间对话期间发生的基本活动
- 一个基本流
- 执行用例时“通常”会发生的事件
- 从开始到结束的成功的事件流程
- 多个备选流
- 基本事件流的“绕行道”
- 相关的可选或异常特征的行为
- 正常行为的各种变形
每个用例的事件流动作都对应一个活动
用例模型的优化
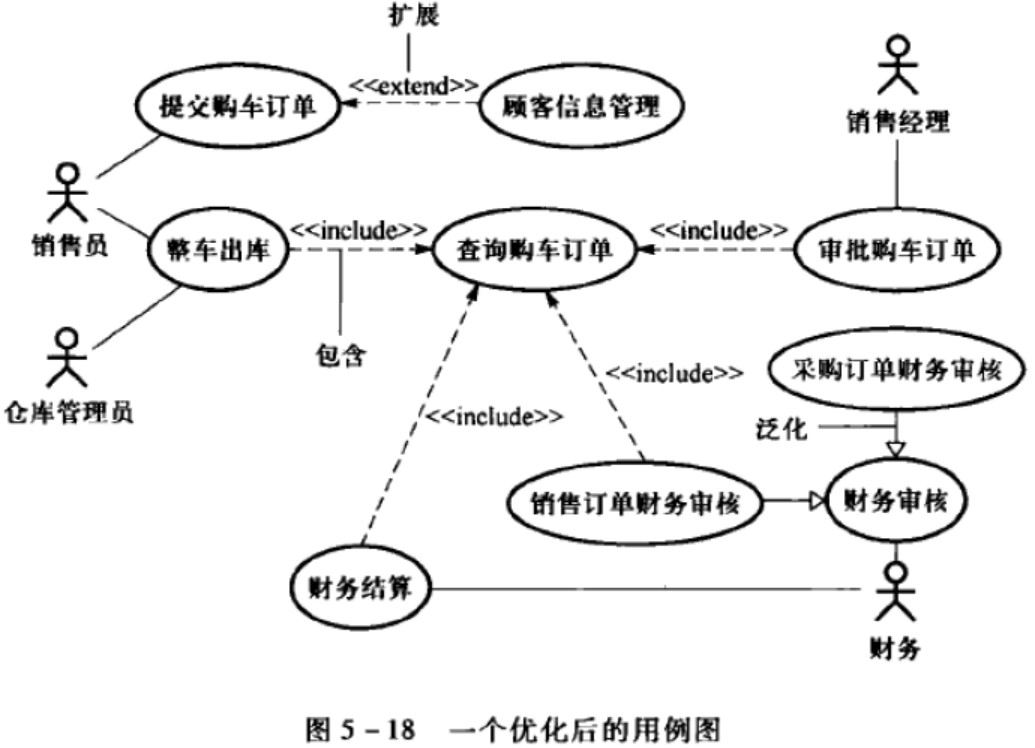
用例间关系
include包含
多个用例存在共同行为,可以分提炼一个新的用例。
执行include:到达插入点时执行包含用例
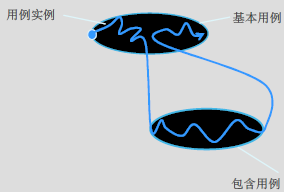
extend扩展
若用例的部分行为是可选的,可分离形成扩展用例
执行extend:当到达扩展点并且扩展条件为真时执行
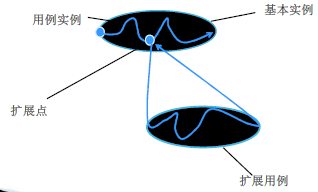
generalization泛化
若多个用例在行为和结构上具有共同点,可以分离出形成父用例
- 在父用例中描述通用的共享的行为
- 在子用例中描述特殊的行为
- 共享共同的目标
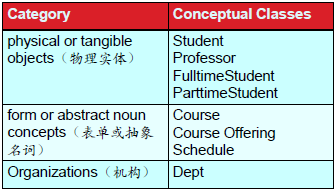
建立概念模型
识别conceptual class
概念类业务和需求建模会揭示系统必须处理的核心概念,它是设计模型的核心要素
Use a conceptual class category list(分类法)
Finding conceptual classes with Noun Phrase(名词提出和过滤法)
- Use use-case flow of events as input
- Underline noun clauses in the use-case flow of events
- Remove redundant candidates
- Remove vague candidates
- Remove actors (out of scope)
- Remove implementation constructs(与实现有关的)
- Remove attributes (save for later)
- Remove operations
Use analysis patterns, which are existing conceptual models created by experts(已有的分析模式)
- using published resources such as Analysis Patterns[Fowler96] and Data Model Patterns [Hay96].
一个错误:把原本是类的实体当作属性来处理.
解决方法:
If X is not a number or text in the real world, X is probably a conceptual class, not an attribute.
建立conceptual class之间的关系
关系种类
- Association(关联)
- Aggregation(聚合)
- Composition(组合)
- Inheritance/Generalization(继承/泛化)
- Dependency(依赖)
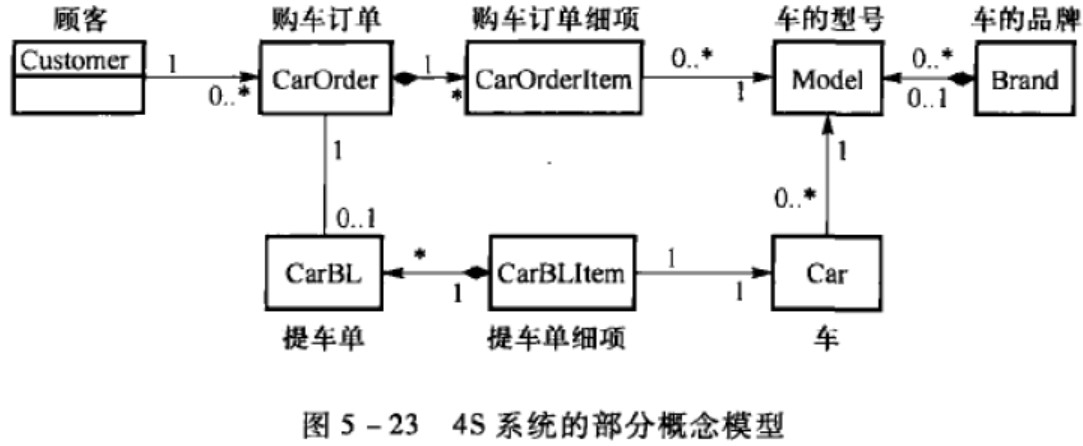
增加conceptual class的属性(画类图)
识别出概念类的主要属性,可以有遗漏,在后续的分析与设计中,这些属性会逐渐补全
同时可以识别出概念类的部分操作。在概念模型中,类的属性比操作更为重要
用例分析
识别出用例实现
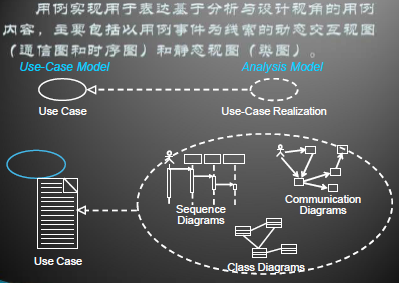
用例实现充当了从以需求为中心到以设计为中心转移的桥梁, 用例与用例实现的关系是依赖关系的衍型《realize 》
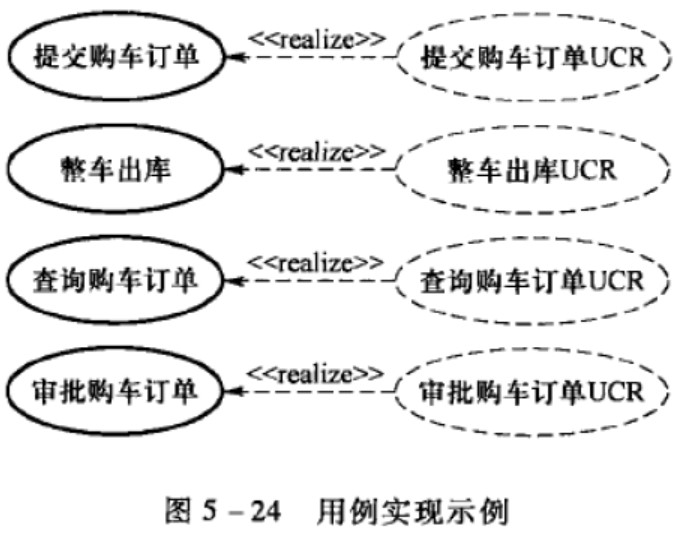
针对每个用例实现
识别出分析类
MVC设计模式
view————边界类boundary
boundary class:The interaction between the external environment and the internal operation of the system
model———实体类entity
entity class 是系统的关键抽象
Store and manage information in the system.
- 用户接口类
- 系统接口类
- 设备接口类
One boundary class per actor/use-case pair
执行者和用例之间的一条通信关联对应一个边界类Use-
control———控制类control
控制类用于描述一个或几个用例所特有的事件流控制行为,如事务管理器、资源协调器和错误处理器
使用或规定若干实体类的内容,协调这些实体类的行为
identify one control class per use case
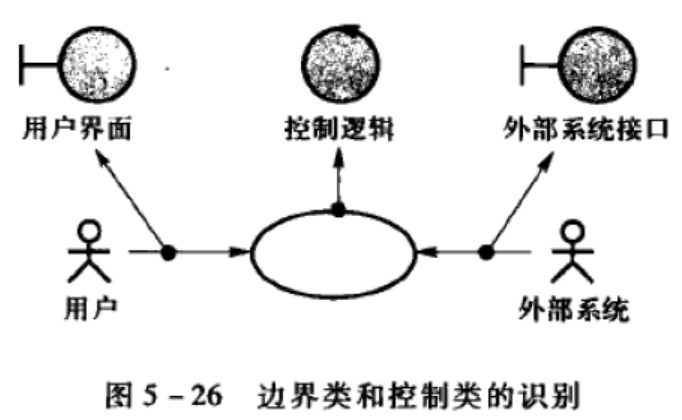
完成用例分析
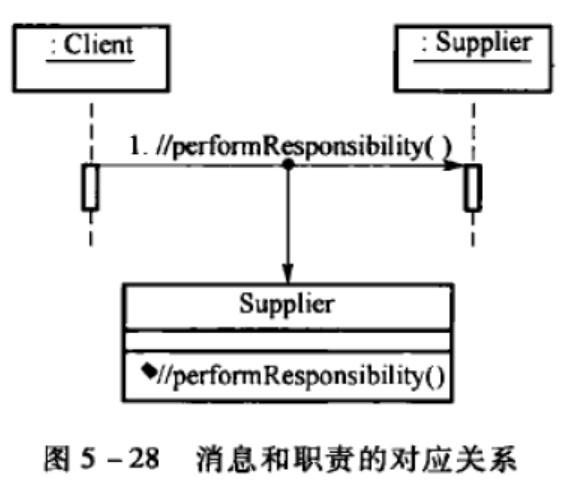
建立时序图,生成通信图
以用例作为研究对象,分析类的实例作为行为载体,通过消息传递的方式对用例场景进行分析,构建出时序图、通信图和类图。
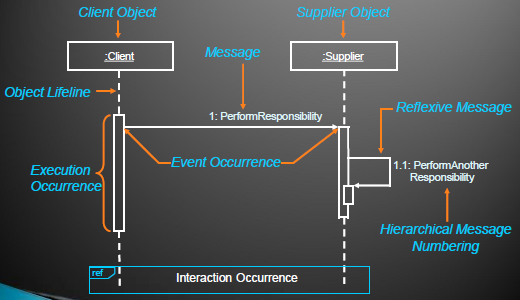
Sequence Diagram
- Time oriented view of object interaction
- The diagram shows:
- The objects participating in the interaction.
- The sequence of messages exchanged.
Communication Diagram
- Structural view of messaging objects
- The communication diagram shows:
- The objects participating in the interaction.
- Links between the objects.
- Messages passed between the objects.
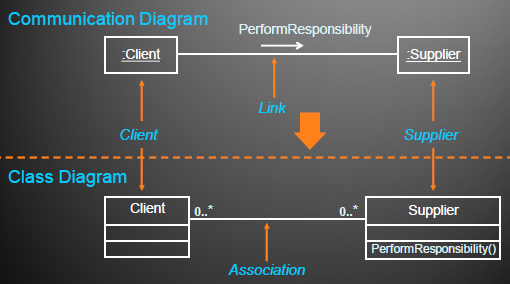
对照通信图建立类图,完善每个分析类的属性和操作
Relationship for every link
补充一:构建对象模型-原文分析法
面向对象分析,就是抽取和整理用户需求并建立问题域精确模型的过程。
发现和改正原始陈述中的二义性和不一致性,补充遗漏的内容,从而使需求陈述更完整、更准确。
抽象出目标系统的本质属性,并用模型准确地表示出来。通过建立分析模型能够纠正在开发早期对问题域的误解。
复杂问题的对象模型的五个层次

对象模型通常由下述5个层次组成: 主题层(Subject)、类与对象层(class-object)、结构层(structure)、属性层(attribute)和服务层(service)
上述5个层次对应着在面向对象分析过程中建立对象模型的5项主要活动:
- 找出类与对象(Finding Class-object)
- 识别结构(Recognising Structure)
- 识别主题(Recognising Subject)
- 定义属性(Defining attribute)
- 定义服务(Defining service)
这5项活动没有必要顺序完成,也无须彻底完成一项工作以后再开始另外一项工作。
设计工程
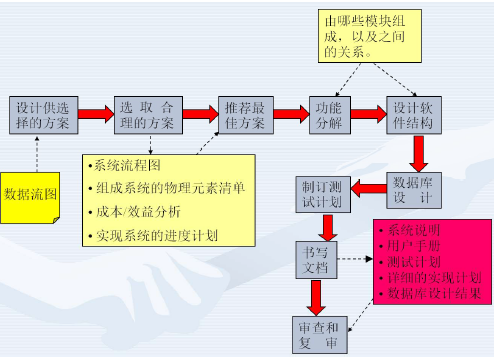
软件设计工程概述
软件设计的两个阶段
架构设计
软件质量属性的设计策略
- 可用性设计
- 可维护性设计
- 性能设计
- 安全性设计
- 可测性设计
- 易用性设计
确定合适的软件架构风格
- 数据流风格(Dataflow):批处理序列、管道-过滤器风格(Pipe-and-Filter)
- 调用/返回风格:主程序/子程序、面向对象风格(ADT)、层次系统(Layered Systems)
- 独立构件风格:进程通信、事件系统
- 虚拟机风格:解释器、基于规则的系统
- 仓库风格:数据库系统、超文本系统、黑板系统
定义软件的主要结构元素——模块
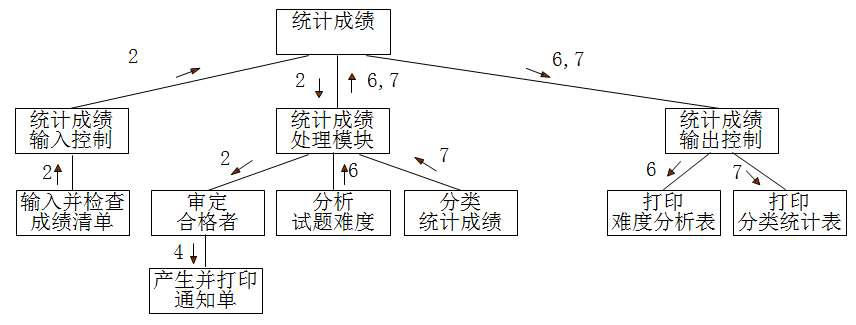
接口设计
- 软件模块间的内部接口
- 模块和协作系统(如外部软件系统、外部设备、网络等)之间的外部接口
- 使用人员和软件的接口(用户界面)
详细设计
- 为所有数据对象定义详细的数据结构
- 为所有在模块内发生的处理定义算法细节、控制流和数据流
软件设计的原则
抽象
- 数据抽象
- 把一个数据对象的定义抽象为一个数据类型名,用此类型名可定义多个具有相同性质的数据对象
- 过程抽象
- 把完成一个特定功能的动作序列抽象为一个过程名和参数表,以后通过指定过程名和实际参数调用此过程
- 对象抽象
- 通过操作和属性,组合了这两种抽象,即在抽象数据类型的定义中加入一组操作的定义,以确定在此类数据对象上可以进行的操作。
分解和模块化
分解(decomposition):控制复杂性的另一种有效方法,软件设计用分解来实现模块化设计。
$C(P_1+P_2) \gt C(P_1)+C(P_2)$
$E(P_1+P_2) \gt E(P_1)+E(P_2)$
C为问题的复杂度,E为解题需要的工作量
模块化(modularity):将一个复杂的软件系统自顶向下地分解成若干模块(module),每个模块完成一个软件的特性,所有的模块组装起来,成为一个整体,完成整个系统所要求的特性。
模块是能够单独命名并独立地完成一定功能的程序语句的集合,例如,过程、函数、子程序、宏、类等模块的两个特征
- 外部特征是指模块跟外部环境联系的接口和模块的功能;
- 内部特征是指模块的内部环境具有的特点,即该模块的局部数据和处理逻辑
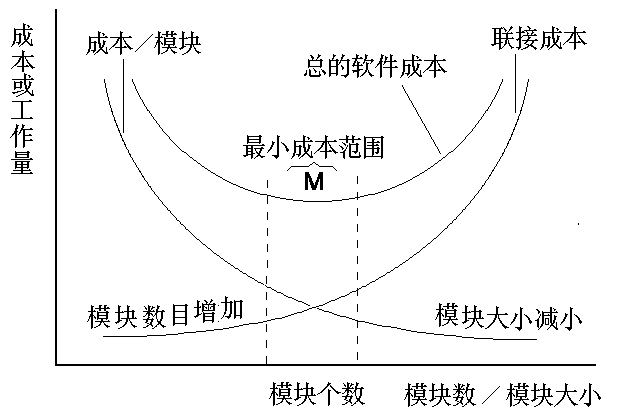
模块化的成本
- 如果模块是相互独立的,当模块变得越小,每个模块花费的工作量越低;
- 但当模块数增加时,模块间的联系也随之增加,把这些模块联接起来的工作量也随之增加。
信息隐藏
每个模块的实现细节对于其它模块来说应该是隐蔽的
模块的独立性
模块的独立性是模块化追求的目标
模块独立的衡量指标
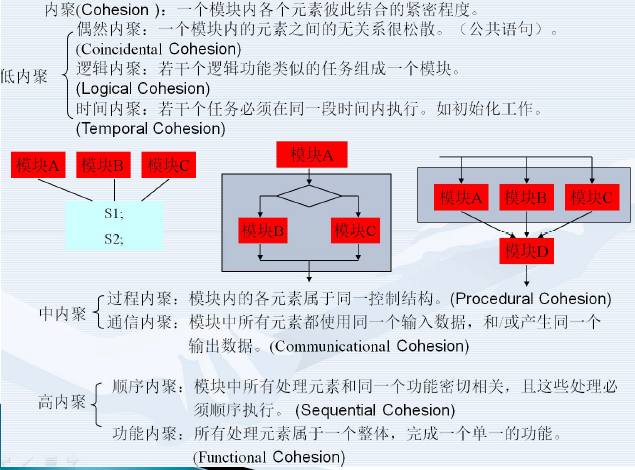
- 内聚(cohesion),是一个模块内部各个元素彼此结
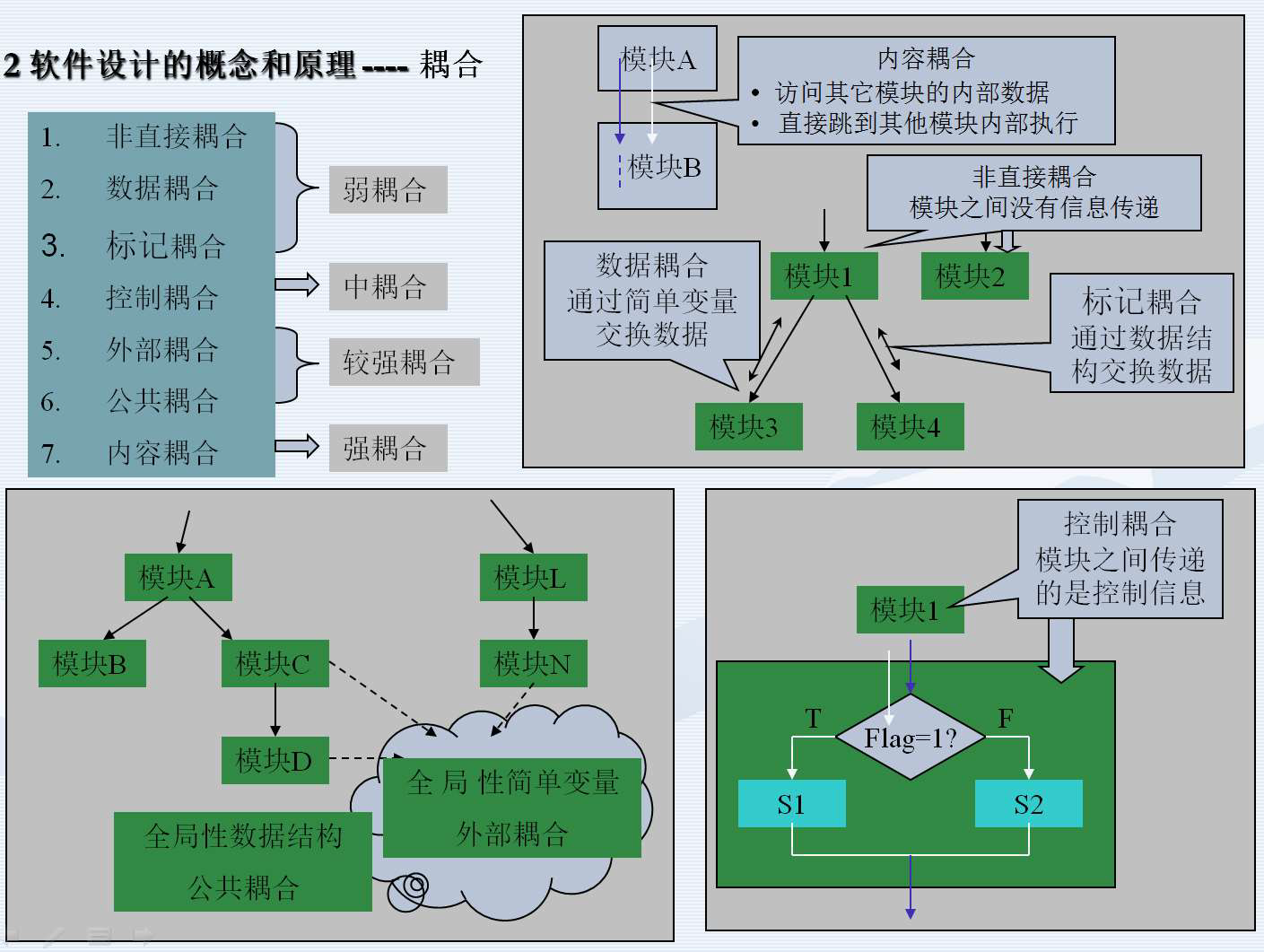
合的紧密程度的度量 - 耦合(coupling),是模块之间的相对独立性(互相
连接的紧密程度)的度量
内聚
偶然内聚coincidental cohesion
逻辑内聚logical cohesion
时间内聚temporal cohesion
过程内聚procedural cohesion
通信内聚communicational cohesion
顺序内聚sequential cohesion
功能内聚functional cohesion
耦合
- 非直接耦合no direct coupling
- 数据耦合data coupling
- 标记(特征)耦合stamp coupling
- 控制耦合control coupling
- 外部耦合external coupling
- 公共耦合common coupling
- 内容耦合content coupling
软件设计的质量
软件设计的质量要求
- 设计应当模块化,高内聚、低耦合。
- 支持多人合作开发
- 易于测试和修改
- 能够以演化过程实现
- 设计应当包含数据、体系结构、接口和构件的清楚的表示。
- 设计应根据软件需求采用可重复使用的方法进行。
- 应使用能够有效传达其意义的表示法来表达设计模型。
7种软件设计的坏味道
- 僵化性(Rigidity)
- 很难对软件进行改动,因为每个改动都会迫使对系统其他部分的许多改动
- 脆弱性(Fragility)
- 对系统的改动会导致系统中和改动的地方在概念上无关的许多地方出现问题
- 牢固性(Immobility)
- 很难解开系统中某部分与其它部分之间的纠结,从而难以使其中的任何部分可以被分离出来被其它系统复用
- 粘滞性(Viscosity)
- 做正确的事情要比做错误的事情困难。表现为两种形式:
- 软件粘滞性
- 需要对软件进行修改时,可能存在多种方法。有的方法可以保持原有的设计质量,另一些方法则会破坏原有的设计质量。如果,破坏软件质量的修改比保持原有设计质量的修改更容易实施时,我们就称该软件具有“软件粘滞性”。
- 环境粘滞性
- 当开发环境迟钝、低效时,就会产生环境粘滞性。
- 例如:如果编译时间很长,那么开发人员可能会放弃那些能保持设计质量,但是却需要导致大规模重新编译的改动。
- 软件粘滞性
- 做正确的事情要比做错误的事情困难。表现为两种形式:
- 不必要的复杂性(Needless Complexity)
- 设计中包含不具有任何好处的基础结构。
- 不必要的重复(Needless Repetition)
- 设计中包含一些重复的结构,这些结构本来可以通过单一的抽象进行统一
- 使用Cut/Copy/Paste实施源代码级的软件复用容易导致这一问题
- 这种代码级别的冗余,将带来修改上的问题
- 设计中包含一些重复的结构,这些结构本来可以通过单一的抽象进行统一
- 晦涩性(Opacity)
- 很难阅读和理解,不要相信你永远都会如此清楚的了解你的每一行代码,“时间会冲淡一切”。要站在阅读者的角度进行设计
软件设计的复用.
模式可重用
每一个模式描述了一个在我们周围不断重复发生的问题,以及该问题的解决方案的核心。这样,你就能一次又一次地使用该方案而不必做重复劳动
在一个上下文中对一种问题的解决方案
设计重用 Design reuse
pattern
architectural style
An architectural pattern (architectural style) expresses a fundamental structural organization schema for software systems. It provides a set of predefined subsystems, specifies their responsibilities, and includes rules and guidelines(指南)for organizing the relationships between them.
design pattern
A design pattern provides a scheme for refining the subsystems or components of a software system, or the relationships between them. It describes a commonlyrecurring(常见) structure of communicating components(组件) that solves a general design problem within a particular context(上下文).
idiom
An idiom is a low-level pattern specific to a programming
language. An idiom describes how to implement particular
aspects of components or the relationships between them
using the features of the given language
framework
- 通用结构: Organize components
- Layers: Organize components into layers where layer’s services are only used by layer i+1.
- Pipes and Filters: Divide the task into several sequential processing steps – the output of task i is the input of task i+1.
- Blackboard: Several independent programs work cooperatively on a common data structure.
- 分布式系统: Handle distributed computation.
- Broker(代理): Introduce a broker component to
achieve better decoupling(降低耦合) of clients and
servers – brokers accept requests from clients and
forward the requests to servers, then return the
results back to the clients. - Client/Server
- 3 Tiers(三层架构)
- Broker(代理): Introduce a broker component to
- 交互式系统: Keep a program’s functional core
independent of the user interface- Model - View - Controller: Divides the application into processing, output, and input. View and controller parts are usually observers of the model via the observer pattern
- Presentation - Abstract - Control: Divides the application up to heirarchies or MVC-like components. Each component is dependent upon and provides functionality for the a higher-level component. There is only one toplevel component
- 自适应系统: Design for change
- Microkernel (微内核)Encapsulate(封装) the fundamental services of the application
- Reflection(反射) Divide the application into a meta-level and a base level to make the application “self-aware”(自意识). The meta level encapsulates knowledge of the system; the base level encapsulates knowledge about the problem domain
- Others:批处理、解释器、进程控制、基于规则
- 通用结构: Organize components
软件体系结构
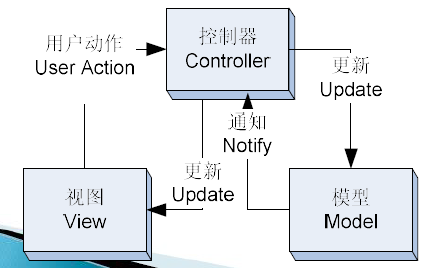
MVC
- 模型Model:管理系统中存储的数据和业务规则,并执行相应的计算功能。
- 视图View:根据模型生成提供给用户的交互界面,不同的视图可以对相同的数据产生不同的界面。
- 控制器Control:接收用户输入,通过调用模型获得响应,并通知视图进行用户界面的更新。
Pipes and Filter
each component has a set of inputs and a set of outputs
A component reads streams of data on its inputs and produces streams of data on its output.
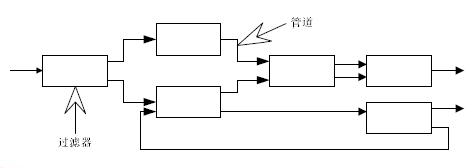
Linux的Shell程序可以看做是典型的管道与过滤器架构的例子
层次架构风格
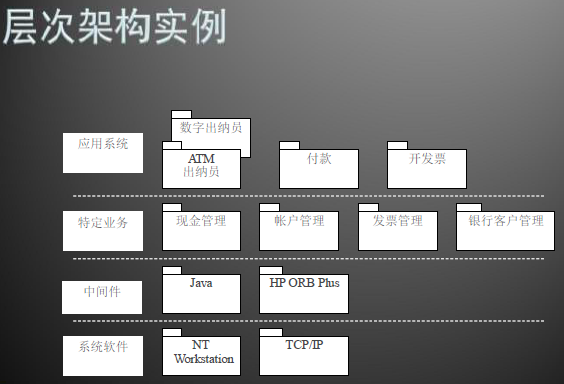
Three Tiers三层架构
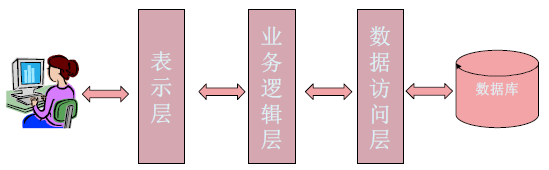
- 表示层:负责向用户呈现界面,并接收用户请求发送给业务逻辑层;
- 业务逻辑层:负责执行业务逻辑以处理用户请求,并调用数据访问层提供的持久性操作;
- 数据访问层:负责执行数据库持久性操作。
黑板风格
黑板架构为参与问题解决的知识源提供了共享的数据表示,这些数据表示是与应用相关的
在黑板架构中,控制流是由黑板数据的状态决定的,而并非按照某个固定的顺序执行。黑板架构的结构包括如下部分:
- 知识源:是指彼此分离独立的与应用相关的知识包,知识源之间的交互都是通过黑板来完成的,它们彼此并不直接交互。
- 黑板数据结构:按照应用相关的层次结构组织而成的问题解决过程中的状态数据。知识源会更新黑板数据,从而增量式地解决问题。
- 控制流:完全有黑板状态驱动,知识源会在黑板数据更新时根据其状态做出相应的响应。
通用结构
黑板架构专门针对没有确定的解决方法的问题,例如信号处理和模式识别,它通过多个知识源的协作来解决问题,而这种协作完全是状态驱动的,因此各个知识源具有公平的机会获取并更新黑板中的状态数据
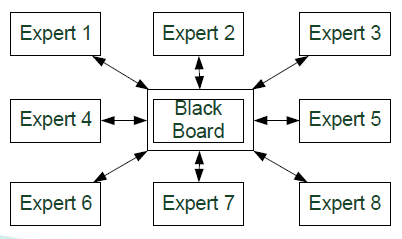
微内核风格
微内核概念来源与操作系统领域。微内核是提供了操作系统核心功能的内核,它只需占用很小的内存空间即可启动,并向用户提供了标准接口,以使用户能够按照模块化的方式扩展其功能。现在大多数操作系统都采用了微内核架构。
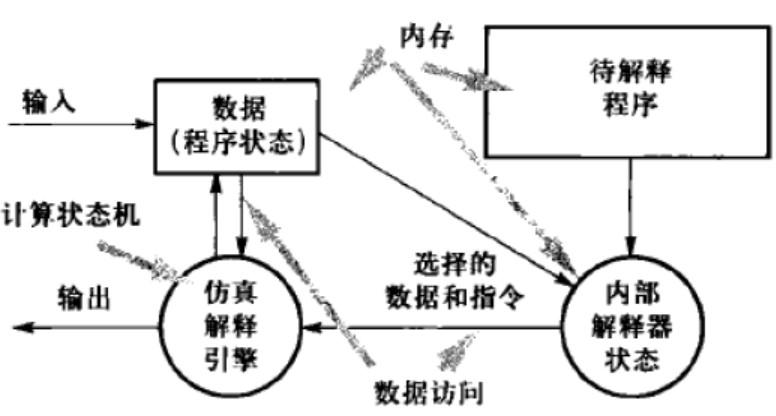
解释器架构
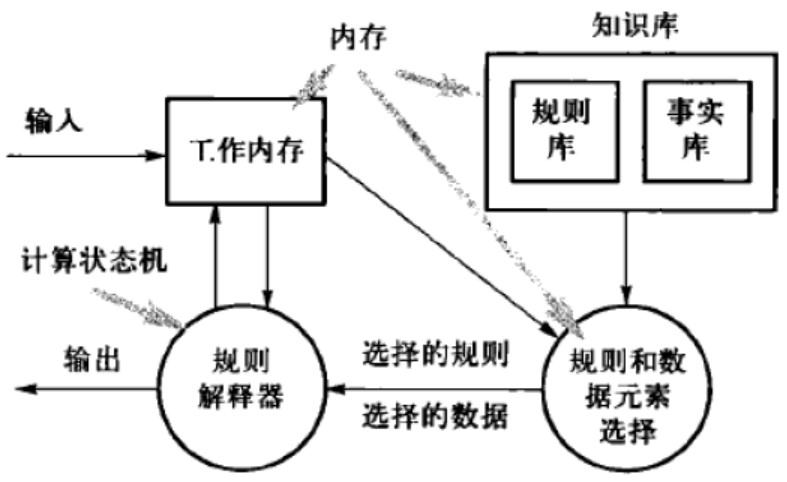
解释器架构用于仿真当前不具备的计算环境,通常包含四个组成部分:用来解释伪码程序的解释引擎、包含待解释程序的内存、解释引擎的控制状态,以及被仿真程序的当前状态:
基于规则的架构
基于规则的架构是一种解释器架构风格,它将人类专家的问题解决知识编码成规则,这些规则在系统执行计算满足指定的条件时被执行或激活,通过规则不断地被执行和激活,最终使得问题被解决。由于这些规则不能被计算机系统直接执行,因此需要通过解释器来解释它们。
设计模式
架构风格是宏观的设计模式,描述高层组织结构
设计模式描述的低成层局部细节,是实现设计复用的有效手段
按作用分类:
创造型(对象创造过程)、结构型、行为型
按作用域分类:
类模式(静态关系)、对象模式(动态关系)
Bridge模式
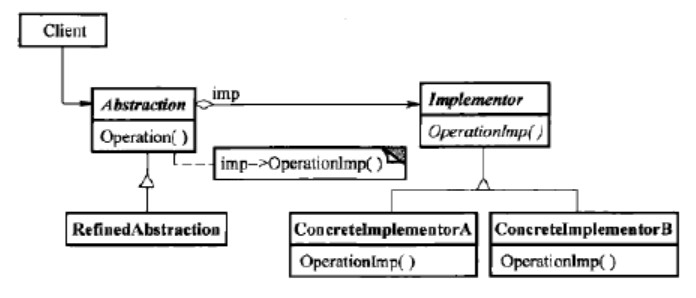
将抽象部分与其实现部分分离,在运行时连接起来(不是编译时绑定),使它们可以独立变化。
框架
框架是一个代码骨架,可以使用为解决问题而设计的特定类或功能来填充这个代码骨架,使之丰满。
人机界面设计
界面设计的原则
- 易学性(Learnability)
- 系统应容易学习和掌握,不应对用户有额外的知识和技能要求。
- 用户可以通过两种途径来学习系统,即:系统的联机手册;系统功能的操作演示及例子。
- 用户熟悉性(User familiarity)
- 界面应以用户导向的名称和观念为主,而不是以计算机的概念为主。这能让用户更快地熟悉系统,使用系统。
- 一致性(Consistency)
- 系统的各个界面之间,甚至不同系统之间,应具有相似的界面外观、布局,相似的人机交互方式以及相似的信息显示格式等。
- 减少意外(Minimal surprise)
- 系统功能和行为对用户应是明确、清楚的。
- 例如:系统有标准的界面;系统不会产生异常的结果,在相同情况下总会有相同的行为;系统有预定的响应时间等。
- 易恢复性(Recoverability)
- 系统设计应该能够对可能出现的错误进行检测和处理,提供机制允许用户从错误中恢复过来。
- 提供用户指南(User guidance)
- 系统应提供及时的用户反馈和帮助功能。
- 用户多样性(User diversity)
- 系统应适应各类用户(从偶然型用户、生疏型用户到熟练型用户,直至专家型用户)的使用需要,提供满足其要求的界面形式。
黄金规则
- 让用户驾驭软件,不是软件驾驭用户
- 减少用户的记忆
- 保持界面的一致性
人机交互方式
- 问答式对话
- 优点:容易使用、学习,软件编程实现容易,用户回答范围小,因此不易出错。
- 缺点:效率不高,速度慢,灵活性差,修改扩充不方便
- 直接操纵
- 示例:可视化编辑器、飞行控制系统和电视游戏等。
- 优点:直接操纵对新手很有吸引力,对知识断层的用户来说是容易记住的,可以快速地执行任务。
- 菜单选择
- 优点:如果术语和菜单项的意义是可理解且明确的,则用户可以用少量的学习或记忆和很少的击键次数来完成任务。界面设计的过程
- 填表
- 在填表时,用户必须理解字段的标题,知道值的允许范围和数据输入方法,能够对出错信息做出反应。
- 对有知识断层的用户或经常性用户来说是最合适的。
- 命令语言
- 对熟练型用户来说,命令语言提供了一个控制和创造性的氛围。用户学习句法并能够迅速地表达复杂的任务,而不必阅读容易分散注意力的提示信息。
- 但这类界面出错率通常比较高,培训是必须的,保持性也比较差,很难提供出错信息和联机求助。
- 自然语言
- 优点:具有用户无需学习训练就能以自然交流方式使用计算机的优点
- 缺点:具有输入冗长文字,自然语言语义有二义性,需要具有应用领域的知识基础以及编程实现困难等缺点。到目前为止,成功案例还比较少。
- 自然语言界面是最理想、最友好的人机界面类型,但是要变为现实,仍有很多工作要做。
界面设计的过程
用户分析
界面设计
界面原型开发
界面评估
用户分类:
- 外行型:不熟悉计算机操作,对系统很少或毫无认识
- 初学型:对计算机有一些经验,对新系统不熟悉,需要相当多的支持
- 熟练型:对系统有丰富的使用经验,能熟练操作,但不了解系统的内部结构,不能纠正意外错误,不能扩充系统的能力
- 专家型:了解系统内部的结构,有系统工作机制的专门知识,具有维护和修改系统的能力,希望为他们提供具备修改和扩充系统能力的复杂界面
界面设计的问题
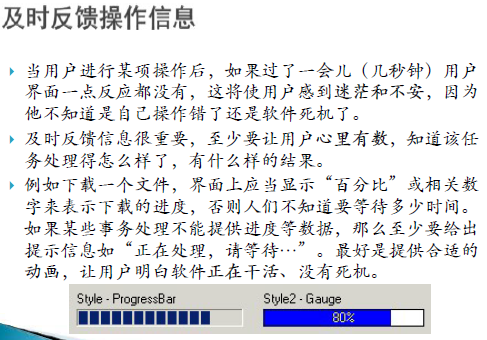
系统响应时间
- 系统响应时间指从用户执行某个控制动作(如按回车键或点鼠标)到软件作出响应(期望的输出或动作)的时间。
- 时间长度:系统响应时间长会使用户感到不安和沮丧。人的一般容忍度为15秒。
- 可变性:稳定的响应时间(如1秒)比不定的响应时间(如0.1秒到2.5秒)要好。用户往往比较敏感,总是关心界面背后是否发生了异常。
帮助设施
- 在系统交互时,是否总能得到各种系统功能的帮助?是提供部分功能的帮助还是提供全部功能的帮助。
- 用户怎样请求帮助?使用帮助菜单、特殊功能键还是HELP命令。
- 怎样表示帮助?在另一个窗口中、指出参考某个文档(不是理想的方法)还是在屏幕特定位置的简单提示。
- 用户怎样回到正常的交互方式?可做的选择有:屏幕上显示返回键、功能键或控制序列。
- 怎样构造帮助信息?是平面式(所有信息均通过关键字来访问)、分层式(用户可以进一步查询得到更详细的信息)还是超文本式。
出错处理
交互系统给出的出错消息和警告应具备以下特征:
- 消息以用户可以理解的术语描述问题。
- 消息应提供如何从错误中恢复的建议性意见。
- 消息应指出错误可能导致哪些不良后果(比如破坏数),以便用户检查是否出现了这些情况或帮助用户进行改正。
- 消息应伴随着视觉或听觉上的提示,也就是说,显示消息时应该伴随警告声或者消息用闪耀方式,或明显表示错误的颜色显示。
- 消息应是“非批评性的”(nonjudgmental),即不能指责用户。
防错处理
在设计界面时必须考虑防错处理,目的是让用户不必为避免犯错误而提心吊胆、小心翼翼地操作。
常见的防错处理措施有:
- 对输入数据进行校验。如果用户输入错误的数据,软件应当识别错误并且提示用户改正数据。
- 对于在某些情况下不应该使用的菜单项和命令按钮,应当将其“失效”(变成灰色,可见但不可操作)或者“隐藏”。
- 执行破坏性的操作之前,应当获得用户的确认。
- 尽量提供Undo功能,用户可以撤销刚才的操作。
菜单和命令交互

可访问性
确保系统界面能让那些身体上面临挑战的用户也易于访问,即,为视觉、听觉、活动性、语音和学习等方面有障碍的用户提供系统的访问机制。
国际化

合理的布局和合理的色彩


结构化设计
结构化设计概述
面向数据流的软件设计过程
结构设计-概要设计
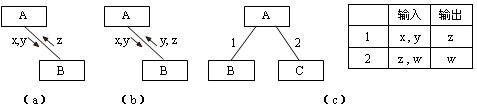
结构设计工具-结构图
模块
一个模块具有其外部特征和内部特征
- 外部特征包括:模块的接口(模块名、输入/输出参数、返回值等)和模块的功能
- 内部特征包括:模块的内部数据和完成其功能的程序代码
调用和数据
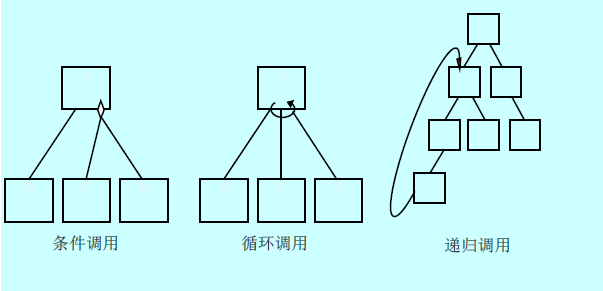
- 调用(call):用从一个模块指向另一个模块的箭头来表示,其含义是前者调用了后者
- 为了方便,有时常用直线替代箭头,此时,表示位于上方的模块调用位于下方的模块
- 数据(data):模块调用时需传递的参数可通过在调用箭头旁附加一个小箭头和数据名来表示
结构图中的辅助符号
数据流图到结构图的映射
结构化设计是将结构化分析的结果(数据流图)映射成软件的体系结构(结构图)
将数据流图分为变换型数据流图和事务型数据流图,对应的映射分别称为变换分析和事务分析
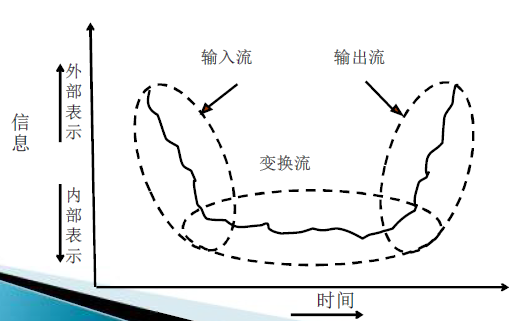
变换流
特征:数据流图可明显地分成三部分
- 输入:信息沿着输入路径进入系统,并将输入信息的外部形式经过编辑、格式转换、合法性检查、预处理等辅助性加工后变成内部形式
- 变换:内部形式的信息由变换中心进行处理
- 输出:然后沿着输出路径经过格式转换、组成物理块、缓冲处理等辅助性加工后变成输出信息送到系统外
变换分析
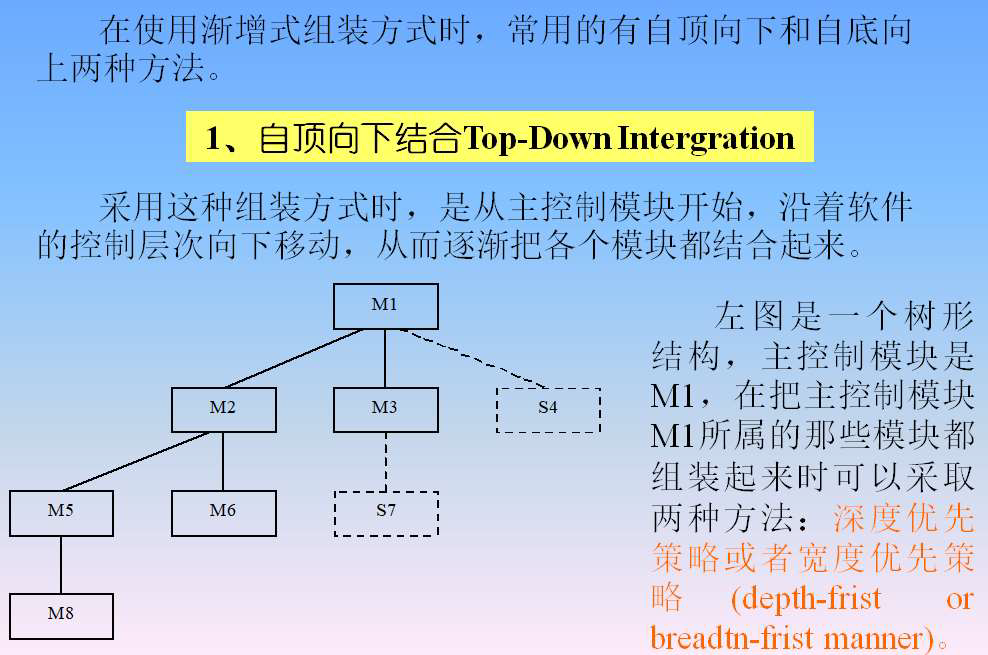
变换分析的任务是将变换型的DFD映射成初始的结构图,步骤如下:
划定输入流和输出流的边界,确定变换中心
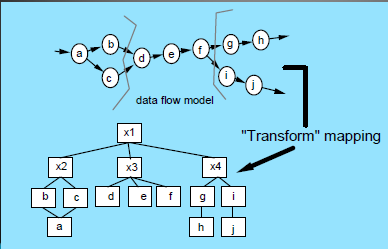
进行第一级分解:将DFD映射成变换型的程序结构
- 将DFD映射成变换型的程序结构
- 大型的软件系统第一级分解时可多分解几个模块,
以减少最终结构图的层次数- 例如,每条输入或输出路径画一个模块,每个主要变换功
能各画一个模块
- 例如,每条输入或输出路径画一个模块,每个主要变换功
e.g.
进行第二级分解:将DFD中的加工映射成结构图中的一个适当的模块
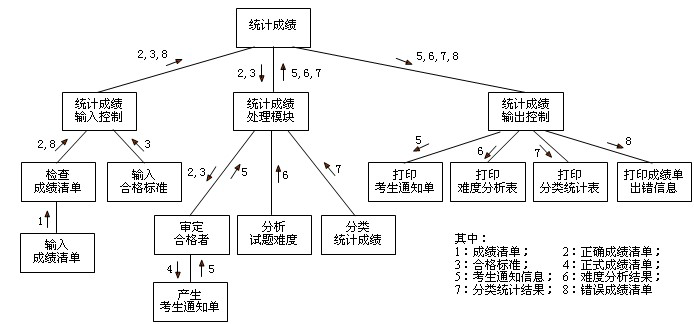
标注输入输出信息:根据DFD,在初始结构图上标注模块之间传递的输入信息和输出信息
事务流
特征:数据流沿着输入路径到达一个事务中心,事务中心根据输入数据的类型在若干条动作路径中选择一条来执行
事务中心的任务是:接收输入数据(即事务);分析每个事务的类型;根据事务类型选择执行一条动作路径
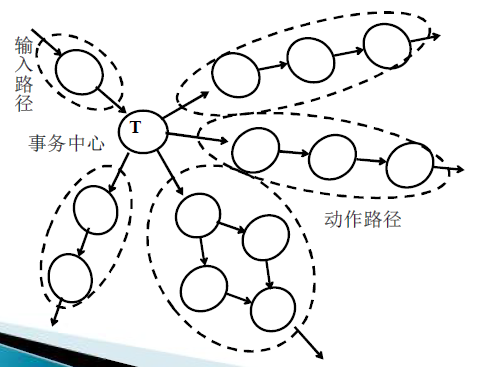
事务分析
将事务型DFD映射成初始的结构图
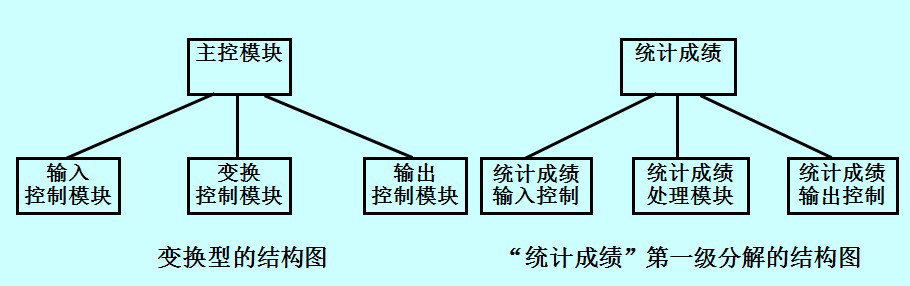
事务型的结构图包括:
- 主控模块:完成整个系统的功能
- 接收模块:接收输入数据(事务)
- 发送模块:根据输入事务的类型,选择一个动作路径控制模块
- 动作路径控制模块:完成相应的动作路径所执行的子功能
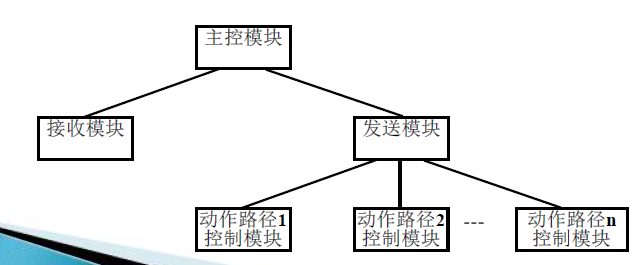
分析步骤
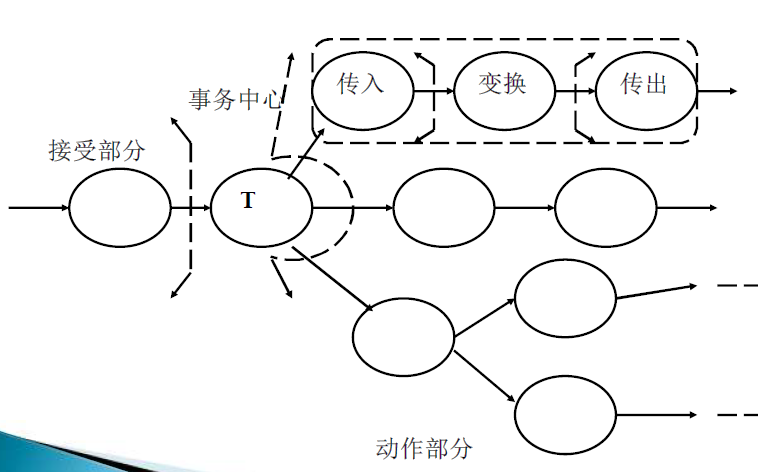
在DFD图上确定边界
- 事务中心
- 接受部分(包括接受路径)
- 发送部分(包括全部动作路径)
画出SC图框架
- DFD图的三个部分分别映射为事务控制模块,接受模块和动作发送模块
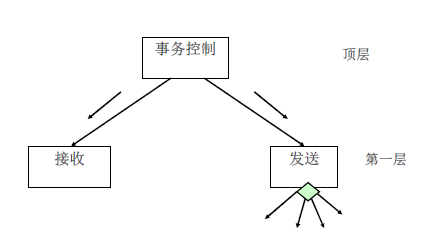
分解和细化接受分支和发送分支
优化结构图
启发式设计策略
- 降低耦合度,提高内聚度
- 避免高扇出,并随着深度的增加,力求高扇入
- 模块的影响范围应限制在该模块的控制范围内
改进技巧
- 减少模块间的耦合度
- 消除重复功能
- 消除“管道”模块
- 模块的大小适中
- 避免高扇出
- 应尽可能研究整张结构图,而不是只考虑其中的一部分
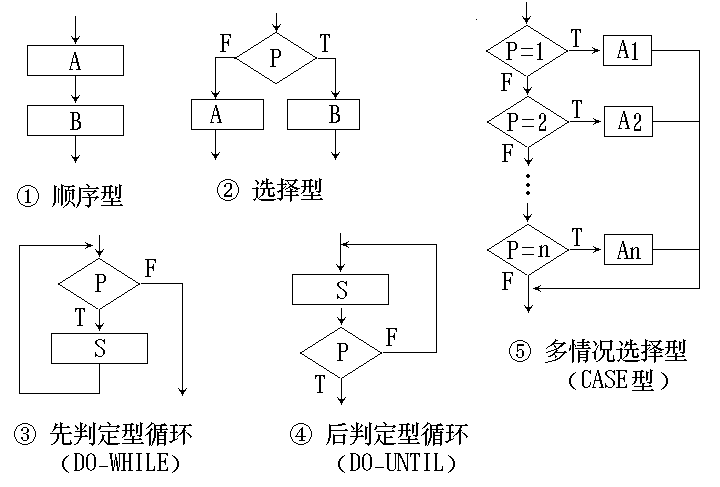
过程设计-详细设计
确定应该怎样具体地实现所要求的系统
- 流程图
- N-S图
- PAD图
- PDL语言
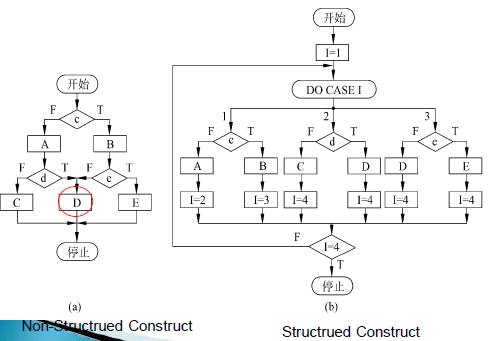
将非结构化程序转换成结构化程序
重复编码技术
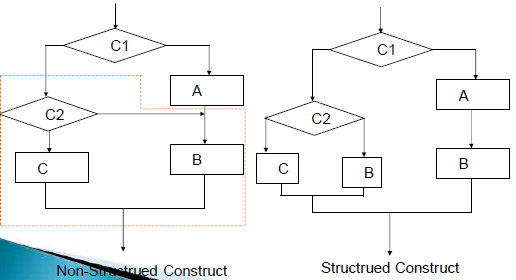
设标志量技术

状态变量法
程序流程图
常用符号
盒图(N-S图)
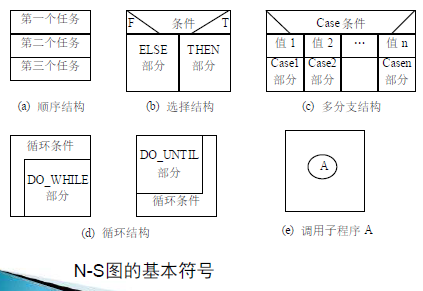
PAD图
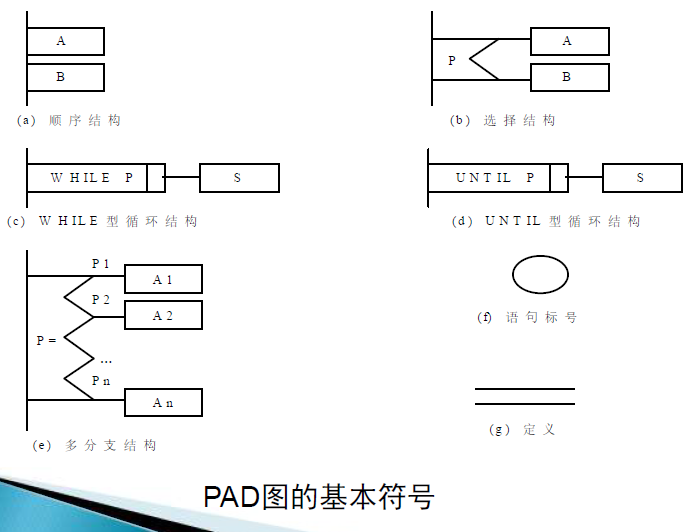
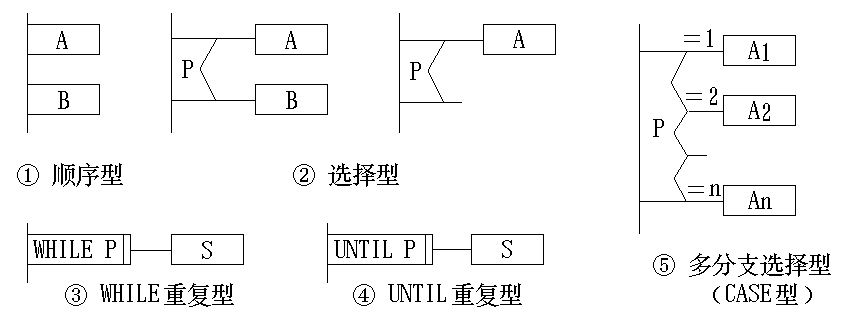
PDL
- PDL是一种用于描述功能模块的算法设计和加工细节的语言。称为设计程序用语言。它是一种伪码。
- 伪码的语法规则分为“外语法”和“内语法”。
- PDL具有严格的关键字外语法,用于定义控制结构和数据结构,同时它的表示实际操作和条件的内语法可使用自然语言的词汇。
面向对象设计
设计模型和分析模型
设计模型的元素很多都是在分析模型中使用的UML图。差别在于这些图被精化和细化为设计的一部分,并且提供了更多的与实现相关的特殊细节,突出了架构的结构和风格、架构内存在的构件以及构件和外界之间的接口。
面向对象设计模型
UML相关模型图
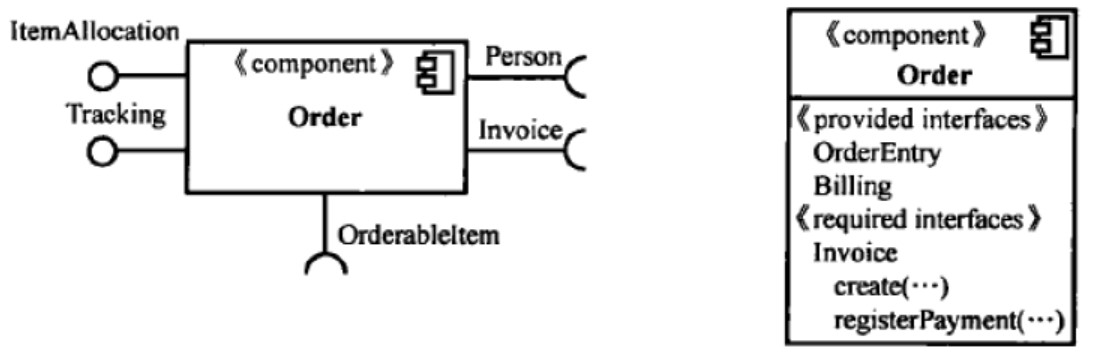
构件图
构件是比类的封装粒度更大的软件重用结构,并通过接口向构件的用户提供服务。
- 内部类以紧耦合方式完成相对独立的功能;
- 有明确的供给接口和需求接口;
- 构件是可配置的;
- 构件是可组装的;

部署图
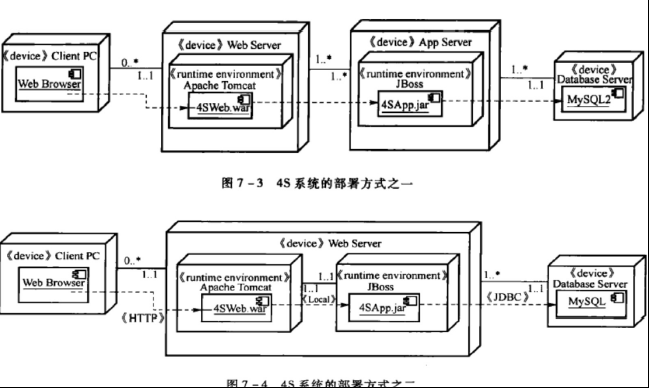
软件的部署方案定义了系统的执行架构,即将软件制品分配到不同的节点上运行
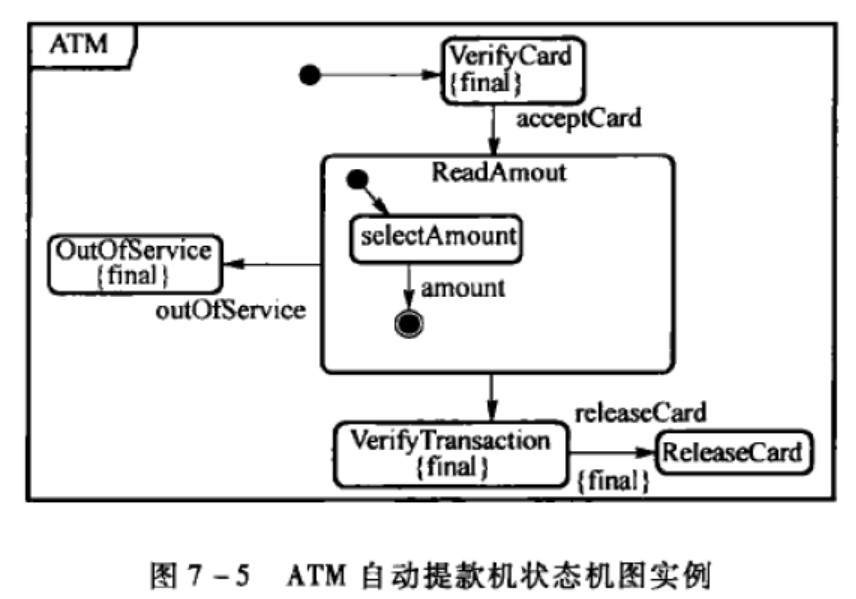
状态机
描述类的行为特性。
核心元素:状态、转移、事件
架构设计
架构设计的4+1视图:场景视图、逻辑视图、物理视图、流程视图和开发视图 - 知乎 (zhihu.com)
架构设计4+1视图的作用与关系 - 知乎 (zhihu.com)
4+1架构视图
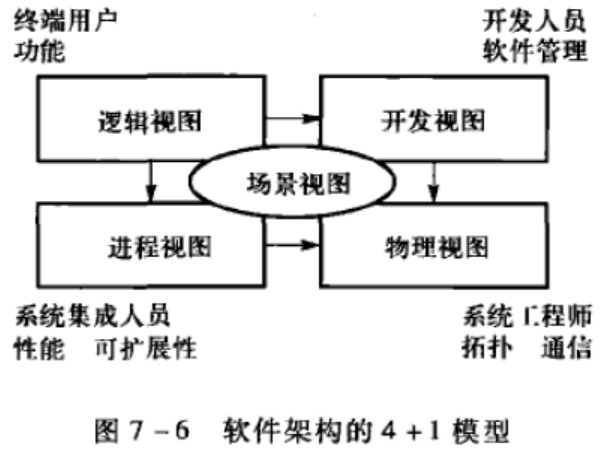
逻辑视图设计
Logical view
软件的逻辑结构,用于支持功能性需求。
进程视图设计
process view
软件的进程架构,针对非功能性需求
构成进程的任务是彼此相互分隔的控制线程,这个软件被划分成这样一组彼此独立的任务。(部署图)
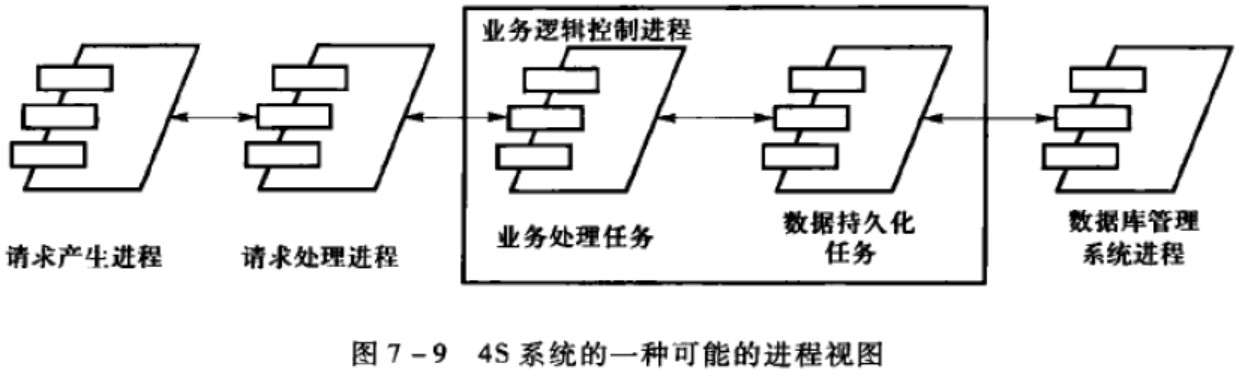
process和thread
process
- Provides heavyweight flow of control
- Is stand-alone
- Can be divided into individual threads
thread
- Provides lightweight flow of control
- Runs in the context of an enclosing process
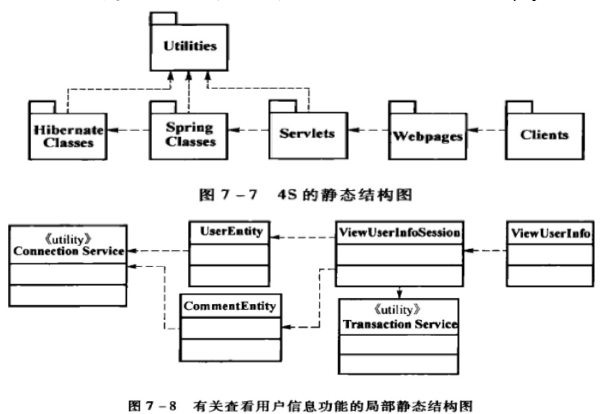
开发视图设计
implementation view/实现视图
软件的开发架构,即如何分解成实现单元,是需求分配的基础也是开发组织结构的基础。
如图水平分割方案,6个包分配给6个开发组且处于架构的不同层次,开发组可按技术层次分配人员。
下图垂直分割方案,按业务逻辑在多个开发组分配任
务,每个开发组必须具备综合开发能力。
物理视图设计
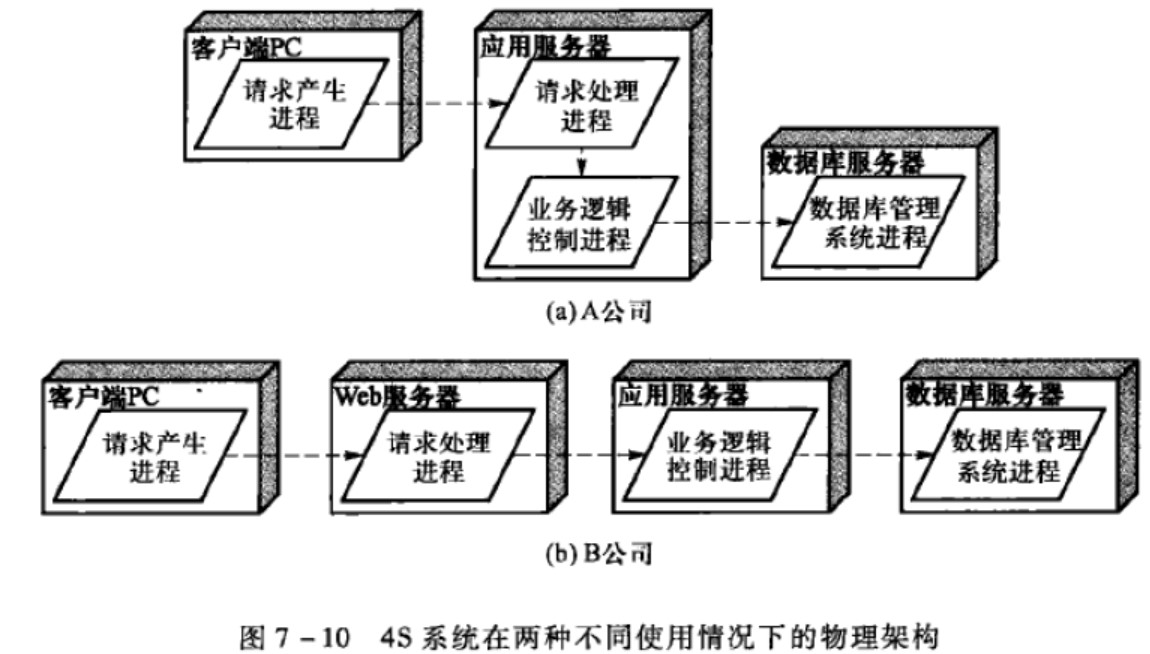
deployment view/部署视图
软件的物理架构,针对非功能性需求的可用性、可靠性、可扩展性等。(部署图)
场景视图设计
use-case view
场景是用例的实例,将4个视图有机第联系起来。它是发现架构元素的动力,担负起验证和说明的角色
需要多少视图?
- 简化模型
- 不是所有系统都需要上面的所有视图
- 单处理器:无需物理视图/部署视图
- 单进程:无需进程视图
- 小项目:无需实现视图
- 添加视图
- 数据视图
- 安全视图
包和子系统设计
类与包
类
A description of a set of objects that share the same responsibilities, relationships, operations, attributes, and semantics
包
A general purpose mechanism for organizing elements into groups
A model element which can contain other model elements
包设计原则
- 重用-发布等价:重用粒度等于发布粒度;
- 共同重用:包中所有类一起被重用;
- 共同封闭:包中的所有类对同类型的变更封闭;
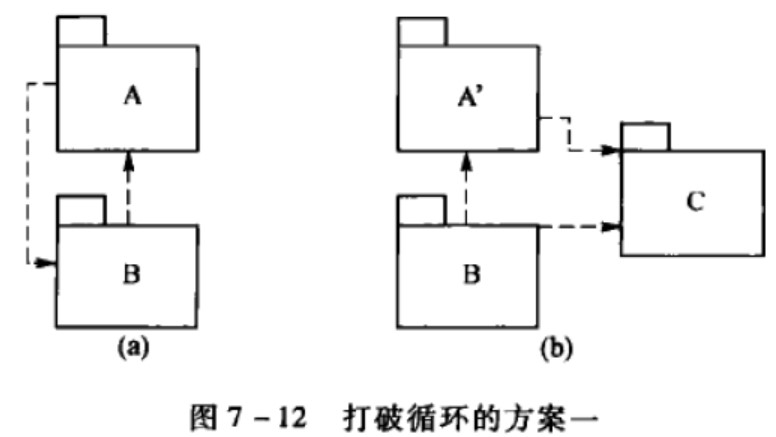
- 无环依赖:包之间无环依赖结构;
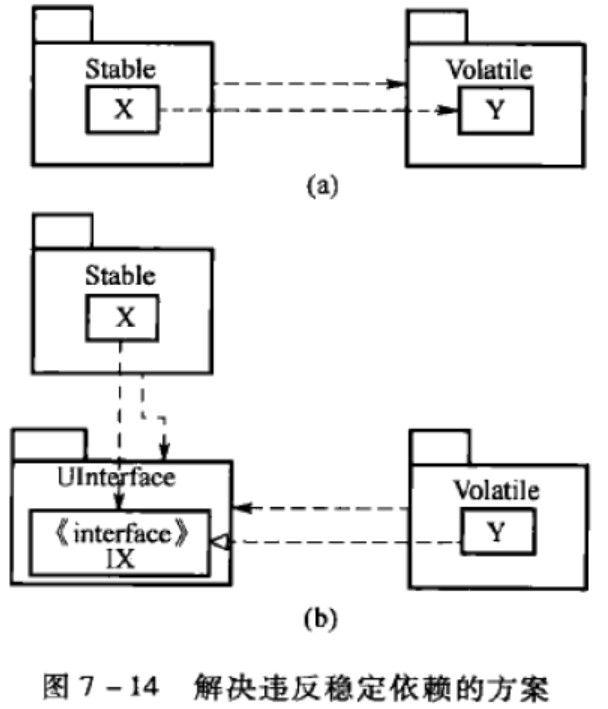
- 稳定依赖:包应该依赖比他更稳定的包;
- 稳定抽象:最稳定的包即最抽象,不稳定包是具体包。
子系统与接口
接口
Realizes one or more interfaces that define its behavior
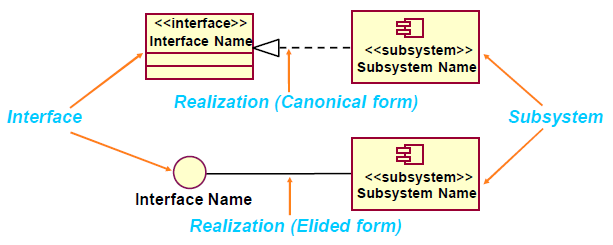
子系统
- 完全封装行为
- 使用清晰的接口实现独立的功能
- 对多个实现变体进行建模
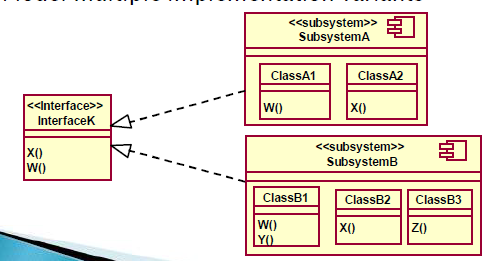
包与子系统
- 子系统
- 提供行为
- 完全封装内容
- 能够轻易被替换
- 包
- 不提供行为
- 不完全封装内容
- 可能不能被轻易替换
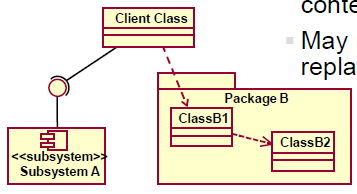
子系统的使用
- 子系统能够被用于将系统拆分成多个独立的部分
- ordered, configured, or delivered
- 可开发的,只要接口保持不变
- 在一串分布式计算节点上部署
- 更改不破坏系统的其他部分
- 也能被用于:
- 将系统拆分为可以对关键资源提供限制安全的单元
- 在设计中表现现有产品或外部系统
类设计
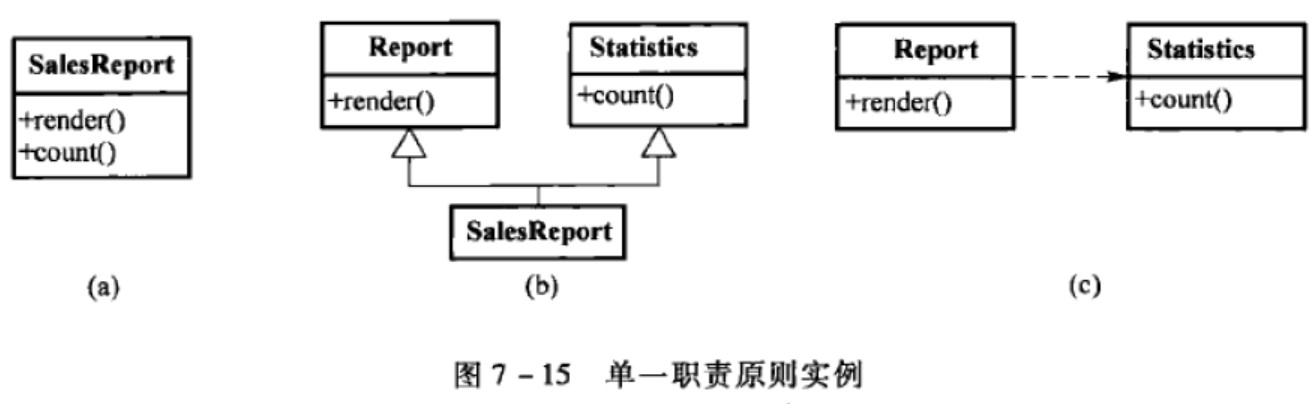
单一职责
里氏替换
[面向对象基础设计原则:3.里氏替换原则 - 知乎 (zhihu.com)](https://zhuanlan.zhihu.com/p/158386715#:~:text=里氏替换原则(The Liskov Substitution,Principle,LSP)是由Barbara Liskov女士于1988年提出的,其定义为:“如果对于类型S的每个对象O1存在类型T的对象O2,那么对于所有定义了T的程序P来说,当用O1替换 O2并且S是T的子类型时,P的行为不会改变”。)
如果对于类型S的每个对象O1存在类型T的对象O2,那么对于所有定义了T的程序P来说,当用O1替换 O2并且S是T的子类型时,P的行为不会改变

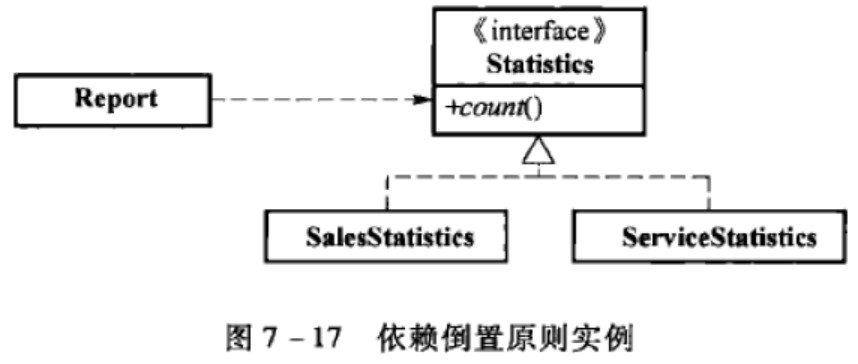
依赖倒置
接口隔离
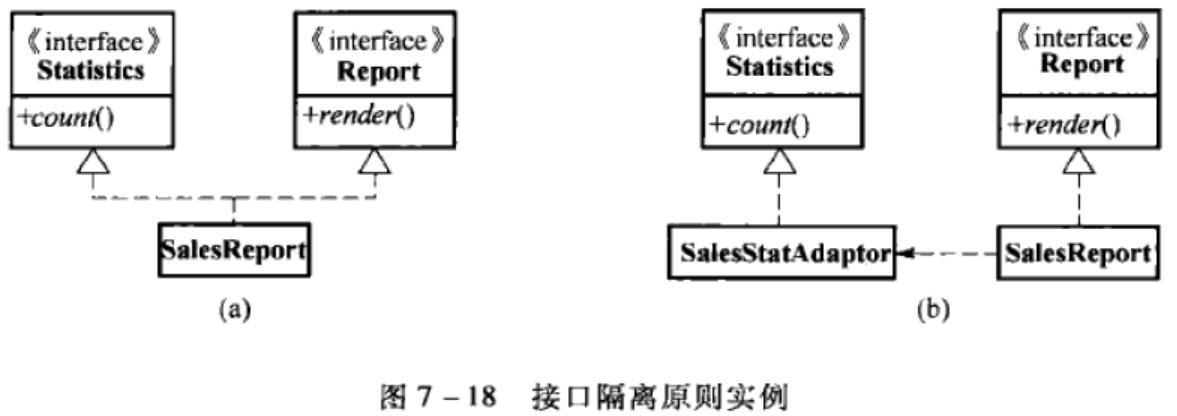
开发-关闭原则
持久化设计
- 实体对象建模;
- 数据库设计;
- 持久化框架。
面向对象设计过程
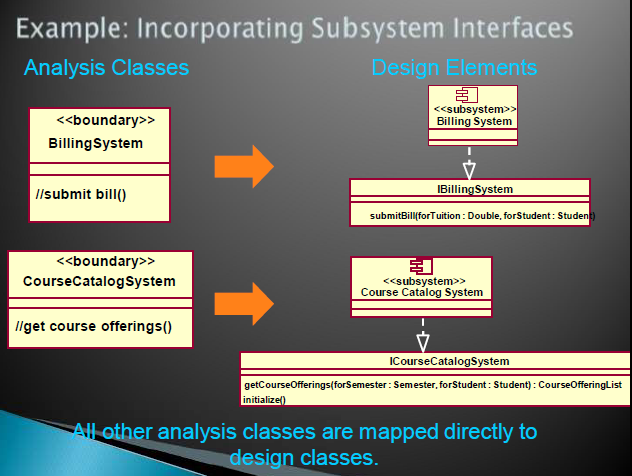
从分析类到设计元素
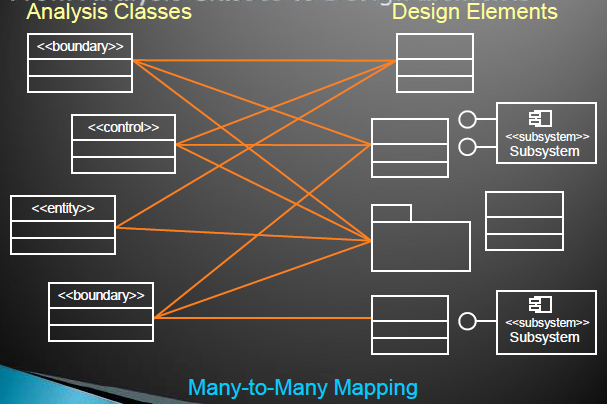
识别设计元素
- 如果满足以下要求,一个分析类直接映射到一个设计类
- 一个简单类
- 表示单一的逻辑抽象
- 更复杂的分析类
- 拆分成多个类
- 成为一个包
- 成为一个子系统
- 参与组合
候选子系统
- 分析类可能演变成子系统
- 类提供复杂服务或者工具
- 边界类(用户接口和外部系统接口)
- 设计中现有的产品和外部系统
- 通讯软件
- 数据库连接支持
- 类型和数据结构
- 共有的工具
- 特定应用产品
子系统设计过程
- 对子系统职责进行定义,即接口的定义;
- 通过职责分配确定子系统中的元素,由构件等元素来实现职责;
- 对子系统中各元素进行设计,即类设计(静态结构和动态结构);
- 确定子系统间的依赖关系。
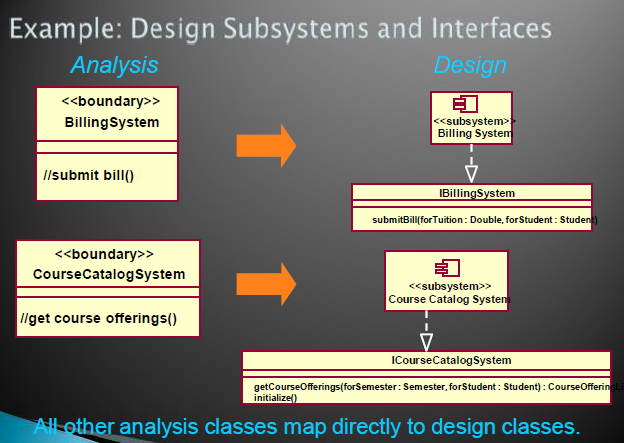
确定架构风格,设计整体结构
识别架构风格
- layers
- model-view-controller(MVC)
- pipes and filters
- blackboard
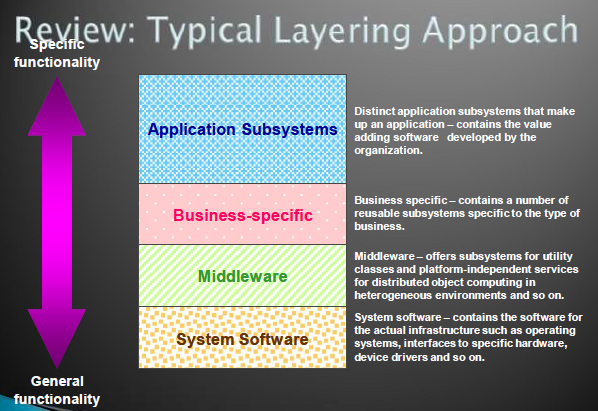
对架构层级建模
Architectural layers can be modeled using stereotyped packages.

对设计元素进行分层和分包
- Partitioning Considerations
- Coupling and cohesion
- User organization
- Competency and/or skill areas
- System distribution
- Secrecy
- Variability
持久化设计模式
- Describe Persistence-Related Behavior
- Modeling Transactions
- Writing Persistent Objects
- Reading Persistent Objects
- Deleting Persistent Objects
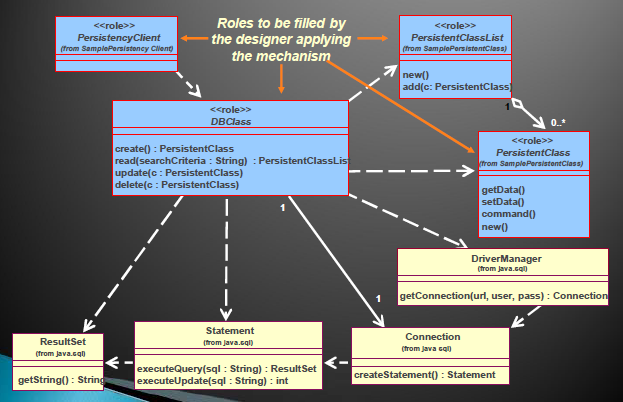
构件级设计
更新use-case Realization
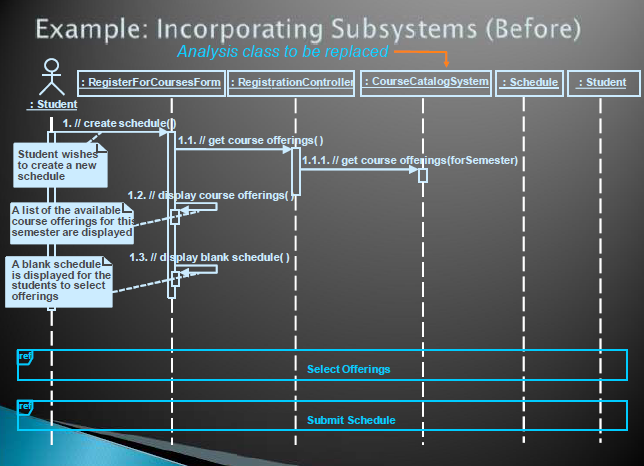
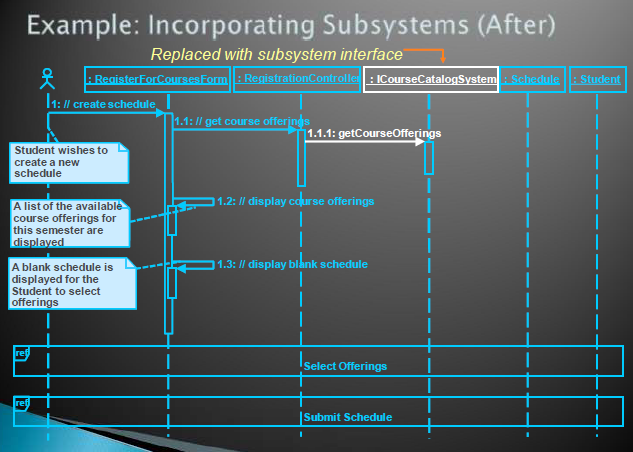
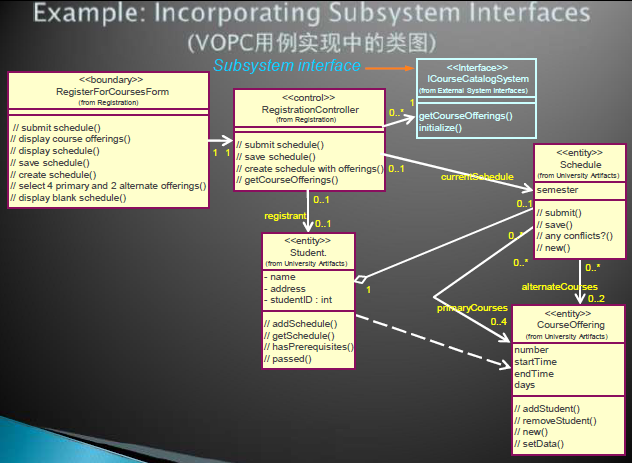
encapsulating subsystem interactions
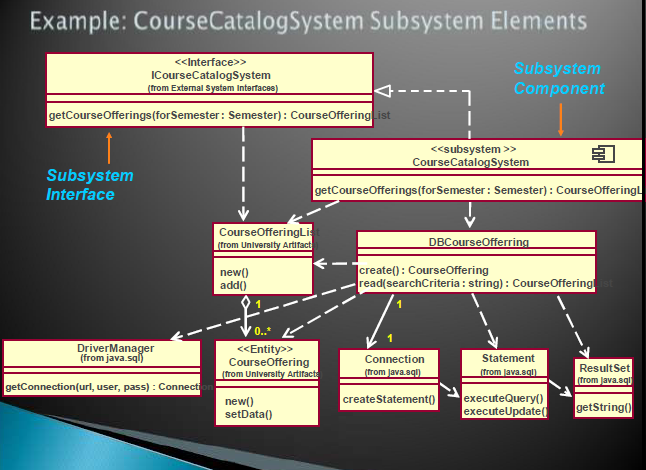
子系统的设计
类似于系统的设计,对每个接口的每个操作设计交互图和VOPC类图
类的设计
- 创建设计类:将分析类映射成设计类;
- 定义操作:实现单一的职责;
- 定义方法:对操作的内部实现进行描述;
- 定义状态:描述对象的状态对行为的影响,将对象的属性和操作关联起来;
- 定义属性:包括方法中的参数、对象的状态等;
- 定义依赖:类与类之间的存在关系,非结构关系;
- 定义关联:对关联关系的细化,包括聚合与组合、导向性、多重性、关联类;
- 形成设计类的规格说明书。
优化UI类
UI边界类
优化Control类
- 是否该被拆分
优化entity类
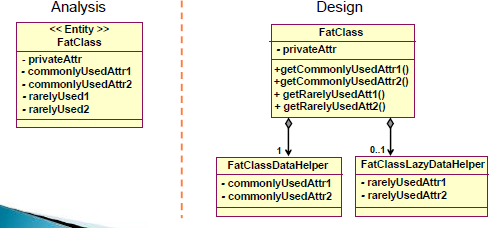
定义操作符号

画出时序图
从用例事件流中提取出各类事件并确定事件交互行为的发送对象和接受对象,用时序图把事件序列以及事件与对象的关系表示出来
画出状态机图
- 状态图描绘事件与对象状态的关系。当对象接受了一个事件以后,引起的状态改变称为“转换”。
- 用一张状态图描绘一类对象的行为,它确定了由事件序列引出的状态序列。仅考虑具有重要交互行为的那些类。
- 事件跟踪图中入事件作为状态图中的有向边(即箭头线),边上标以事件名。两个事件之间的间隔就是一个状态。
- 事件跟踪图中的射出的箭头线,是这条竖线代表的对象达到某个状态时所做的行为(往往是引起另一类对象状态转换的事件)。
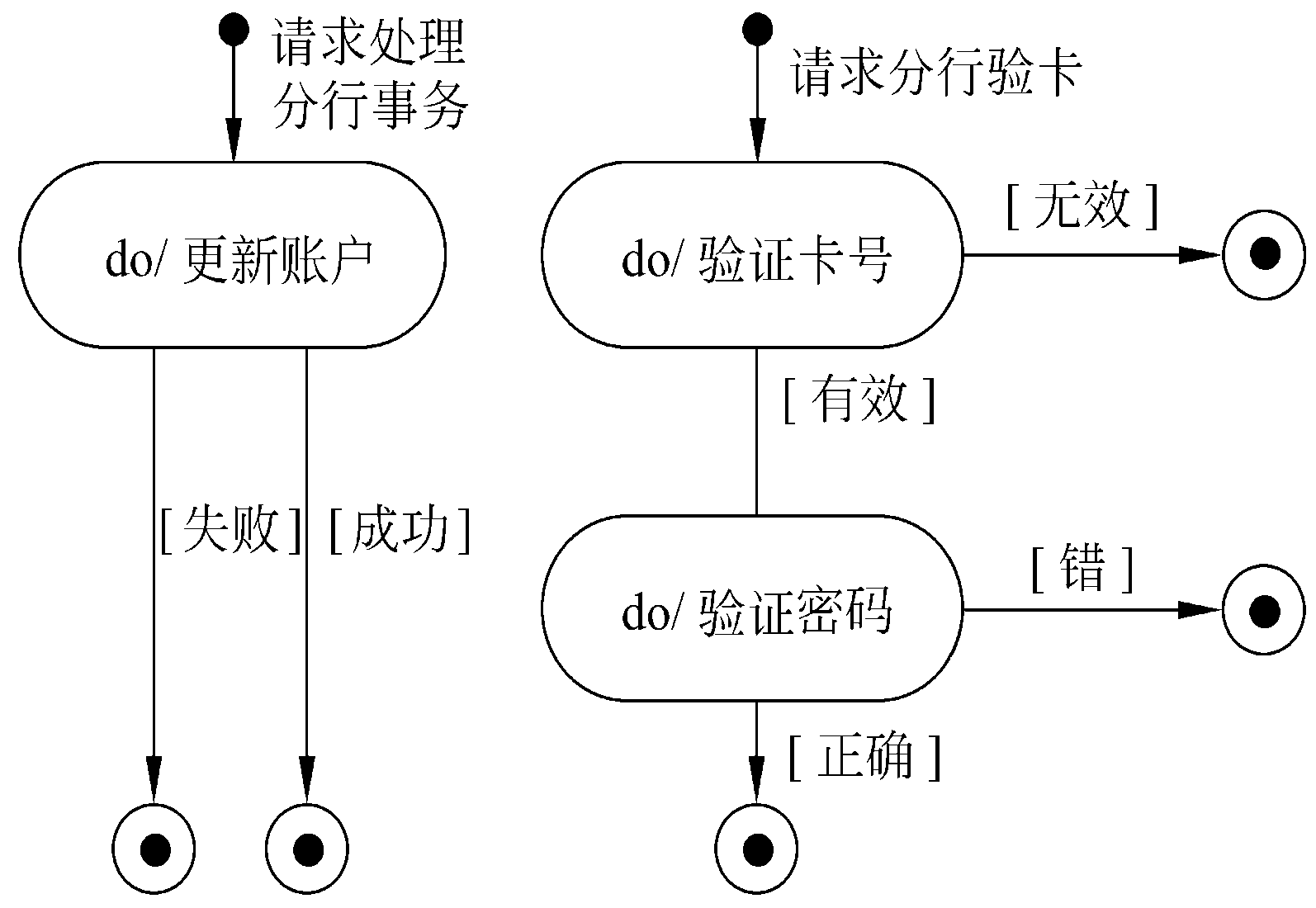
什么对象拥有显著状态
- 角色由状态转换声明
- 状态控制的复杂用例
属性表达
- 特定姓名、种类、选择性缺省值
- 命名规则
- 类型应是实现语言的基本数据类型
- 权限控制
- public:+
- private:-
- protected:#
关联类设计
双向工程
软件测试
测试概述
- 测试(testing)的目的
- 发现软件的错误,从而保证软件质量
- 成功的测试
- 发现了未曾发现的错误
- 与调试(debugging)的不同在哪?
- 定位和纠正错误
- 保证程序的可靠运行
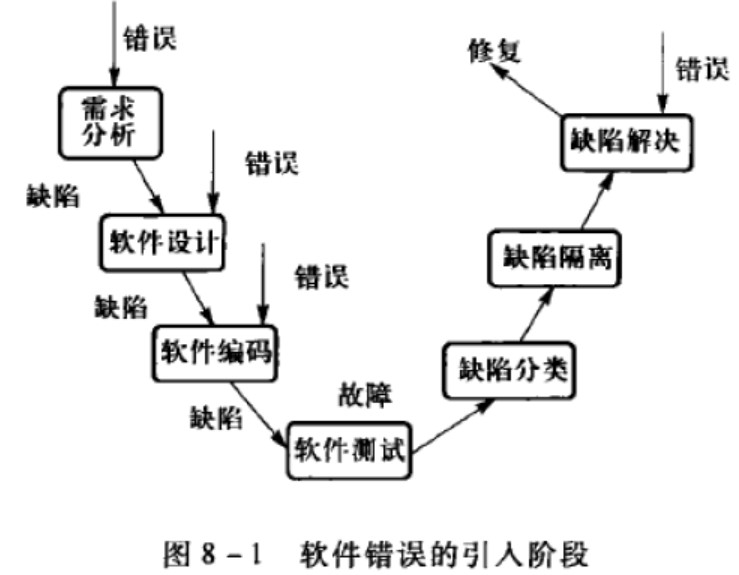
软件引入错误阶段
测试准则
- 所有的软件测试应追溯到用户的需求
- 穷举测试是不可能的
- 根据软件错误的聚集性规律,对存在错误的程序段应进行重点测试
- 尽早地和不断地进行软件测试
- 避免测试自己的程序
- 制定测试计划,避免测试的随意性
- 测试应该从小到大
黑盒测试不可能实现穷尽测试
白盒测试也不可能实现穷尽测试
测试组的组成
- 测试经理/测试组长
- 测试工程师
- 测试开发工程师
- 测试工程师
测试策略
- 按测试层次分类
- 单元测试、集成测试、系统测试
- 按软件质量属性分类
- 功能性测试、可靠性测试、易用性测试、性能测试、可移植性测试、可维护性测试
- 其他测试策略
- 验收测试、α测试、β测试、安装测试、回归测试
测试层次
- 单元测试(Unit testing)
- 集成测试(Integration testing)
- 系统测试(System testing)
单元测试
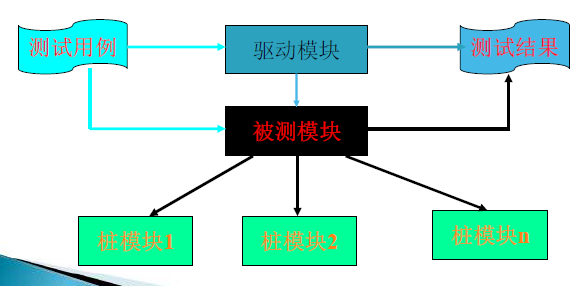
单元测试(unit testing),又称为模块测试,是针对软件结构中独立的基本单元(如函数、子过程、类)进行的测试。

测试对象
单元测试是针对每个基本单元,重点关注5个方面:
- 模块接口
- 局部数据结构
- 边界条件
- 独立的路径
- 错误处理路径
测试时间
一般地,该基本单元的编码完成后就可以对其进行单元测试。
也可以提前,即测试驱动开发(test driven development),在详细设计的时候就编写测试用例,然后再编写程序代码来满足这些测试用例。
集成测试
- 集成测试(integration testing),又称组装测试,它根据设计将软件模块组装起来,进行有序的、递增的测试,并通过测试评价它们之间的交互。
- 集成测试一般由项目经理组织软件测试工程师或由独立的测试部门进行。
- 集成测试重点关注:
- 在把各个软件单元连接起来的时候,穿越单元接口的数据是否会丢失;
- 一个软件单元的功能是否会对另一个软件单元的功能产生不利的影响;
- 各个子功能组合起来,能否达到预期要求的父功能;
- 全局数据结构是否有问题;
- 单个软件单元的误差累积起来,是否会放大,从而达到不能接受的程度。
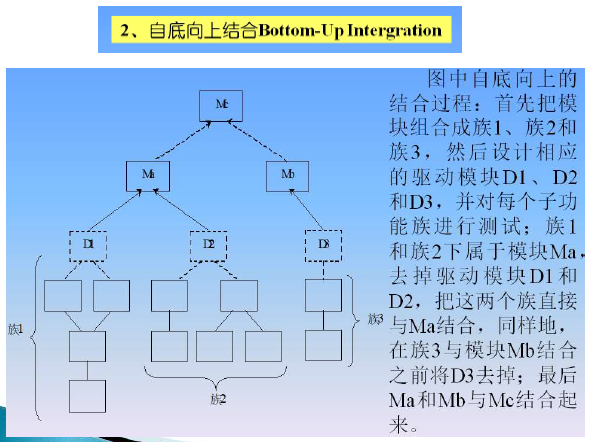
软件集成策略
- 增量式集成
- 自顶向下集成
- 由底向上集成
- 混合方式集成
- 对软件中上层使用自顶向下集成,对软件的中下层采用自底向上集成。
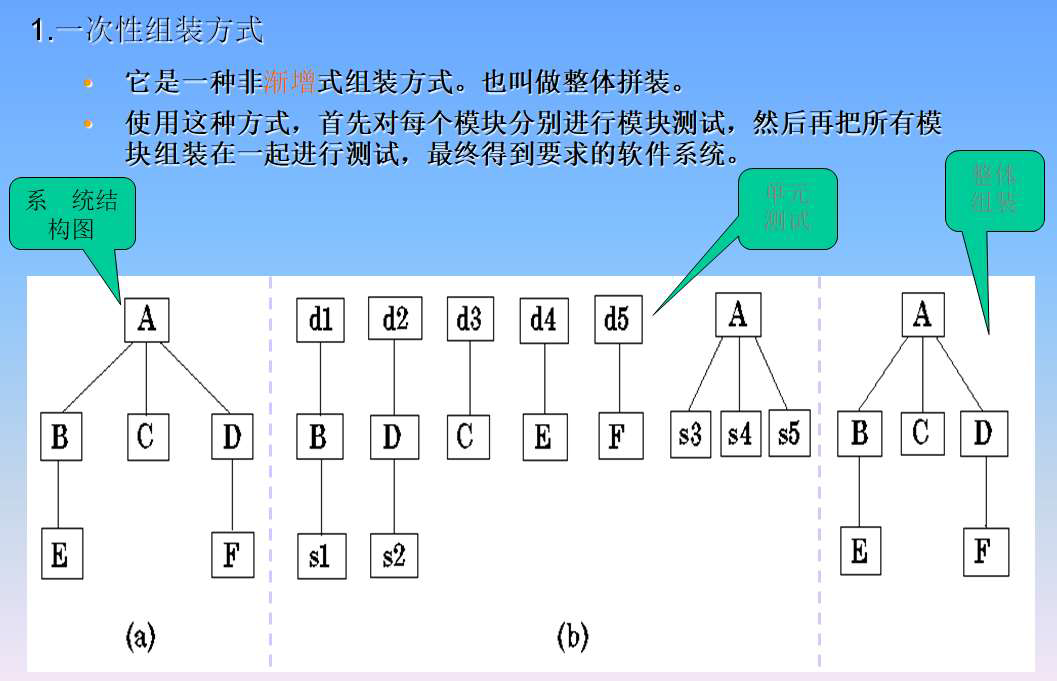
- 一次性集成
- 缺点:接口错误发现晚,错误定位困难
- 优点:可以并行测试和调试所有软件单元
系统测试
- 软件集成及集成测试完成后,对整个软件系统进行的一系列测试,称为系统测试(system testing)。
- 系统测试的目的是为了验证系统是否满足需求规约。
- 测试内容包括功能测试和非功能测试,其中非功能测试常常是系统测试的重点,例如:可靠性测试、性能测试、易用性测试、可维护性测试、可移植性测试等。
- 如果该软件只是一个大的计算机系统的一个组成部分,此时应将软件与计算机系统的其他元素集成起来,检验它能否与计算机系统的其他元素协调地工作。
- 系统测试一般由与开发无直接责任关系的独立方负责,例如项目组的软件测试工程师、测试部门、第三方评测机构、客户等。
软件质量属性的测试
- 功能性测试
又称正确性测试或一致性测试,包括适应性、准确性、互操作性、安全性、功能依存性测试。 - 可靠性测试
成熟性、容错性、已恢复性、可靠性依从性测试。 - 性能测试
时间特性、资源利用性、性能依存性测试,常用压力测试方法。 - 易用性测试
易理解性、易学性、易操作性、吸引性、依从性测试。 - 可移植性测试
适应性、易安装、易替换、可移植性依从测试。 - 可维护性测试
被修改的能力,包括易分析、易改变、稳定性、易测试、维护依从性测试。
其他测试策略
- 验收测试
由用户主导的,根据合同、需求规约或验收计划对软件成品进行验收测试。 - $\alpha$测试和$\beta$测试
- $\alpha$测试:由开发者主导,在受控环境中进行
- $\beta$测试:在用户环境中进行,开发者不在现场
- 安装测试
测试各种允许安装平台能否成功安装。 - 回归测试
对软件系统或部件重新测试,测试改动没有引入新的错误。
测试技术
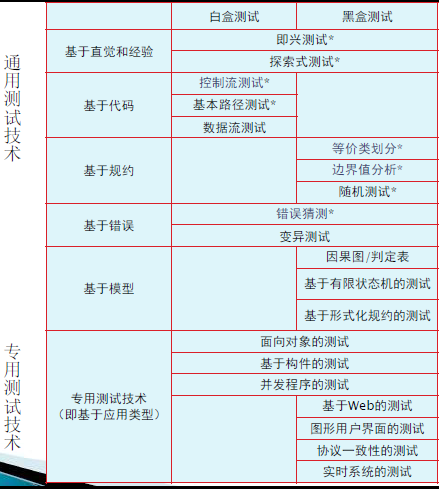
白盒测试
- 白盒测试把被测软件看作一个透明的白盒子,测试人员可以完全了解软件的设计或代码,按照软件内部逻辑进行测试。
- 白盒测试又称玻璃盒测试,常常应用在单元测试中。
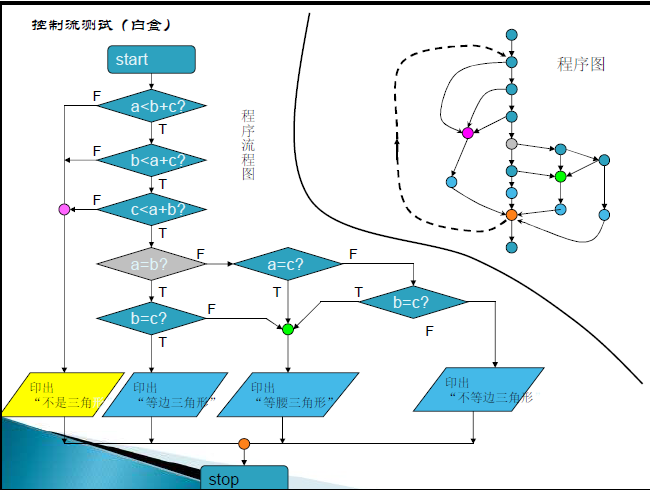
控制流测试(属白盒测试)
- 语句覆盖法
- 判定覆盖(分支)
- 条件覆盖
- 判定/条件覆盖
- 条件组合覆盖
- 路径覆盖
语句覆盖法
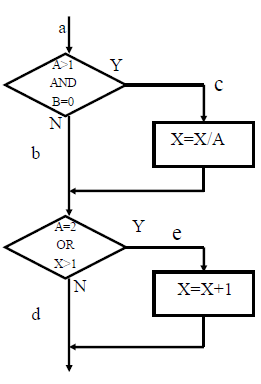
使得程序中的每一个语句至少被遍历一次
测试用例:$A=2,B=0,X=3$
判定覆盖分支
使得程序中每一个分支至少被遍历一次
测试用例:
- $A=2,B=0,X=1$
- $A=1,B=0,X=0$
条件覆盖
使得每个判定的条件获取各种可能的结果
a:$A \gt 1,A \le,B=0,B \neq 0$
b:$A=2,A \neq 2,X \gt1,X \le 1$
- $A=2,B=0,X=4$
- $A=1,B=1,X=1$
判定/条件覆盖
使得判定中的条件取得各种可能的值,并使得每个判定取得各种可能的结果
- $A=2,B=0,X=4$
- $A=1,B=1,X=1$
条件组合覆盖
使得每个判定条件的各种可能组合都至少出现一次
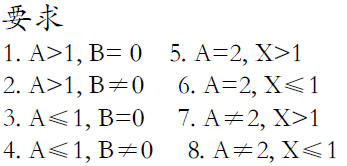

路径覆盖
覆盖程序中所有可能的路径
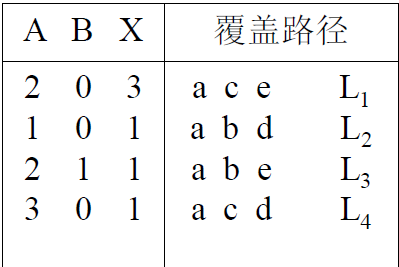
黑盒测试
- 黑盒测试把程序看成一个黑盒子,完全不考虑程序内部结构和处理过程。
- 黑盒测试是在程序接口进行测试,它只是检查程序功能是否按照需求规约正常使用。
- 黑盒测试又称功能测试、行为测试,在软件开发后期执行。
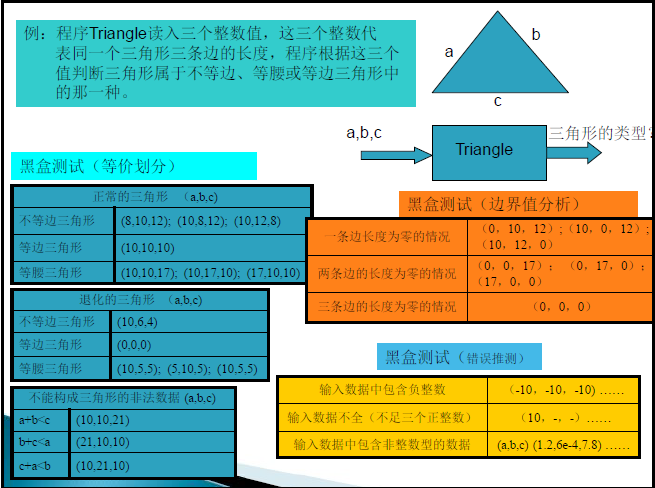
基于规约的测试
- 等价类划分
- 将所有可能的输入数据划分成若干个等价类,然后在每个等价类中选取一组(通常是一个)代表性的数据作为测试用例。
- 边界值分析
- 通常是等价类划分技术的一种补充,在等价类划分技术中,一个等价类中的任一输入数据都可作为该等价类的代表用作测试用例,而边界值分析技术则是专门挑选那些位于输入或输出范围边界附近的数据用作测试用例。
- 随机测试
- 在软件输入域上随机选择输入数据来测试软件的技术。
等价类划分
等价类的划分在很大程度上依靠的是测试人员的经验,下面给出几
条基本原则:
- 输入规定了取值范围,则可划分出一个有效的等价类(输入值在此范围内)和两个无效的等价类(输入值小于最小值、输入值大于最大值)。
- 输入规定了输入数据的个数,则可相应地划分出一个有效的等价类(输入数据的个数等于给定的个数要求)和两个无效的等价类(输入数据的个数少于给定的个数要求、输入数据的个数多于给定的个数要求)。
- 输入规定了输入数据的一组可能的值,而且程序对这组可能的值做相同的处理,则可将这组可能的值划分为一个有效的等价类,而这些值以外的值划分成无效的等价类。
- 输入规定了输入数据的一组可能的值,但是程序对不同的输入值做不同的处理,则每个输入值是一个有效的等价类,此外还有一个无效的等价类(所有不允许值的集合)。
- 输入规定了输入数据必须遵循的规则,则可以划分一个有效的等价类(符合规则)和若干个无效的等价类(从各种角度违反规则)。
确定测试用例
划分出等价类后,根据以下原则设计测试用例:
- 为每个等价类编号。
- 设计一个新的测试用例,使它能包含尽可能多的尚未被覆盖的有效等价类。重复这一过程,直到所有的有效等价类都被覆盖。
- 设计一个新的测试用例,使它包含一个尚未被覆盖的无效等价类。重复这一过程,直到所有的无效等价类都被覆盖。
边界值分析
人们在长期的测试中发现,程序往往在处理边界值的时候容易出错。
通常输入等价类和输出等价类的边界,就是应该着重测试的程序边界情况。
边界值分析也属于黑盒测试,可以看作是对等价类划分的一个补充。
在设计测试用例时,往往联合等价类划分和边界值分析这两种方法。
错误猜测
- 错误猜测(error guessing)是一种凭经验、知识和直觉推测某些可能存在的错误,从而针对这些可能存在的错误设计测试用例的技术。
- 基本思想:列举出程序中所有可能的错误和容易发生错误的特殊情况,然后根据这些猜测设计测试用例。
- 例如,测试一个排序子程序,可考虑如下情况:
- 输入表为空
- 输入表只有一个元素
- 输入表的所有元素都相同
- 输入表已排好序
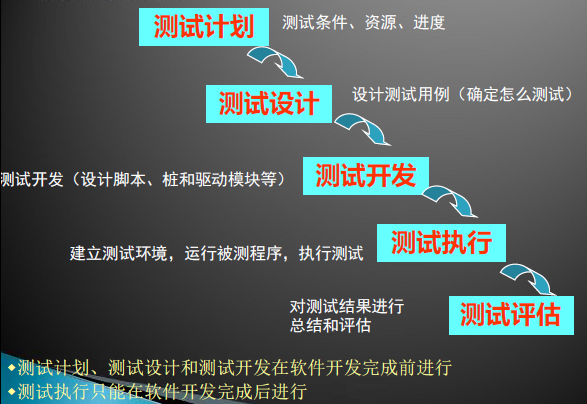
测试过程
测试计划
- 测试目的
- 测试对象
- 测试范围
- 文档的检验
- 测试策略和测试技术
- 测试过程
- 进度安排
- 资源
- 测试开始、结束准则
- 测试文档和测试记录
测试用例设计文档
测试用例(test case)是按一定顺序执行的与测试
目标相关的一系列测试。其主要内容包括:
- 测试输入
- 测试操作
- 期望结果
缺陷报告
- 内容包括:缺陷名称、分类、等级、发现时间,发
现人,所执行的测试用例、现象等 - 缺陷等级
- 5级:灾难性的–系统崩溃、数据被破坏
- 4级:很严重的–数据被破坏
- 3级:严重的–特性不能运行,无法替代
- 2级:中等的–特性不能运行,可替代
- 1级:烦恼的–提示不正确,报警不确切
- 0级:轻微的–表面化的错误,拼写错等
- 缺陷报告通常保存在缺陷跟踪系统
测试报告
- 被测软件的名称和标识
- 测试环境
- 测试对象
- 测试起止日期
- 测试人员
- 测试过程
- 测试结果
- 缺陷清单
- 等
开始和终止测试的标准
- 在测试计划中规定开始和终止测试的标准
- 开始测试的常用标准
- 通过“冒烟” 测试
- 终止测试的常用标准
- 所有严重的缺陷都已纠正,剩余的缺陷密度少于
0.01% - 100%测试覆盖度
- 缺陷数收敛了
- 所有严重的缺陷都已纠正,剩余的缺陷密度少于
自动化测试
- 工具类型
- 单元测试工具,即白盒测试工具
- 性能测试工具
- 功能测试工具,即回归测试工具
- 缺陷跟踪工具
- 测试数据生成工具
- 测试管理工具
- 等
- 工具产品
- HP Mercury: WinRunner, LoadRunner …
- IBM Rational
- Compuware: QA Run, QA Load, QA Director …
- Freeware:JUnit, Bugzilla, Mantis …
- ……
软件可靠性
软件可靠性是软件可靠性是程序在给定的时间间隔内,按照规格说明书的规定成功地运行的概率。
术语“错误”的含义是由开发人员造成的软件差错(bug),而术语“故障”的含义是由错误引起的软件的不正确行为。
软件可用性是程序在给定的时间点,按照规格说明书的规定,成功地运行的概率。
平均无故障时间MTTF是系统按规格说明书规定成功地运行的平均时间。
软件系统故障停机时间为$t_{d1},t_{d2},\dots$
正常运行时间为$t_{u1},t_{u2},\dots$
系统的稳态可用性为$A_{ss}=T_{up}/\left(T_{up}+T_{down}\right)$
$T_{up}=\sum t_{ui},T_{down}=\sum t_{di}$
系统平均无故障时间MTTF,平均维修时间MTTR
$$
A_{ss}=MTTF/(MTTF+MTTR)
$$
平均无故障时间MTTF主要取决于系统中潜伏的错误数目
估算平均无故障时间的方法
软件的平均无故障时间MTTF是一个重要的质量指标,往往作为对软件的一项要求,由用户提出来。为了估算MTTF,首先引入一些有关的量。
符号
在估算MTTF的过程中使用下述符号表示有关的数量:
- $E_T$测试之前程序中错误总数;
- $I_T$程序长度(机器指令总数);
- $\tau$测试(包括调试)时间;
- $E_d(\tau)$在0至$\tau$期间发现的错误数;
- $E_c(\tau)$在0至$\tau$期间改正的错误数。
基本假定
- 在类似的程序中,单位长度里的错误数ET/IT近似为常数。美国的一些统计数字表明,通常$0.5\times10^{-2}\le E_T/I_T \le 2 \times10^{-2}$也就是说,在测试之前每1000条指令中大约有5~20个错误。
- 失效率正比于软件中剩余的(潜藏的)错误数,而平均无故障时间MTTF与剩余的错误数成反比。
- 此外,为了简化讨论,假设发现的每一个错误都立即正确地改正了(即,调试过程没
有引入新的错误)。因此$E_c(\tau)=E_d(\tau)$,剩余错误数量为$E_r(\tau)=E_T-E_c(\tau)$,单位长度程序中剩余的错误数为$\varepsilon_{\mathrm{r}}(\tau)\mathrm{=E_{T}}/\mathrm{I_{T}}-\mathrm{E_{c}}(\tau)/\mathrm{I_{T}}$
估算平均无故障时间
经验表明,平均无故障时间与单位长度程序中剩余的错误数成反比,即
$$
MTTF=1/[K(E_T/I_T-E_c(\tau)/I_T)]
$$
其中K为常数,它的值应该根据经验选取。美国的一些统计数字表明,K的典型值是200。
估算平均无故障时间的公式,可以评价软件测试的进展情况。此外,由上式可得
$$
\mathrm{E_{c}=E_{T}-I_{T}/(K\times MTTF)}
$$
因此也可以根据对软件平均无故障时间的要求,估计需要改正多少个错误之后,测试工作才能结束。
估计错误总数的方法
程序中潜藏的错误的数目是一个十分重要的量,它既直接标志软件的可靠程度,又是计算软件平均无故障时间的重要参数。
程序中的错误总数估计ET的两个方法。
植入错误法
在测试之前由专人在程序中随机地植入一些错误,测试之后,根据测试小组发现的错误中原有的和植入的两种错误的比例,来估计程序中原有错误的总数ET。
假设人为地植入的错误数为Ns,经过一段时间的测试之后发现ns个植入的错误,此外还发现了n个原有的错误。如果可以认为测试方案发现植入错误和发现原有错误的能力相同,则能够估计出程序中原有错误的总数为
$$
N= (n/n_s) \times Ns
$$
其中N即是错误总数ET的估计值。
分别测试法
植入错误法的基本假定是所用的测试方案发现植入错误和发现原有错误的概率相同。但是,人为地植入的错误和程序中原有的错误可能性质很不相同,发现它们的难易程度自然也不相同,因此,上述基本假定可能有时和事实不完全一致。
如果有办法随机地把程序中一部分原有的错误加上标记,然后根据测试过程中发现的有标记错误和无标记错误的比例,估计程序中的错误总数,则这样得出的结果比用植入错误法得到的结果更可信一些。
为了随机地给一部分错误加标记,分别测试法使用两个测试员(或测试小组),彼此独立地测试同一个程序的两个副本,把其中一个测试员发现的错误作为有标记的错误。具体做法是,在测试过程的早期阶段,由测试员甲和测试员乙分别测试同一个程序的两个副本,由另一名分析员分析他们的测试结果。用$\tau$表示测试时间,假设
$\tau=0$时错误总数为B0
$\tau=\tau_1$时测试员甲发现的错误数为B1
$\tau=\tau_1$时测试员乙发现的错误数为B2
$\tau=\tau_1$时两个测试员发现的相同错误数为$b_c$
即程序中有标记的错误总数为B1,则测试员乙发现的B2个错误中有bc个是有标记的。假定测试员乙发现有标记错误和发现无标记错误的概率相同,则可以估计出测试前程序中的错误总数为
$$
\mathrm{B}{0}=(\mathrm{B}{1}/\mathrm{b}c)\mathrm{B}{2}
$$
软件演化和维护
对软件进行维护和更新的一种行为,它是软件生命周期中始终存在的变化活动。
按生命周期的不同阶段,软件演化可分为:
- 开发演化
创造一个新软件的过程,它强调要在一定的约束条件下从头开始实施,占软件演化的30% - 运行演化
又称软件维护(Software Maintenance),是软件系统交付使用以后,为了改正错误或满足新的需要而修改软件的过程,它强调必须在现有系统的限定和约束条件下实施,占软件演化的70%。
在传统环境下,运行演化在开发演化后发生
在网络环境下,开发演化与运行演化已呈现出交织协同、并生共长的态势,软件运行状态改变的同时,软件版本也不断升级
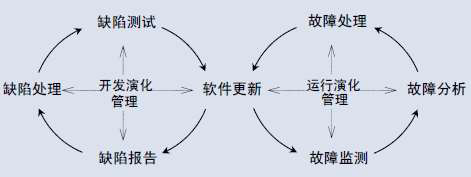
Lehman的8条软件演化法则
- 持续变更法则。软件必须持续改进,否则就会变得越来越不令人满意。
- 复杂度递增法则。软件的复杂性随着演化不断增加,除非采取措施使系统保持或降低复杂性。
- 自调节法则。软件的演化过程可以自动调节产品分布和过程测量,以接近正常状态。
- 组织稳定性法则。在软件的生命周期中,组织的平均开发效率是稳定的。
- 通晓法则。随着软件的演化,所有相关人员(如开发人员、销售人员和用户)都必须始终掌握软件的内容和行为,以便达到满意的演化效果。
- 功能持续增加法则。在软件的生命周期中,软件功能必须持续增加,否则用户的满意度会降低。
- 质量衰减法则。如果没有严格的维护和适应性调整使之适应运行环境的变化,软件的质量会逐渐衰减。
- 反馈系统法则。软件演化过程是由多层次、多循环、多主体的反馈系统组成,而且要想在任何合理的基础上达到有意义的改进就必须这样进行处理。
软件维护是软件工程中最消耗资源的活动,很多软件公司中软件维护的成本已经达到了整个软件生存周期资源的40%到70%,甚至达到了90%
大多数软件在设计时没有考虑到将来的修改问题,常常还伴有开发人员变动频繁、文档不够详细、维护周期过长等等问题
维护类型
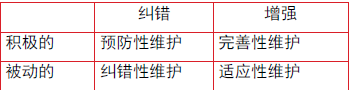
- 纠错性维护(Corrective maintenance)
- 由于软件中的缺陷引起的修改
- 完善性维护(Perfective maintenance)
- 根据用户在使用过程中提出的一些建设性意见而进行的维护活动
- 适应性维护(Adaptive maintenance)
- 为适应环境的变化而修改软件的活动
- 预防性维护(Preventive maintenance)
- 为了进一步改善软件系统的可维护性和可靠性,并为以后的改进奠定基础
维护的技术问题
- 有限理解(Limited understanding),对他人开发软件进行维护时,如何快速理解程序并找到需要修改或纠错的地方?
- 在软件维护过程中需要大量的回归测试,耗时耗力。
- 当软件非常关键以致不能停机时,如何进行在线维护而不影响软件的运行?
- 影响分析,如何对现有软件的变更所进行的全面分析?
- 如何在开发中促进和遵循软件的可维护性?
- 易分析性(Analyzability)
- 易改变性(Changeability)
- 稳定性(Stability)
- 易测试性(Testability)
维护成本
维护的工作可划分成:
- 生产性活动如,分析评价、修改设计、编写程序代码等
- 非生产性活动如,程序代码功能理解、数据结构解释、接口特点和性能界限分析等
维护工作量的模型
$$
M = p + Ke ^{c-d}
$$- M:维护的总工作量;
- P:生产性工作量;
- K:经验常数;
- e: 软件的规模;
- c:复杂程度;
- d:维护人员对软件的熟悉程度
影响维护成本的因素
- 操作环境:硬件和软件
- 软件的规模越大、复杂性越高、年龄越大,硬件的能力越低,软件维护的成本和工作量就越大。
- 组织环境:策略、竞争力、过程、产品和个人
- 软件开发过程和维护过程越规范,采用的设计方法和编程语言模块化程度越高,工程师对软件的熟悉程度越高、能力越强,产品的可靠性和安全性要求越低,软件维护的成本和工作量就越小。
维护过程
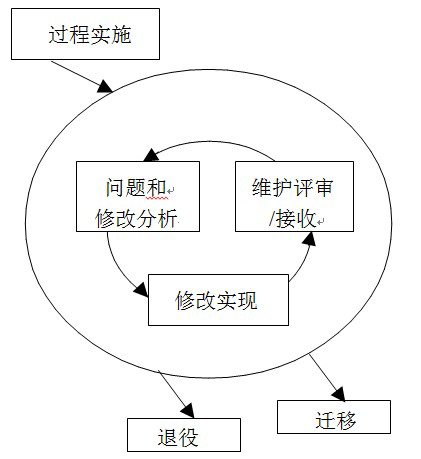
软件维护技术
程序理解
- 软件维护的总工作量大约一半被用在理解程序上。
- 程序理解通过提取并分析程序中各种实体之间的关系,形成系统的不同形式和层次的抽象表示,完成程序设计领域到应用领域的映射。
- 程序员在理解程序的过程中,经常通过反复三个活动──阅读关于程序的文档,阅读源代码,运行程序来捕捉信息。
- 程序理解工具
- 基于程序结构的可视化工具,通过分析程序的结构,抽取其中各种实体,使用图形表示这些实体和它们之间的关系,可以直观地为维护者提供不同抽象层次上的信息。
- 帮助维护者导航浏览源代码,为浏览工作提供着眼点,缩小需要浏览的代码范围。
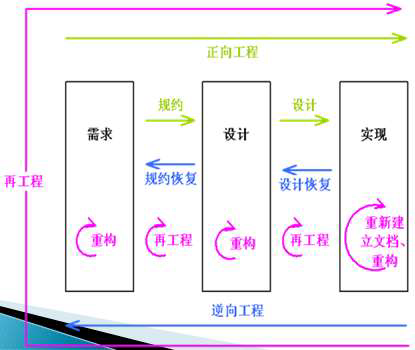
逆向工程
- 逆向工程是分析软件,识别出软件的组成成份及其相互的关系,以更高的抽象层次来刻画软件的过程,它并不改变软件本身,也不产生新的软件。
- 逆向工程主要分为以下几类:
- 重新文档化(redocumentation):分析软件,改进或提供软件新的文档。
- 设计恢复(design recovery):从代码中抽象出设计信息;
- 规约恢复(specification recovery):分析软件,导出需求规约信息;
- 重构(refactoring, restructuring):在同一抽象级别上转换软件描述形式,而不改变原有软件的功能;
- 数据逆向工程(data reverse engineering):从数据库物理模式中获取逻辑模式,如实体关系图。
再工程
再工程是在逆向工程所获信息的基础上修改或重构已有的软件,产生一个新版本的过程,它将逆向工程、重构和正向工程组合起来,将现存系统重新构造为新的形式。
软件项目管理

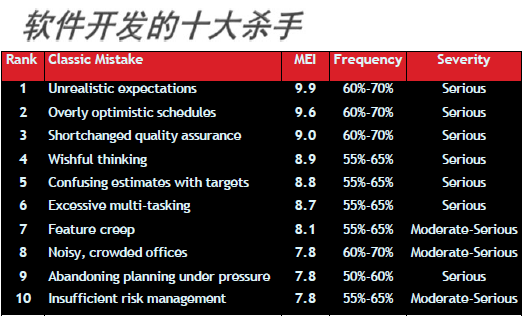
失败的六拍
- 老板拍脑袋决策,想出新的需求;
- 老板拍拍项目经理的肩膀:此项目非君莫属
- 项目经理高兴了,拍拍胸脯:此事包在我身上
- 几个月后,任务没完成,老板拍桌子发火
- 项目经理一看情况不妙,拍屁股走人
- 老板拍大腿后悔,早知如此,何必当初
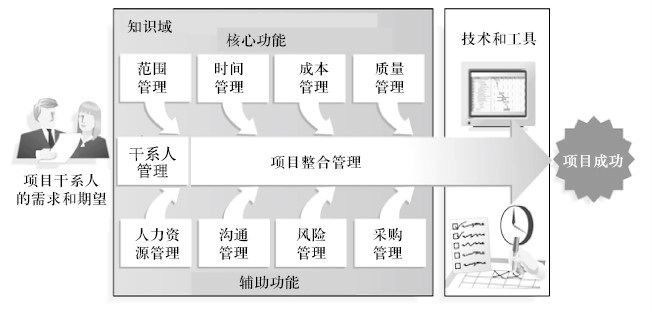
项目管理体系知识PMBOK
- 项目管理的知识体系(Project Management Body of Knowledge,PMBOK),是美国项目管理学会(PMI)对项目管理所需的知识、技能和工具进行的概括性描述。
- 第1版1996年提出,目前最新版本为2012年第5版
- 核心内容
- 五大过程组:启动,计划,执行,控制和收尾
- 十大知识域:范围管理、人力资源管理、采购管理、时间
管理、风险管理、沟通管理、费用管理、质量管理、干系
人管理、整合管理
- PMI项目管理专业人员资格认证PMP
- ISO以PMBOK为框架制订了ISO10006标准
- 中国项目管理委员会(PMRC)参考PMBOK于2002年推出了C-PMBOK
PMBOK十大知识领域
PRINCE2
后面看ppt就好了,没啥重要的
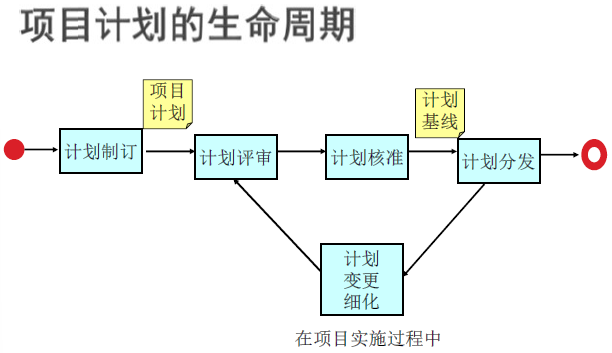
软件项目计划
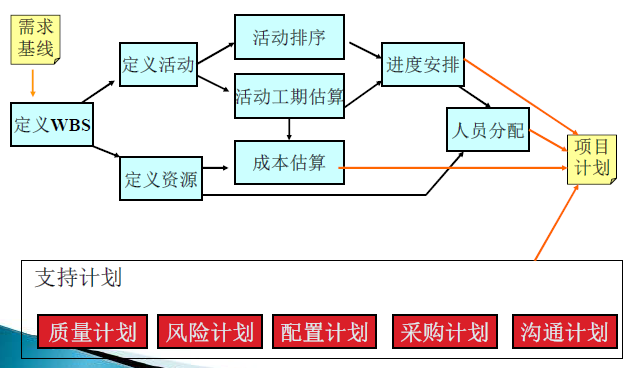
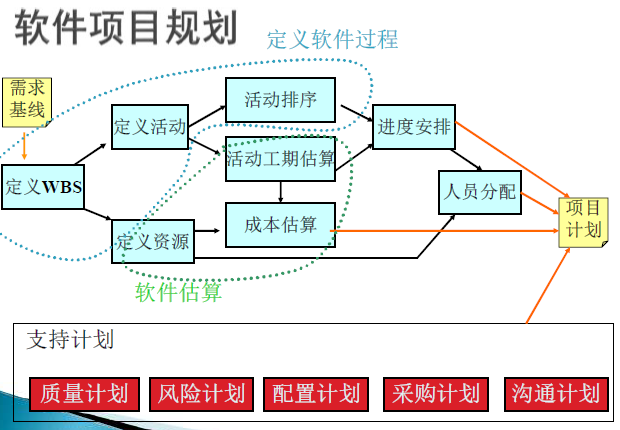
项目计划概述
制订计划:
- 定义软件开发过程
- 软件估算
- 安排进度,确定里程碑
- 分配资源,商讨承诺
- 支持计划
- 质量计划、风险管理计划、沟通计划、配置计划、组织计划、采购计划

进度安排
- 建立PERT图或网络图,确定关键路径,即决定项目开发时间的任务链。
- 根据每个活动的工期估算值设置时间窗口(将节假日等非工作日除外)。
- 考虑时间缓冲,按工期的百分比或固定时间。
- 对活动时序关系设定Lead和Lag。
备注:进度安排和人员分配常常同时进行,相互影响
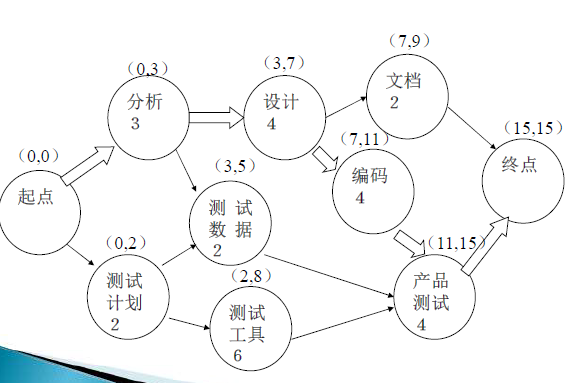
PERT图
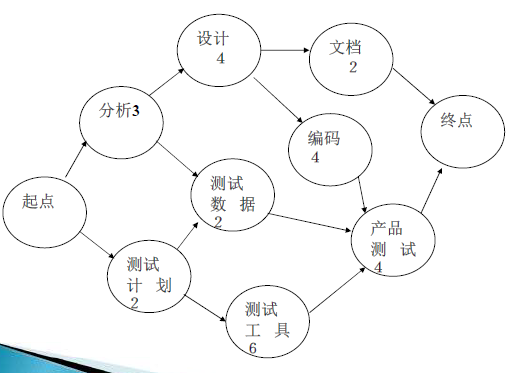
关键路径
项目计划Gantt图
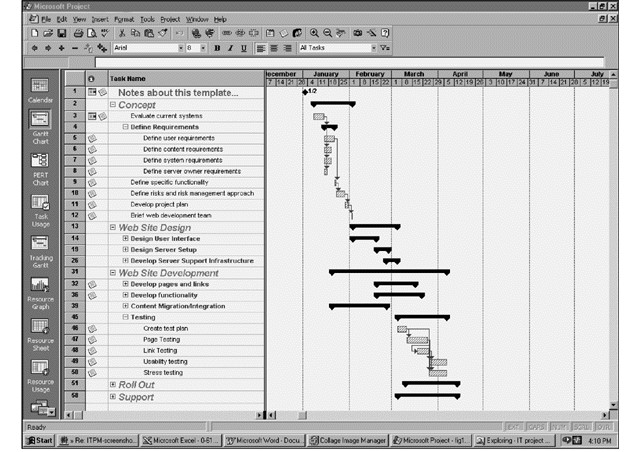
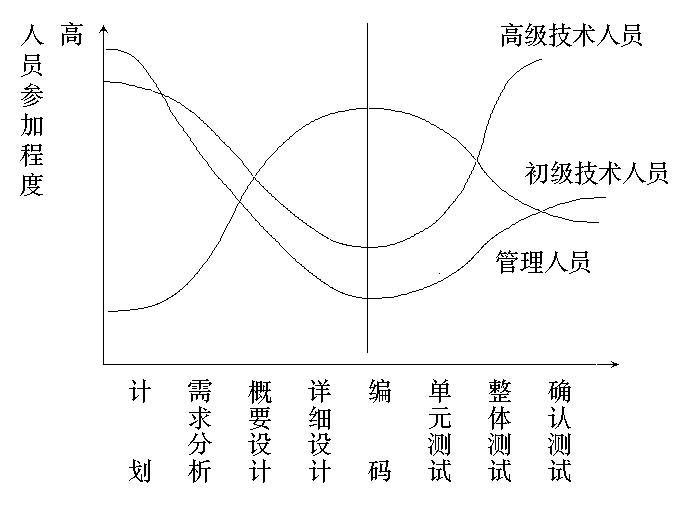
人员分配
两条定律
人员-时间权衡定律
$$
\mathrm{E=a/(T_d)^b}
$$
Brooks定律
向一个已经延晚的项目追加开发人员,可能使它完成得更晚
人力资源分配原则
- 考虑人员的技术水平、专业、人数
- 考虑在开发过程各阶段中对各种人员的需要
- 尽早落实责任
- 减少接口
- 责权均衡
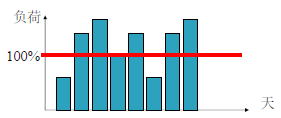
资源负荷和资源平衡
- 资源负荷是指在项目特定时间段现有计划中个体资源的负荷
- 资源平衡是指通过资源调配、延迟任务等方式来解决资源冲突问题
项目计划变更管理
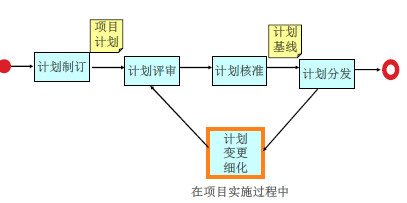
- 需求变化
- 资源变化
- 技术难题
- 计划细化
- 估算失误
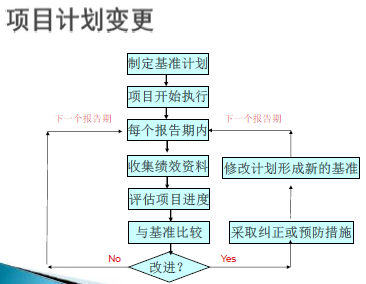
项目跟踪与监控
进度监控
范围监控
质量监控
费用监控
风险监控
变更控制
团队管理
合同管理
信息收集技术
- 会议、交谈
- 报告
- 软件工具
信息分析技术
- 偏差分析
- 趋势预测
- 度量
- 获得值分析/挣值分析(Earned Value Analysis)
质量管理
软件质量管理概述
ANSI/IEEE Std 729-1983定义“与软件产品满足规定的和隐含的需求的能力有关的特征或特性的全体”。
M.J. Fisher 定义“所有描述计算机软件优秀程度的特性的组合”。
明确声明的功能和性能需求、明确文档化过程的开发标准、以及专业人员开发的软件所应具有的所有隐含特征都得到满足。
- 软件需求是进行质量度量的基础,与需求不符就是质量不合格
- 指定的标准定义了一组指导软件开发的准则,如果不能遵照这些准则,就极有可能导致质量不好
- 通常有一组隐含需求是不被提及的,如易维护性,如果软件符合了明确的需求却没有满足隐含需求,软件质量仍然值得怀疑
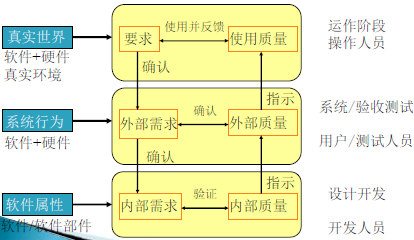
软件的质量属性
质量的三种视角:内部、外部、和使用质量
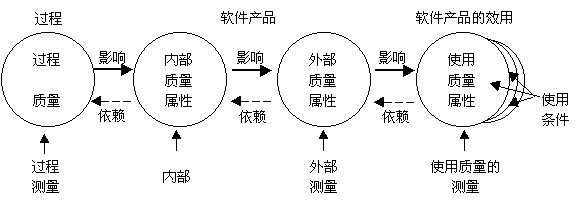
外部和内部质量模型
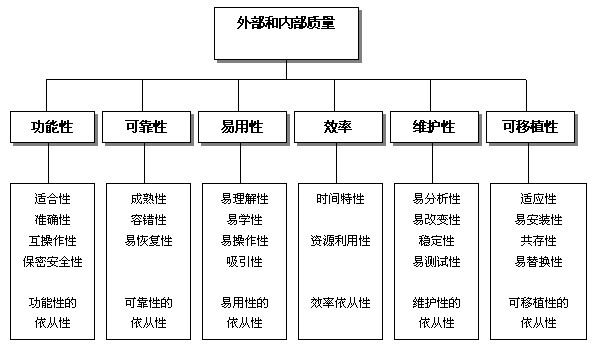
使用质量的模型
质量成本
- 预防成本:使项目的差错保持在一个可接受范围内的成本,如培训、分包商评定等
- 评估成本:评估产品或服务的成本。如产品检查、评审或测试、处理和报告测试数据
- 内部故障成本:在客户收到产品之前,纠正已识别出的一个缺陷所引起的成本
- 外部故障成本:为产品交付顾客之后发现的缺陷而支付的成本。如顾客抱怨处理、讼案、未来商务机会丧失
- 测量和测试设备成本
软件质量管理
- ISO9000:质量计划、质量控制、质量保证、质量改进。
- ISO12207和SWEBOK :软件质量保证、验证和确认、软件评审、软件审核、配置管理。
- SQuBOK :从组织级和项目级进行质量管理。
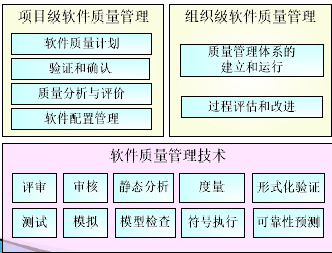
软件质量计划
- 是软件项目计划的子计划
- 内容:
- 质量目标
- 开展质量活动的质量标准、方法、规程和工具
- 验证、确认、评审、测试、审核、问题解决等质量活动和任务的安排
- 开展质量活动的资源、日程和职责
- 质量记录的标识、收集、归档、维护和处理的规程
验证和确认的使用
软件质量管理技术
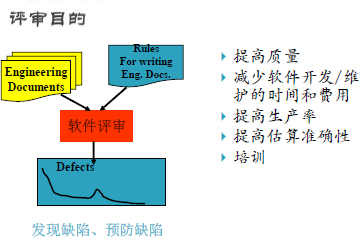
软件评审
评审方法
- 审查
- 小组评审
- 走查
- 结对编程
- 同级桌查
- 轮查
- 临时评审
审查
- 最系统化、最严密的评审技术
- 被认为是软件工业中最实用的、最有效的评审方法
- 严格定义的审查过程,明确的分工
- 审查组长、读者、审查者
- 作者、记录员
小组评审
- 评审过程
- 计划、准备、开会、返工
- 作者或评审组长主持会议
- 读者这个角色被省略了,改由评审组长询问其他评审者这一部分是否有问题
- 使用记录员
- 使用缺陷检查表
走查walkthrough
- 评审过程
- 计划、开会、返工
- 作者主持会议,起主导作用,陈述产品
- 常用走查方法
- 使用一些样品数据一步步执行一个模块,和同事一道检查以确保正确的逻辑和行为。
- 使用交互式调试器
- 按脚本执行,脚本描述了一项具体的任务或场景,用以说明系统如何在用户会话中发挥功能
结对编程
- 极值编程XP中的一个实践
- 两个开发者在一个工作站上同时编写同一个程序,进行实时的、持续的、非正式的评审。司机和搭档的角色还要不时地交换。
- 由于搭档的实时评审,结对者可以迅速纠正错误。快速的迭代能使设计和程序更加强壮。
- 结对编程技术除了能应用于编码,还能应用需求、设计、测试等文档。
同级桌查
- 在两次编译之间仔细地检查源代码以保证程序正确执行,这就是桌查。桌查是PSP的组成部分,是一种自评审,不属于同级评审。
- 在同级桌查中,除作者外的一位评审者对工作产品进行检查。评审者可以和作者坐在一起讨论,也可以独立检查。
- 评审完成后,评审者把错误表交给作者,或者两人一起坐下来共同准备错误表,或者简单地将做过标记的工作产品交给作者。
- 要寻找一位足够专业且值得信赖的人担任评审者。
轮查
- 轮查是由多人组成的并行同级桌查
- 轮查有助于缓和同级桌查的两个主要风险
- 评审者不能及时提供反馈
- 评审效果太糟
合适的评审方法
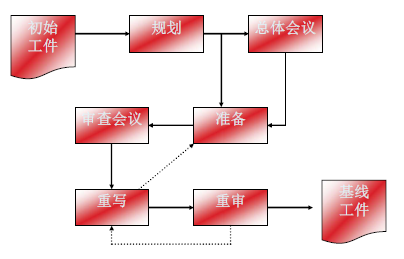
审查过程
受审查的工件
- 项目计划
- 需求规格说明书
- 概要设计、详细设计
- 系统测试计划、用例和报告
- 代码等
审查的规划
- 审查组长判断是否已满足审查的进入标准
- 作者和审查组长协同对审查进行规划,确定审查员和时间进度
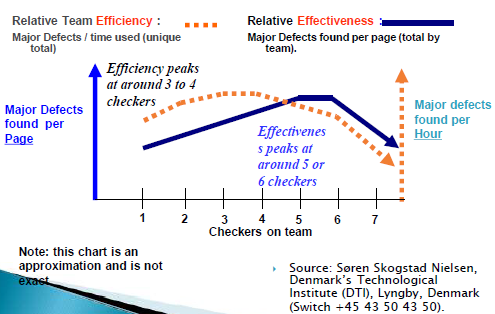
- 审查会议效率:每小时4~6页
- 审查人员不超过7人或者更少
- 审查人员可以是开发人员、测试人员、项目经理、用户等
评审小组人数对效率的影响
进入审查的标准
- 文档符合标准模板
- 文档已经做过拼写检查和语法检查
- 作者已经检查了文档在版面安排上所存在的错误
- 已经获得了审查员所需要的先前或参考文档
- 在文档中打印了行序号以方便在审查中对特定位置的查阅
- 所有未解决的问题都被标记为TBD(待确定)
- 包括了文档中使用到的术语词汇表
审查的准备
- 将需求说明书等到交给每位审查员
- 每个审查员以审查清单为指导,检查文档可能出现的错误,并提出问题
- 75%的错误是在准备阶段发现的
审查会议
- 参加人员:审查组长、作者、记录员、审查人员(选其中一个为读者)
- 每次会议不超过2小时
- 审查目标:尽可能多地发现问题,而不是解决问题
- 递交:会议记录(问题和缺陷)、审查结论
重写
由作者根据审查发现的问题,重写文档
重审
- 由审查组长或指派人单独重审由作者重写的文档,确保所有问题得到解决,所有错误得到修改。
- 由审查组长判断:是否已满足审查的退出标准
退出审查的标准
- 已经明确阐述了审查员提出的所有问题
- 已经正确修改了文档
- 修订过的文档已经进行了拼写检查和语法检查
- 所有TBD的问题已经全部解决,或者已记录下每个待确定问题的解决过程,目标日期和提出问题的人
- 文档已经登记入项目的配置管理系统



