23秋季学期学习了《数字图像处理》这门课,在里面接触到了卷积这个词,感觉很像矩阵的Hadamard积(关于Hadamard积,可以参考hadamard积 | J&Ocean BLOG (jiangwu.xyz)这篇博客)现在接触到了深度学习,那么避不开经典的CNN——卷积神经网络,深化一下卷积的概念
构成所有卷积网络主干的基本元素
卷积层本身、填充(padding)和步幅(stride)的基本细节、用于在相邻区域汇聚信息的汇聚层(pooling)、在每一层中多通道(channel)的使用
这里介绍经典的CNN,完整LeNet模型
从全连接层到卷积
多层感知机对于高维感知数据,这种缺少结构的网络可能会变得不实用
不变性
可以使用一个“沃尔多检测器”扫描图像
该检测器将图像分割成多个区域,并为每个区域包含沃尔多的可能性打分
卷积神经网络正是将空间不变性(spatial invariance)的这一概念系统化,从而基于这个模型使用较少的参数来学习有用的表示。
适合于计算机视觉的神经网络架构
- 平移不变性(translation invariance):不管检测对象出现在图像中的哪个位置,神经网络的前面几层应该对相同的图像区域具有相似的反应,即为“平移不变性”。
- 局部性(locality):神经网络的前面几层应该只探索输入图像中的局部区域,而不过度在意图像中相隔较远区域的关系,这就是“局部性”原则。最终,可以聚合这些局部特征,以在整个图像级别进行预测。
多层感知机的限制
多层感知机的输入是二维图像$\textbf{X}$,其隐藏表示$\textbf{H}$在数学上是一个矩阵,在代码中表示为二维张量。其中X和H具有相同的形状。
使用$[\textbf{X}]{ij},[\textbf{H}]{ij}$分别表示输入图像和隐藏表示中位置(i,j)处的像素。为了使每个隐藏神经元都能接收到每个输入像素的信息,我们将参数从权重矩阵(如同我们先前在多层感知机中所做的那样)替换为四阶权重张量W。
假设U包含偏置参数,我们可以将全连接层形式化地表示为
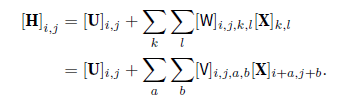
从W到V的转换只是形式上的转换,因为在这两个四阶张量的元素之间存在一一对应的关系
重新索引下标(k, l),使k = i+a、l = j +b
由此可得$[V]{i,j,a,b}$ = $[W]{i,j,i+a,j+b}$。索引a和b通过在正偏移和负偏移之间移动覆盖了整个图像
对于隐藏表示中任意给定位置(i,j)处的像素值$[H]{i,j}$,可以通过在x中以(i, j)为中心对像素进行加权求和得到,加权使用的权重为$[V]{i,j,a,b}$。
平移不变性
引用上述的第一个原则:平移不变性
意味着检测对象在输入X中的平移,应该仅导致隐藏表示H中的平移。也就是说,V和U实际上不依赖于(i, j)的值,即$[V]{i,j,a,b} = [V]{a,b}$。并且U是一个常数,比如u。因此,可以简化H定义为:
$$
[\mathbf{H}]{i,j}=u+\sum{a}\sum_{b}[\mathbf{V}]{a,b}[\mathbf{X}]{i+a,j+b}
$$
这就是卷积(convolution)
在使用系数$[V]{a,b}$对位置(i, j)附近的像素(i + a, j + b)进行加权得到[H]i,j。注意,$[V]{a,b}$的系数比$[V]_{i,j,a,b}$少很多,因为前者不再依赖于图像中的位置
局部性
现在引用上述的第二个原则:局部性。如上所述,为了收集用来训练参数$[H]{i,j}$的相关信息,不应偏离到距(i, j)很远的地方。这意味着在$|a| > \Delta$或$|b| > \Delta$的范围之外,可以设置$[V]{a,b} = 0$,可以设置$[H]{i,j}$重写为.
$$
[\mathbf{H}]{i,j}=u+\sum_{a=-\Delta}^{\Delta}\sum_{b=-\Delta}^{\Delta}[\mathbf{V}]{a,b}[\mathbf{X}]{i+a,j+b}
$$
上面是一个卷积层(convolutional layer)
卷积神经网络是包含卷积层的一类特殊的神经网络
V被称为卷积核(convolution kernel)或者滤波器(filter),亦或简单地称之为该卷积层的权重,通常该权重是可学习的参数
卷积
卷积定义:
$$
(f*g)(\mathbf{x})=\int f(\mathbf{z})g(\mathbf{x}-\mathbf{z})d\mathbf{z}
$$
卷积是当把一个函数“翻转”并移位x时,测量f和g之间的重叠
对于二维张量,则为f的索引(a, b)和g的索引(i − a, j − b)上的对应加和:
$$
(f*g)(i,j)=\sum_a\sum_bf(a,b)g(i-a,j-b)
$$
通道
图像不是二维张量,而是一个由高度、宽度和颜色组成的三维张量
对于每一个空间位置,采用一组而不是一个隐藏表示
$$
[\mathsf{H}]{i,j,d}=\sum{a=-\Delta}^{\Delta}\sum_{b=-\Delta}^{\Delta}\sum_{c}[\mathbf{V}]{a,b,c,d}[\mathbf{X}]{i+a,j+b,c}
$$
图像卷积
互相关运算
卷积层实际表达的运算是互相关运算cross-correlation,并非卷积运算
在卷积层中,输入张量和核张量通过互相关运算产生输出张量
二维张量的互相关运算
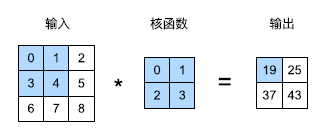
在二维互相关运算中,卷积窗口从输入张量的左上角开始,从左到右、从上到下滑动
输入张量和核函数进行完互相关运算后的输出张量会变形
输入大小$n_h \times n_w$减去卷积核大小$k_h \times k_w$即:
$$
(n_h-k_h+1)\times(n_w-k_w+1).
$$
使用代码实现
输入张量X,卷积核K
def corr2d(X, K):
h, w = K.shape
# (nh-kh+1)*(nw-kw+1).
Y = torch.zeros((X.shape[0] - h + 1, X.shape[1] - w + 1))
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
Y[i, j] = (X[i:i + h, j:j + w] * K).sum()
return Y
X=torch.tensor(
[[0,1,2],
[3,4,5],
[6,7,8]]
)
K=torch.tensor(
[[0,1],
[2,3]]
)
corr2d(X,K)tensor([[19., 25.],
[37., 43.]])卷积层
卷积层对输入和卷积核权重进行互相关运算,并在添加标量偏置之后产生输出
卷积层中的两个被训练的参数是卷积核权重和标量偏置
基于上面的corr2d函数实现二维卷积层,继承nn.Module
__init__构造函数中,需要添加卷积核的尺寸,声明weight、bias
forward中添加互相关运算结果与偏置的和
高度和宽度分别为h和w的卷积核可以被称为$h \times w$卷积或$h \times w$卷积核。我们也将带有$h \times w$卷积核的卷积层称为$h \times w$卷积层。
吃个栗子
实现一个卷积核尺寸为kernel_size的卷积层
class Conv2D(nn.Module):
def __init__(self,kernel_size):
super().__init__()
self.weight=nn.Parameter(torch.randn(kernel_size))
self.bias=nn.Parameter(torch.zeros(1))
def forward(self,X):
return corr2d(X,self.weight)+self.bias图像中目标边缘检测
通过找到像素变化的位置,来检测图像中不同颜色的边缘
吃个栗子
设计一个能够检测像素变化的卷积核
X=torch.ones((6,8))
Xtensor([[1., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1.]])X[:,2:6]=0
Xtensor([[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.]])K=torch.tensor([[1,-1]])
Y=corr2d(X,K)
Ytensor([[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.]])注意:这里的检测卷积核具有单向性
学习卷积核
通过降低loss学习一个卷积核
吃个栗子
通过学习训练一个能够检测像素变化的卷积核
conv2d=nn.Conv2d(1,1,kernel_size=(1,2),bias=False)
X=X.reshape((1,1,6,8))
Y=Y.reshape((1,1,6,7))
lr=3e-2
for i in range(100):
Y_hat=conv2d(X)
l=(Y_hat-Y)**2
conv2d.zero_grad()
l.sum().backward()
conv2d.weight.data[:]-=lr*conv2d.weight.grad
if (i+1)%10==0:
print(f'epoch{i+1},loss {l.sum():.3f}')epoch10,loss 0.049
epoch20,loss 0.001
epoch30,loss 0.000
epoch40,loss 0.000
epoch50,loss 0.000
epoch60,loss 0.000
epoch70,loss 0.000
epoch80,loss 0.000
epoch90,loss 0.000
epoch100,loss 0.000conv2d.weight.data.reshape((1,2))tensor([[ 1.0000, -1.0000]])互相关和卷积
为了得到正式的卷积运算输出,我们需要执行公式中定义的严格卷积运算,而不是互相关运算
它们差别不大,我们只需水平和垂直翻转二维卷积核张量,然后对输入张量执行互相关运算。
由于卷积核是从数据中学习到的,因此无论这些层执行严格的卷积运算还是互相关运算,卷积层的输出都不会受到影响
继续把“互相关运算”称为卷积运算
特征映射和感受野
输出的卷积层有时被称为特征映射(feature map),因为它可以被视为一个输入映射到下一层的空间维度的转换器。
对于某一层的任意元素x,其感受野(receptive field)是指在前向传播期间可能影响x计算的所有元素(来自所有先前层)。
填充和步幅
填充(padding)和步幅(stride)
填充
应用多层卷积时,我们常常丢失边缘像素
解决丢失的简单方法就是填充
在输入图像的边界填充元素(通常填充元素是0)
添加$p_h$行填充(大约一半在顶部,一半在底部)和$p_w$列填充(左侧大约一半,右侧一半),则输出形状将为
$$
(n_{h}-k_{h}+p_{h}+1)\times(n_{w}-k_{w}+p_{w}+1)
$$
在许多情况下,需要设置$p_h = k_h −1$和$p_w = k_w −1$,使输入和输出具有相同的高度和宽度。这样可以在构建网络时更容易地预测每个图层的输出形状
卷积神经网络中卷积核的高度和宽度通常为奇数,例如1、3、5或7。选择奇数的好处是,保持空间维度的同时,我们可以在顶部和底部填充相同数量的行,在左侧和右侧填充相同数量的列。
吃个栗子
创建一个高度和宽度为3的二维卷积层,并在所有侧边填充1个像素。给定高度和宽度为8的输入,则输出的高度和宽度也是8。
def comp_conv2d(conv2d,X):
X=X.reshape((1,1)+X.shape)
Y=conv2d(X)
# 省略批量大小和通道
return Y.reshape(Y.shape[2:])
conv2d=nn.Conv2d(1,1,kernel_size=3,padding=1)
X=torch.randn((8,8))
comp_conv2d(conv2d,X).shapetorch.Size([8, 8])使用高度为5,宽度为3的卷积核,高度和宽度两边的填充分别为2和1
步幅
计算互相关时,卷积窗口从输入张量的左上角开始,向下、向右滑动
在前面都是默认每次滑动为1,有时可以跳过中间,滑动多个元素
每次滑动元素的数量称为步幅(stride)
当垂直步幅为$s_h$、水平步幅为$s_w$时,输出形状为
$$
\lfloor(n_{h}-k_{h}+p_{h}+s_{h})/s_{h}\rfloor\times\lfloor(n_{w}-k_{w}+p_{w}+s_{w})/s_{w}\rfloor
$$
conv2d=nn.Conv2d(1,1,kernel_size=3,padding=1,stride=2)
comp_conv2d(conv2d,X).shapetorch.Size([4, 4])多输入多输出通道
添加通道时,输入和隐藏的表示都变成了三维张量
每个RGB输入图像具有$3 \times h \times w$的形状。我们将这个大小为3的轴称为通道(channel)维度
多输入通道
设通道数为$c_i$则卷积核的形状是$c_i \times k_h \times k_w$
由于输入和卷积核都有$c_i$个通道,可以对每个通道输入的二维张量和卷积核的二维张量进行互相关运算,再对通道求和(将$c_i$的结果相加)得到二维张量。
吃个栗子
实现一个多通道的互相关运算
def corr2d_multi_in(X,K):
return sum(corr2d(x,k) for x,k in zip(X,K))
X=torch.randn((2,3,3))
Xtensor([[[-0.2950, 0.7654, 0.8773],
[-1.6835, 1.0879, 0.0988],
[-1.1015, 1.6368, 1.1919]],
[[-0.8365, -0.6029, 0.7487],
[ 0.6346, 0.8145, 0.0311],
[-0.9514, 2.0003, 0.7082]]])K=torch.randn((2,2,2))
Ktensor([[[-1.7764, -0.6373],
[-0.1827, -0.9844]],
[[ 0.2180, -0.8306],
[-0.3717, 0.4524]]])corr2d_multi_in(X,K)tensor([[-0.2761, -3.2568],
[ 1.6078, -3.7393]])多输出通道
多输出通道并不仅是学习多个单通道的检测器
用$c_i$和$c_o$分别表示输入和输出通道的数目,并让$k_h$和$k_w$为卷积核的高度和宽度
为了获得多个通道的输出,为每个输出通道创建一个形状为$c_i \times k_h \times k_w$的卷积核张量,这样卷积核的形状是$c_o \times c_i \times k_h \times k_w$
每个输出通道先获取所有输入通道,再以对应该输出通道的卷积核计算出结果
吃个栗子
构建一个多输出通道的
def corr2d_multi_in_out(X,K):
return torch.stack([corr2d_multi_in(X,k) for k in K],0)
K=torch.stack((K,K+1,K+2),0)
K.shape
corr2d_multi_in_out(X,K)tensor([[[ 0.0507, -0.7495],
[ 7.9454, -2.8922]],
[[ 2.1272, 2.9171],
[13.6500, 4.4601]],
[[ 4.2037, 6.5838],
[19.3546, 11.8125]]])1*1卷积层
$1 \times 1$卷积的唯一计算发生在通道上。
将$1\times1$卷积层看作在每个像素位置应用的全连接层,以$c_i$个输入值转换为$c_o$个输出值
这仍然是一个卷积层,所以跨像素的权重是一致
$1\times1$卷积层需要的权重维度为$c_o \times c_i$,再额外加上一个偏置
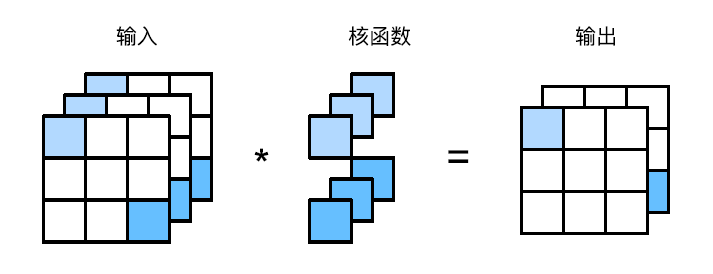
输入和输出具有相同的高度和宽度。
吃个栗子
实现$1 \times 1$卷积
def corr2d_multi_in_out_1x1(X, K):
c_i, h, w = X.shape
c_o = K.shape[0]
X = X.reshape((c_i, h * w))
K = K.reshape((c_o, c_i))
Y = torch.matmul(K, X)
return Y.reshape((c_o, h, w))
X = torch.normal(0, 1, (3, 3, 3))
K = torch.normal(0, 1, (2, 3, 1, 1))
Y1 = corr2d_multi_in_out_1x1(X, K)
Y1tensor([[[-1.8804, -0.4581, -1.2173],
[ 1.4326, -0.5600, -0.5311],
[-1.0435, -0.3202, -0.2829]],
[[ 2.2562, -2.0430, -0.5775],
[ 0.1466, 1.1836, 0.2400],
[-0.8999, -0.2738, 1.0978]]])汇聚层
最后一层的神经元应该对整个输入的全局敏感
汇聚(pooling)层,它具有双重目的:降低卷积层对位置的敏感性,同时降低对空间降采样表示的敏感性。
汇聚层不包含参数
最大汇聚层和平均汇聚层
汇聚层运算符由一个固定形状的窗口组成,该窗口根据其步幅大小在输入的所有区域上滑动,为固定形状窗口(有时称为汇聚窗口)遍历的每个位置计算一个输出
池运算是确定性的,我们通常计算汇聚窗口中所有元素的最大值或平均值。这些操作分别称为最大汇聚层(maximum pooling)和平均汇聚层(average pooling)
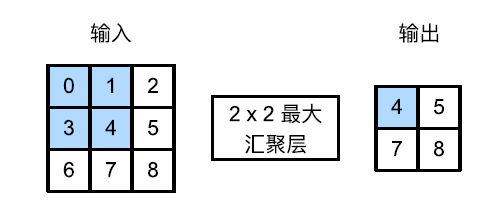
有点类似于数字图像处理中的非线性滤波器
吃个栗子
实现一个可自选模式的汇聚层函数
def pool2d(X,pool_size,mode='max'):
p_h,p_w=pool_size
Y=torch.zeros((X.shape[0]-p_h+1,X.shape[1]-p_w+1))
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
if mode=='max':
Y[i,j]=X[i:i+p_h,j:j+p_w].max()
elif mode=='avg':
Y[i,j]=X[i:i+p_h,j:j+p_w].mean()
return YX=torch.randn((3,3))
Xtensor([[ 0.5837, -0.6450, 1.3309],
[ 0.1119, 0.8673, -0.3884],
[ 1.3378, -0.3333, 0.8984]])pool2d(X,(2,2))tensor([[0.8673, 1.3309],
[1.3378, 0.8984]])pool2d(X,(2,2),'avg')tensor([[0.2295, 0.2912],
[0.4959, 0.2610]])填充和步幅
和卷积层一样的定义,通过填充和步幅以获得所需的输出形状
默认情况下,深度学习框架中的步幅与汇聚窗口的大小相同
使用形状为(3, 3)的汇聚窗口,那么默认情况下,我们得到的步幅形状为(3, 3)
吃个栗子
pool2d=nn.MaxPool2d(3)
pool2d(X)tensor([[[[10.]]]])pool2d=nn.MaxPool2d(3,padding=1,stride=2)
pool2d(X)tensor([[[[ 5., 7.],
[13., 15.]]]])pool2d = nn.MaxPool2d((2, 3), stride=(2, 3), padding=(0, 1))
pool2d(X)tensor([[[[ 5., 7.],
[13., 15.]]]])多个通道
汇聚层在每个输入通道上单独运算
汇聚层的输出通道数与输入通道数相同
吃个栗子
X=torch.cat((X,X+1),1)
Xtensor([[[[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.],
[12., 13., 14., 15.]],
[[ 1., 2., 3., 4.],
[ 5., 6., 7., 8.],
[ 9., 10., 11., 12.],
[13., 14., 15., 16.]]]])pool2d=nn.MaxPool2d(3,padding=1,stride=2)
pool2d(X)tensor([[[[ 5., 7.],
[13., 15.]],
[[ 6., 8.],
[14., 16.]]]])LeNet
由两个部分组成:
- 卷积编码器:由两个卷积层组成;
- 全连接层密集块:由三个全连接层组成。
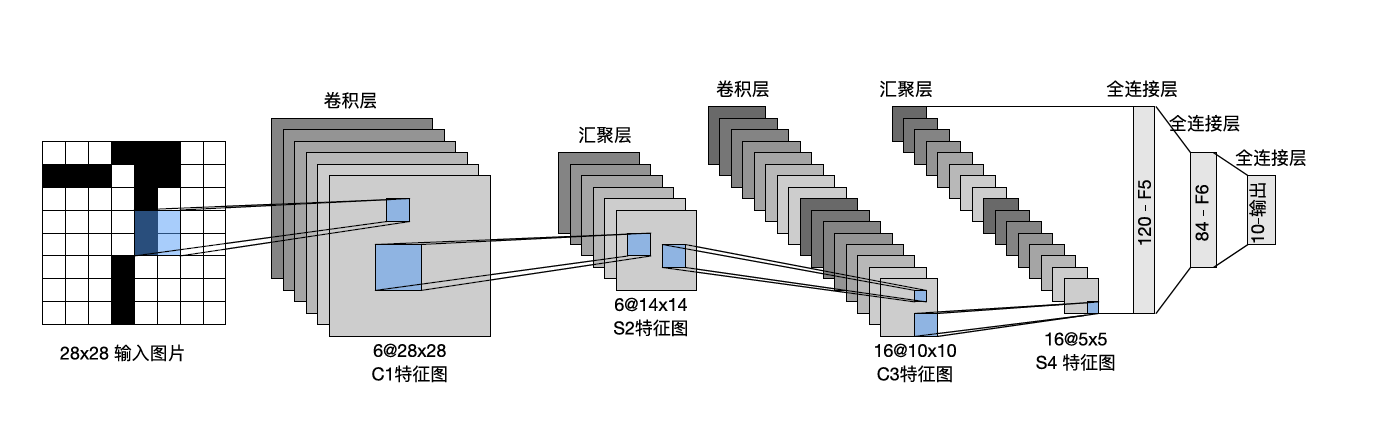
每个卷积块中的基本单元是一个卷积层、一个sigmoid激活函数和平均汇聚层
每个卷积层使用$5 \times 5$卷积核和一个sigmoid激活函数
第一卷积层有6个输出通道,而第二个卷积层有16个输出通道。第一个卷积层有填充,第二个卷积层没有填充
每个$2 \times 2$池操作(步幅2)通过空间下采样将维数减少4倍。
在稠密层需要将张量展平,然后输入全连接层,全连接层输入后接激活函数Sigmoid
模型的文章发表于1998!
简化的LeNet-5模型
# LeNet简化版本 1998
LeNet = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=(5, 5), padding=2),
nn.Sigmoid(),
nn.AvgPool2d(kernel_size=(2, 2), stride=2),
nn.Conv2d(6, 16, kernel_size=(5, 5)),
nn.Sigmoid(),
nn.AvgPool2d(kernel_size=(2, 2), stride=2),
nn.Flatten(),
nn.Linear(16 * 5 * 5, 120),
nn.Sigmoid(),
nn.Linear(120, 84),
nn.Sigmoid(),
nn.Linear(84, 10)
)查看输出形状
X=torch.rand(size=(1,1,28,28),dtype=torch.float32)
for layer in LeNet:
X=layer(X)
print(layer.__class__.__name__,'output shape',X.shape)Conv2d output shape torch.Size([1, 6, 28, 28])
Sigmoid output shape torch.Size([1, 6, 28, 28])
AvgPool2d output shape torch.Size([1, 6, 14, 14])
Conv2d output shape torch.Size([1, 16, 10, 10])
Sigmoid output shape torch.Size([1, 16, 10, 10])
AvgPool2d output shape torch.Size([1, 16, 5, 5])
Flatten output shape torch.Size([1, 400])
Linear output shape torch.Size([1, 120])
Sigmoid output shape torch.Size([1, 120])
Linear output shape torch.Size([1, 84])
Sigmoid output shape torch.Size([1, 84])
Linear output shape torch.Size([1, 10])事实证明,初始化参数真的很重要
对于卷积层和全连接层的参数使用Xavier方法初始化,不进行初始化会造成loss居高不下,无法收敛
class LeNet1(nn.Module):
def __init__(self):
super(LeNet1, self).__init__()
self.conv1 = nn.Conv2d(1, 6, 5, padding=2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.avgPool = nn.AvgPool2d(kernel_size=2, stride=2)
self.maxPool = nn.MaxPool2d(kernel_size=2, stride=2)
self.flatten = nn.Flatten()
self.relu = nn.ReLU()
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
self.sigmoid = nn.Sigmoid()
def forward(self, X):
X = self.conv1(X)
X = self.sigmoid(X)
# X = self.relu(X)
X = self.avgPool(X)
X = self.conv2(X)
X = self.sigmoid(X)
# X = self.relu(X)
X = self.avgPool(X)
X = self.flatten(X)
X = self.fc1(X)
X = self.sigmoid(X)
# X = self.relu(X)
X = self.fc2(X)
X = self.sigmoid(X)
# X = self.relu(X)
pred = self.fc3(X)
return pred


