学习了一点深度学习之后发现自己的PyTorch学的一知半解,数据集、训练/测试函数写的一坨,所以重新学一下PyTorch深度学习整个流程的
Dataset与DataLoader
Dataset类的半官方文档
Init signature: Dataset()
Source:
class Dataset(Generic[T_co]):
r"""An abstract class representing a :class:`Dataset`.
All datasets that represent a map from keys to data samples should subclass
it. All subclasses should overwrite :meth:`__getitem__`, supporting fetching a
data sample for a given key. Subclasses could also optionally overwrite
:meth:`__len__`, which is expected to return the size of the dataset by many
:class:`~torch.utils.data.Sampler` implementations and the default options
of :class:`~torch.utils.data.DataLoader`.
.. note::
:class:`~torch.utils.data.DataLoader` by default constructs a index
sampler that yields integral indices. To make it work with a map-style
dataset with non-integral indices/keys, a custom sampler must be provided.
"""
def __getitem__(self, index) -> T_co:
raise NotImplementedError
def __add__(self, other: 'Dataset[T_co]') -> 'ConcatDataset[T_co]':
return ConcatDataset([self, other])
# No `def __len__(self)` default?
# See NOTE [ Lack of Default `__len__` in Python Abstract Base Classes ]
# in pytorch/torch/utils/data/sampler.py
File: e:\anaconda\envs\pytorch\lib\site-packages\torch\utils\data\dataset.py
Type: type
Subclasses: IterableDataset, TensorDataset, ConcatDataset, Subset, MapDataPipe必须要重写的两个函数是 __getitem__,__len__
两种类型的数据集构建法
class myData(Dataset):
def __init__(self,root_dir,label_dir):
self.root_dir=root_dir
self.label_dir=label_dir
self.path=os.path.join(self.root_dir,self.label_dir)
self.img_path=os.listdir(self.path)
def __getitem__(self,idx):
img_name=self.img_path[idx]
img_path=os.path.join(self.path,img_name)
img=Image.open(img_path)
label=self.label_dir
return img,label
def __len__(self):
return len(self.img_path)上面的label就是文件夹名字,下面的label作为单独的文件存在
class MyData(Dataset):
def __init__(self,root_dir,label_dir,img_dir):
self.root_dir=root_dir
self.img_dir=img_dir
self.label_dir=label_dir
self.img_path=os.listdir(os.path.join(self.root_dir,self.img_dir))
self.label_path=os.listdir(os.path.join(self.root_dir,self.label_dir))
def __getitem__(self,idx):
img_name=self.img_path[idx]
label_name=self.label_path[idx]
img_path=os.path.join(self.root_dir,self.img_dir,img_name)
label_path=os.path.join(self.root_dir,self.label_dir,label_name)
img=Image.open(img_path)
with open(label_path,"r") as f:
label=f.read()
return img,label
def __len__(self):
return len(self.img_path)TensorBoard
尽管pytorch可以调用tensorboard,仍然需要单独安装 tensorboard库
虚拟环境下运行 pip install tensorboard
查看日志的方法:
- 命令行启动tensorboard-server
tensorboard --logdir=log的相对/绝对路径 --port=想要打开的端口- 在浏览器打开启动端口
SummaryWriter
可以将训练/运行日志通过summarywriter写下来
writer=SummartWriter("logs")
# writer操作
writer.close()tranforms
对数据进行变形处理
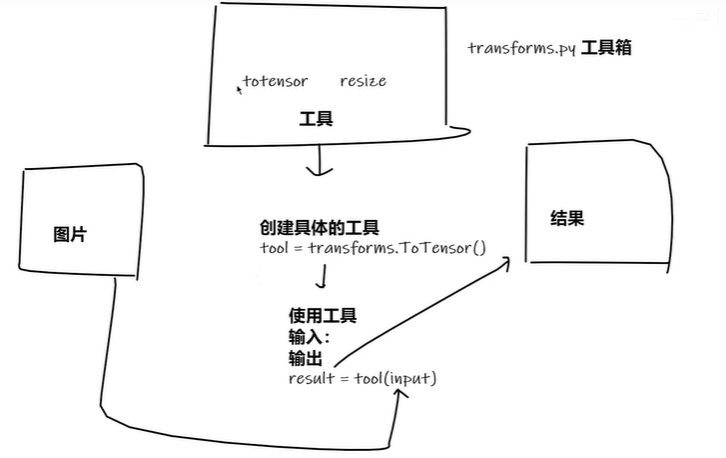
from torchvision import transformsToTensor()
将PIL格式的图片转换成张量格式
toTensor=transforms.ToTensor()
image_tensor=toTensor(image_PIL)ToPILImage()
将 tensor/ndarray格式的图片转换成PIL格式
Normalize()
规范化数据
$$
output=(input-mean)/std
$$
norm=transforms.Normalize([0.01,0.01,0.01],[1,1,1])
image_norm=norm(image_tensor)Resize()
对图像大小进行修改
resize=transforms.Resize((512,512))
image_resize=resize(image_PIL)Compose()
将 transforms操作组合起来
Compose(
ToTensor()
Normalize(mean=[0.01, 0.01, 0.01], std=[1, 1, 1])
Resize(size=(512, 512), interpolation=bilinear, max_size=None, antialias=False)
)RandomCrop()
随机裁剪
random=transforms.RandomCrop(256)
compose=transforms.Compose([
random,
toTensor
])
for i in range(10):
img_crop=compose(image_PIL)
# print(img_crop)
writer.add_image("crop",img_crop,i)
writer.close()transforms的数据操作方法还是很多的,用到再掌握也可以
torchvision数据集
torchvision.datasets中有很多官方数据集,使用直接下载即可
toTensor=transforms.ToTensor()
train_set=torchvision.datasets.CIFAR10(root="../data",train=True,download=False,transform=toTensor)
test_set=torchvision.datasets.CIFAR10(root="../data",train=False,download=False,transform=toTensor)DataLoader

dataset与dataloader的区别
from torch.utils.data import DataLoader
toTensor=transforms.ToTensor()
test_set=torchvision.datasets.CIFAR10(root="../data",train=False,download=False,transform=toTensor)
test_data=DataLoader(test_set,batch_size=4,shuffle=True,num_workers=0,drop_last=False)To Be Continued


